





如果你对链表《第2篇 C++ 数据结构-链表概述》请先阅读前文,我们前一篇已经罗列单链表的类接口清单,本篇会依据接口文件,逐步实现链表的各个函数接口。
我们首先看一下Node类的接口实现,这部分没什么好说的,我本篇都使用C++模板来说,如果你对模板毫无了解的话请自行去补充这方面的知识。
#include "../headers/LinkedList.hh"
//节点类的默认构造函数
template <class T>
Node<T>::Node() : d_data(), d_next(nullptr) {}
//节点类的用户自定义构造函数
template <class T>
Node<T>::Node(T val) : d_data(val), d_next(nullptr) {}
//节点类的析构函数
template <class T>
Node<T>::~Node() {}
//返回节点上的元素实体
template <class T>
const T &Node<T>::elem()
{
return d_data;
}
//返回当前节点的下一个节点的地址
template <class T>
Node<T> *Node<T>::next()
{
return d_next;
}
//输出单个节点的值
template <class R>
std::ostream &operator<<(std::ostream &out, const Node<R> &nod)
{
if (nod.d_next != nullptr)
{
out << nod.elem();
}
return out;
}
单向链表的实现
初始化一个LinkedList的默认构造函数,应该是一个空的链表,LinkedList的头指针d_head应该指向nullptr;如下图所示
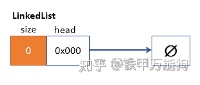
空的链表
1. 构造/析构函数
//构造函数
template <class T>
LinkedList<T>::LinkedList()
: d_head(nullptr), d_last(nullptr), d_mid(nullptr), d_size(0) {}
//构造函数2
template <class T>
LinkedList<T>::LinkedList(size_t n)
: d_head(new Node<T>()), d_last(d_head), d_mid(nullptr), d_size(n)
{
Node<T> *tmp;
for (auto i = 0; i < n; i++)
{
tmp = new Node<T>();
tmp->d_next = nullptr;
d_last->d_next = tmp;
d_last = tmp;
}
}
//析构函数
template <class T>
LinkedList<T>::~LinkedList() { clear(); }
2.首端元素插入操作
在链表首部插入元素存在两种情况
- 1)链表本身是空表,即链表的新节点的next指针会指向nullptr,然后LinkedList对象的头指针(head)会指向新节点

- 2)链表本身已含其他节点
- 此时新节点的next指针先指向LinkedList的head指针指向的节点(当前该节点是第一个节点)。
- 然后,LinkedList的head指针指向新节点.
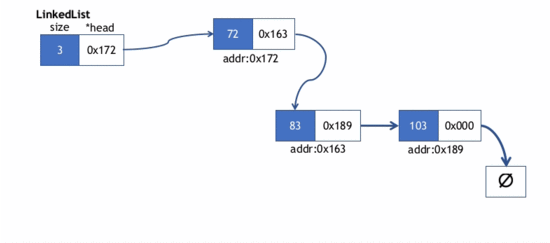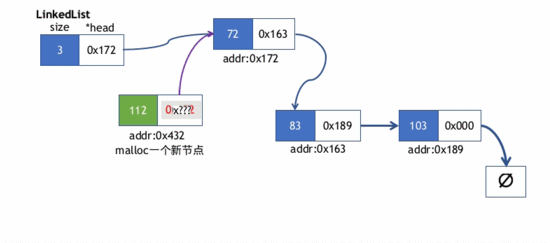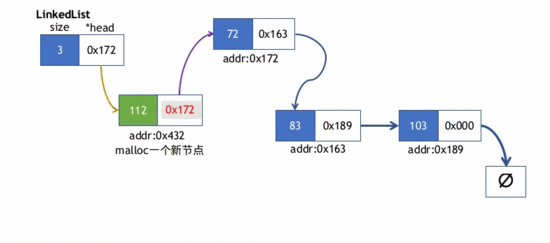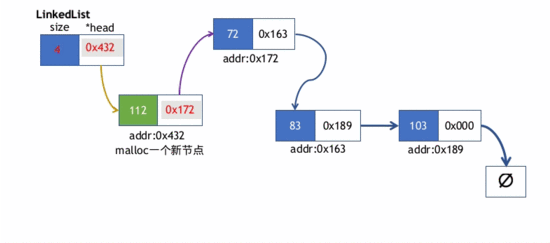
push_head()的实现
//析构函数
template <class T>
LinkedList<T>::~LinkedList() { clear(); }
//表头插入操作
template <class T>
void LinkedList<T>::push_head(T val)
{
//tmp是一个新节点
Node<T> *tmp = new Node<T>(val);
if (d_head == nullptr)
{
tmp->d_next = nullptr;
d_head = tmp;
}
else
{
//首先让新节点指向原来首端元素
tmp->d_next = d_head;
//让LinkedList头指针指向新的元素节点
d_head = tmp;
}
++d_size;
}
3.追加元素操作
我们前文提到,在末端插入元素操作
- 实例化一个Node节点,并在该新节点上拷贝元素实体,由于新节点是“将要”作为链表最后一个元素追加到末端的,因此该节点的next指针需要指向nullptr.
