







前言
在爬虫开发过程中,经常会遇到验证码的情况,这是反爬过程中相当有门槛的措施,破解成本非常高,需要深度学习、JS 逆向等相关的经验,而且成功率还不一定很高。即使破解成功,如果目标网站换了验证码生成的方法或算法,那么费了九牛二虎之力才成功破解的工作将前功尽弃。因此,破解验证码这种反人类的事情,真的不适合新手。
那么,用什么方法才能够避免验证码,从而完成登录呢?如果一个方法不行(Not working),我们不要死磕(Stick to it),我们可以尝试采用绕开的方式(Workaround)。而本文将介绍一种简单可行的绕开验证码的办法,并且实践证明是非常有效的。目前关于这种方法的网上资料并不多,本文将简单介绍一下,权当抛砖引玉。
整体思路
现在的网站一般都不要求用户每次访问时都重复输入信息登录,而是允许用户二次登录的时候能够直接通过登录校验,直接访问登录后的内容。那么这是如何实现的呢?网站一般是将一些加密信息存在浏览器上,类似于给了你一张有过期时间的房卡,你每次拿着这张房卡,通过的时候扫一下就进去了。这些加密信息绝大部分是以 Cookie 形式存在的,上面存有 Session 信息,而访问的时候 Cookie 与浏览器上的 Session 作比对,如果成功就能正常访问登录后的信息。如果您对这种机制不了解,请参考 这篇文章。而我们恰巧就是利用了这种机制来实现绕开验证码的操作,如下图所示。
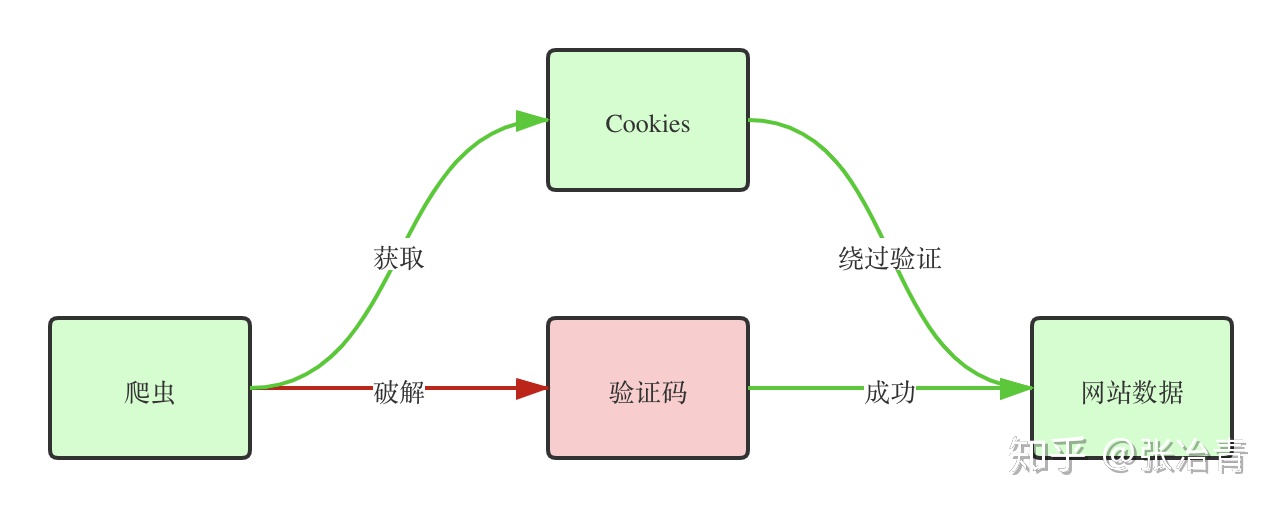
因此,我们的思路不是想方设法的破解验证码,例如利用打码平台,或者自研深度学习算法之类的,而是利用 Cookie 这个简单的浏览器储存方式来绕开登录验证码,从而达到我们抓取登录后数据的目的。
下面我们来介绍一下具体的实现方式。整体的实现思路如下图。