- 注意,我们前一步实例化的节点还是“孤立”的节点,因此我们需要遍历到链表中的最后一个节点,最后一个节点的next指向新创建的节点。整个过程如下动画所示。
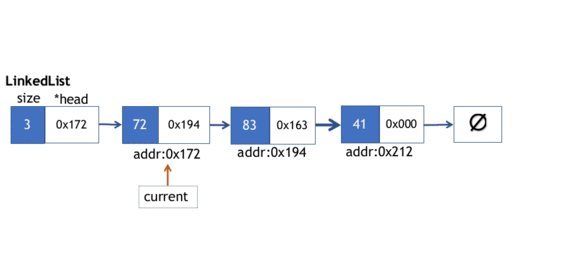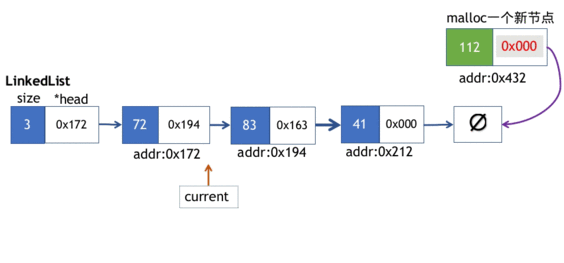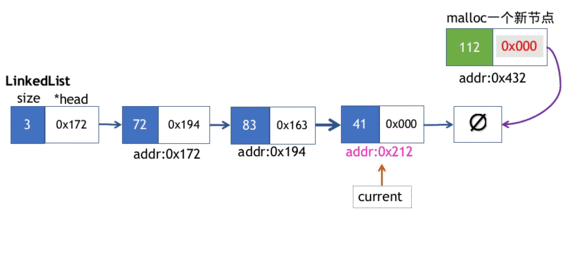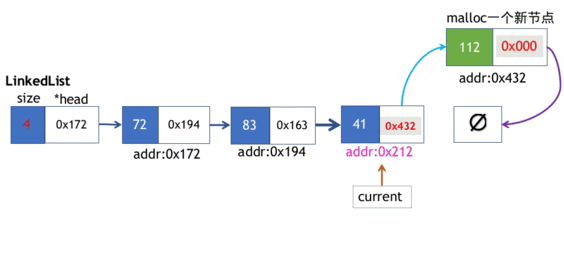
push_back方法实现
//末端插入操作
template <class T>
void LinkedList<T>::push_back(T val)
{
Node<T> *tmp = new Node<T>(val);
//判断链表是否为空
if (d_head == nullptr)
{
tmp->d_next = nullptr;
d_head = tmp;
}
else
{
Node<T> *cur = d_head;
while (cur->d_next != nullptr)
{
cur = cur->d_next;
}
cur->d_next = tmp;
tmp->d_next = nullptr;
}
++d_size;
}
其他静态语言,如C#,Java等,对于尾部插入还有不同的叫法,用的比较多的是“append”,而头部插入也叫“prepend”,除了头部插入和尾部插入之外,的其他位置插入操作,我这里统称insert操作
insert插入操作
该操作同样每次插入前需要将一个临时指针副本偏移到指定索引的位置,需要注意的,如果我们插入的位置是位于索引k(注意k的索引计数从0开始算起),那么我们只遍历到第k-1个节点,终止循环即可。
- 新节点的next指针指向第i个节点的下一个节点
- 第k-i个位置的节点的next指针指向新节点
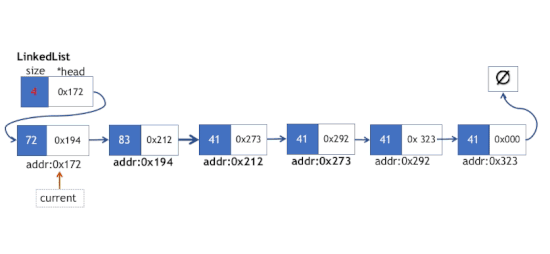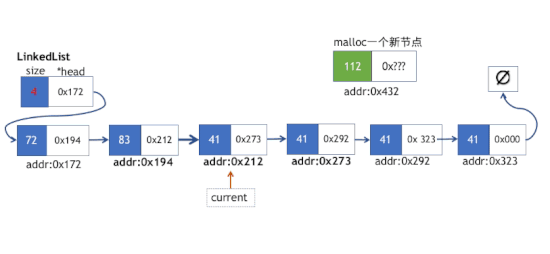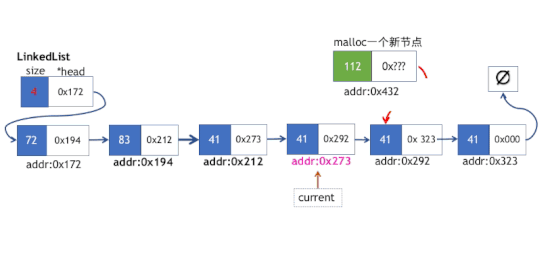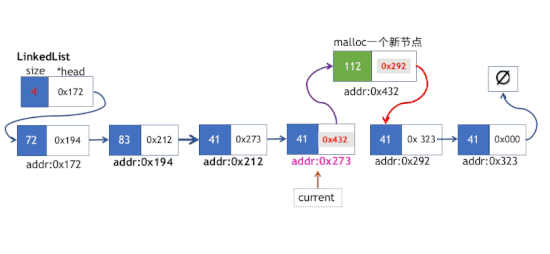
insert方法实现
//中间插入操作
template <class T>
void LinkedList<T>::insert(size_t k, T val){
if (k > d_size){
return;
}
Node<T> *tmp = new Node<T>(val);
if (d_size == 0){
tmp->d_next = nullptr;
d_head = tmp;
}else{
Node<T> *cur = d_head;
size_t i = 0;
while (cur->d_next){
if (i == k - 1){
break;
}
cur = cur->d_next;
i++;
}
tmp->d_next = cur->d_next;
cur->d_next = tmp;
}
++d_size;
}
关于查找节点与删除节点的问题
很多应用场景中,我们需要根据元素的值查找它所在的节点,在删除某个元素中也要用到查找的算法,但我们特别需要注意,例如我们查找的元素值在元素的第k个索引的节点,我们不能遍历到第k个节点,因为对于单向链表来说,一但我们的遍历的指针位于第k个节点时已经无法返回到位于k-1位置的节点,此时我们将位于第k个位置的节点执行delete操作,那么第k-1个位置的节点与第k+1个位置的节点本应要建立的链接关系已经无法建立,那么从第k+1个位置的节点算起的部分与链表就“断链”了,这也是造成链表内存泄漏的重要原因之一。
因此,我们考虑到上面的问题,我们在实现查找算法时,已经要将删除操作的特殊情况优先考虑到查找算法当中,那么只需在查找算法中返回找到元素值所在节点的前一个节点即可。
search方法实现
//按值查找所在节点的前一个节点
template <class T>
Node<T> *LinkedList<T>::_search(const T &val)
{
if (d_head != nullptr)
{
Node<T> *prev = d_head;
while (prev->d_next && val != prev->d_next->d_data)
{
prev = prev->d_next;
}
return prev;
}
return nullptr;
}
上面的方法是私有的,那么如果要想常规的查找应用提供一个通用版本的查找函数接口,怎么办呢?easy job,我们可以下面这样实现。
//按元素值查找元素的公开查找算法
template <class T>
Node<T> *LinkedList<T>::search(const T &val)
{
Node<T> *nod = _search(val);
if (val)
{
return nod->d_next;
}
return nullptr;
}
6.按值查找需要删除的节点
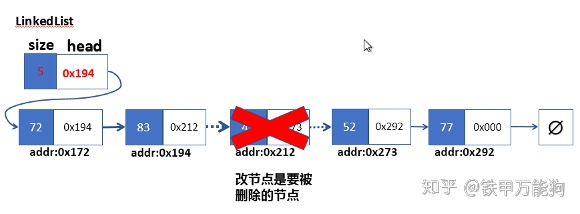
该操作,我们只要调用我们私有版本的_search方法找到目标节点的前一个节点。在删除节点前,我们要将查找到的节点(位于k位置)的前一个节点的next指针指向k+1位置的节点。,最后放心将查找的节点删除即可。
下面是删除链表的中间某个节点的过程
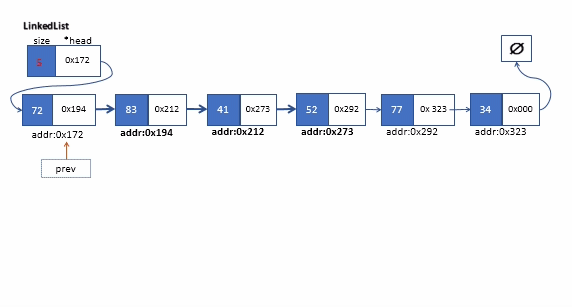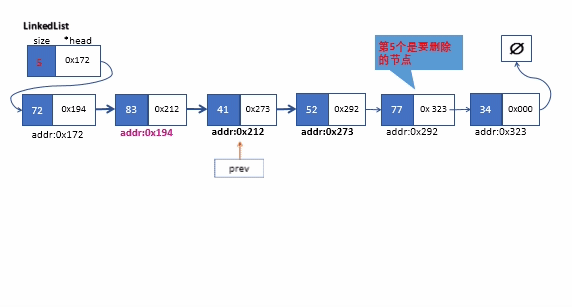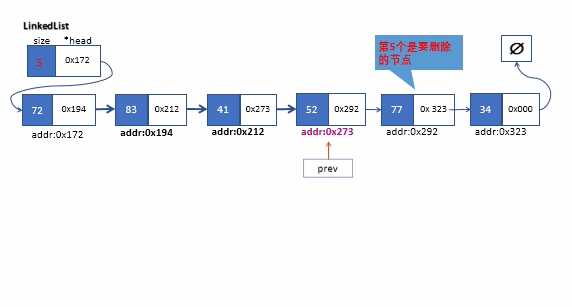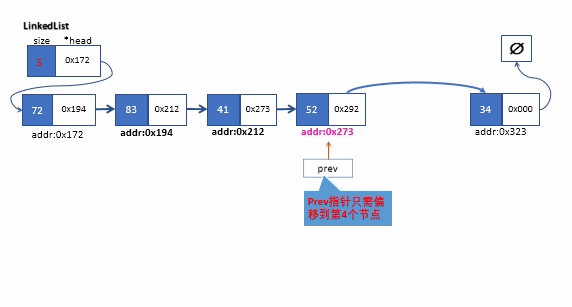
remove方法实现(按值查找)
//按值查找要删除的节点
template <class T>
void LinkedList<T>::remove(const T &val)
{
//按值查找所在节点的前一个节点
Node<T> *prev = _search(val);
if (prev != nullptr)
{
//要删除的节点
Node<T> *cur = prev->d_next;
prev->d_next = cur->d_next;
delete cur;
}
}
清空链表操作
清空链表,我们从头链表的头部元素一直遍历到链表的末端,遍历过程中,在每次循环偏移链表的头指针时,我们需要一个临时指针变量来缓存前一个节点然后对其执行内存释放操作。链表清空操作如下图所示。
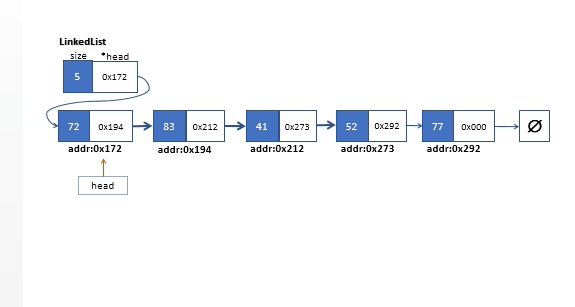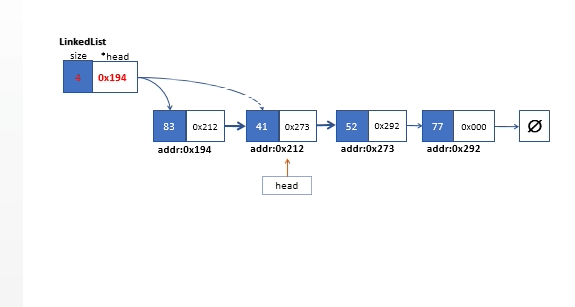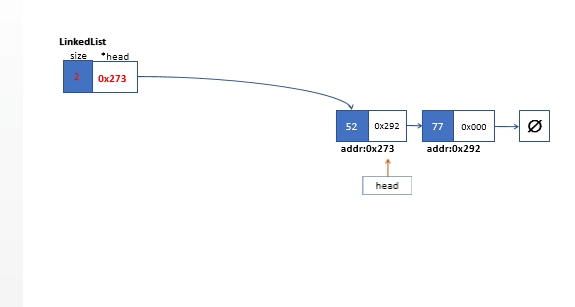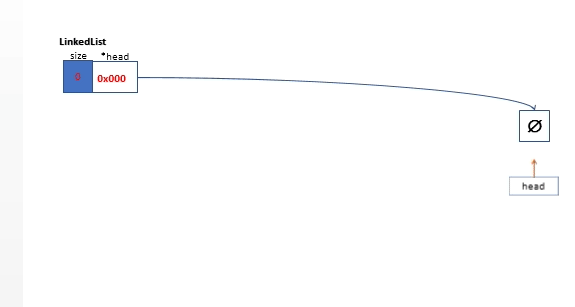
//清空整个链表
template <class T>
void LinkedList<T>::clear()
{
Node<T> *cur;
while (d_head)
{
cur = d_head;
d_head = d_head->d_next;
delete cur;
cur = nullptr;
}
}
顺序反转操作
反转顺序操作应该是整个基础链表中的难点,其实该操作中用到遍历操作是毫无疑问,其实就是把每个节点的next指针的方向对掉,原本每个节点指向下一个后继节点,现在分别需要指向它们的前一个。如下图所示。

那边实现该算法算是本篇基础链表的难点,我们可以稍微通过下图来解释一下算法
首先,我们需要三个临时Node<T>类型的指针,并且我们将三个指针分别初始指向链表三个不同的节点。
- pre是前任节点的指针,指向末端节点的空指针nullptr
- cur是当前节点的指针,指向首个节点
- sor是后继节点的指针,指向链表中的第二个节点
在遍历过程中,注意我们始终以指向后继节点的指针sor为“主动变量”在判断sor未指向未端节点之前,pre指针和cur指针完成两件事
- cur指针所在的节点的next指针指向pre所在节点的指针,即完成链接顺序对调
- 之后cur指针和pre指针继续前进分别指向后续需要对调链接顺序的节点。
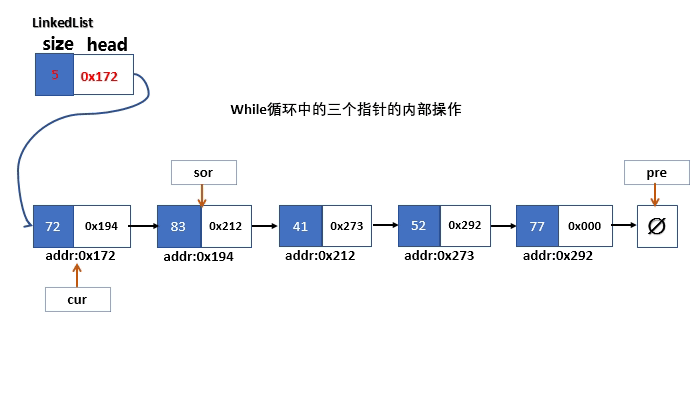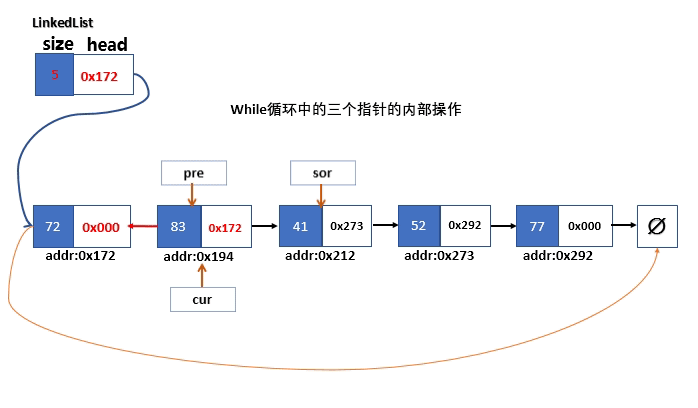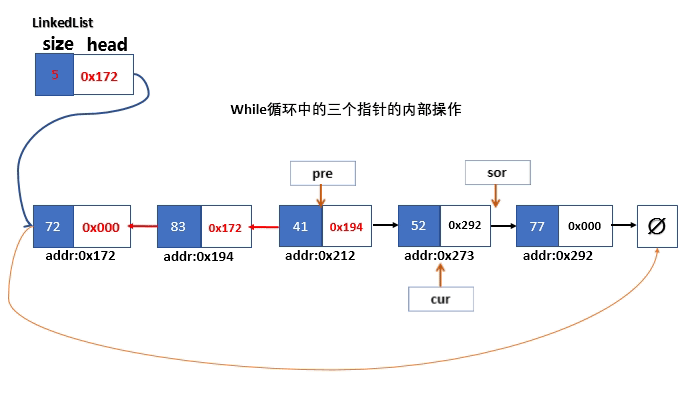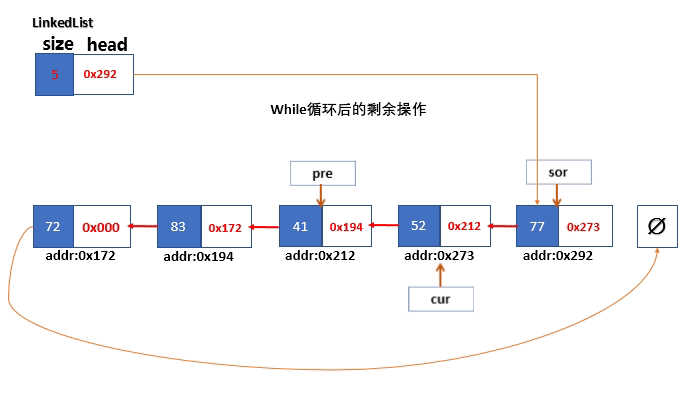
当sor指针到达了末端节点之后,此时程序已经结束了遍历,此时的状态,cur指针指向倒数第二个节点,pre指针指向倒数第三个节点。
- cur指针所在的节点的next指针指向pre指针所在的指针。
- 链表的头指针指向最后一个指针
reverse方法实现
//反转链表顺序
template <class T>
void LinkedList<T>::reverse()
{
Node<T> *pre, *cur, *sor;
pre = nullptr;
cur = d_head;
sor = d_head->d_next;
while (sor->d_next)
{
cur->d_next = pre;
pre = cur;
cur = sor;
sor = sor->d_next;
}
cur->d_next = pre;
d_head = sor;
d_head->d_next = cur;
}
获取末端最后一个元素
//获取最后一个节点
template <class T>
T LinkedList<T>::last()
{
Node<T> *cur = d_head;
while (cur->d_next)
{
cur = cur->d_next;
}
return cur->d_data;
}
打印链表的operator<<函数重载
//打印链表
template <class R>
std::ostream &operator<<(std::ostream &out, const LinkedList<R> &list)
{
Node<R> *cur = list.d_head;
while (cur != nullptr)
{
out << cur->elem() << "➔ ";
cur = cur->next();
}
if (cur == nullptr)
{
out << "Ø";
}
out << std::endl;
return out;
}
operator[]访问操作符
//索引访问
template <class T>
T LinkedList<T>::operator[](size_t k)
{
Node<T> *cur = d_head;
size_t i = 0;
if (d_head == nullptr)
{
return;
}
else
{
while (cur->d_next)
{
if (i == k)
{
break;
}
cur = cur->d_next;
i++;
}
return cur->d_data;
}
}
last()方法
//获取最后一个节点
template <class T>
T LinkedList<T>::last()
{
Node<T> *cur = d_head;
while (cur->d_next)
{
cur = cur->d_next;
}
return cur->d_data;
}
获取中点元素
这个其实用到了两个指针,一个叫快速指针,一个叫慢速指针。在整个遍历过程中,快速指针到达末端元素,此时慢速指针正好位于中间节点。很多对办拆分链表基本上都需要用到这个技术。
//获取中间节点
template <class T>
Node<T> *LinkedList<T>::mid_node()
{
if (d_head != nullptr)
{
Node<T> *s_ptr = d_head;
Node<T> *f_ptr = d_head;
while (f_ptr != nullptr && f_ptr->d_next != nullptr)
{
f_ptr = f_ptr->d_next->d_next;
s_ptr = s_ptr->d_next;
}
return s_ptr;
}
}
//获取中间节点,并返回传入的变量的引用
template <class T>
Node<T> *LinkedList<T>::mid_node(size_t &k)
{
if (d_head != nullptr)
{
Node<T> *s_ptr = d_head;
Node<T> *f_ptr = d_head;
while (f_ptr != nullptr && f_ptr->d_next != nullptr)
{
f_ptr = f_ptr->d_next->d_next;
s_ptr = s_ptr->d_next;
k++;
}
return s_ptr;
}
}
实现迭代接口
这个实现了LinkedList的迭代接口,由于迭代接口基本上不会更改,所以我将Iterator的实现写在LinkedList接口的内部。
class LinkedList{
....
class Iterator;
Iterator begin() { return Iterator(d_head); }
Iterator end(){
return Iterator(nullptr);
}
class Iterator{
private:
const Node<T> *d_cur; //当前节点
public:
Iterator() noexcept : d_current(d_head) {}
Iterator(const Node<T> *nod) noexcept : d_cur(nod) {}
Iterator &operator=(Node<T> *nod){
this->d_cur = nod;
return *this;
}
Iterator &operator++(){
if (d_cur){
d_cur = d_cur->d_next;
return *this;
}
}
Iterator &operator++(int){
Iterator iter = *this;
++*this;
return iter;
}
bool operator!=(const Iterator &iter){
return d_cur != iter.d_cur;
}
T operator*(){
return d_cur->d_data;
}
};
}
小结
剩下来的部分就是接口测试,我打算留到下一篇在优化前和优化后做性能测试对比,因为上面说的都是链表的常规实现,只能算是一个入门的链表实现,其实链表可以做到时间复杂度缩减到最低。不论"增/删/改/查"的,它们的痛点就是那O(n)的遍历操作。这些问题,我们会留到下一篇再说。
读后有收获,可以给笔者打赏杯咖啡。
















 1125
1125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









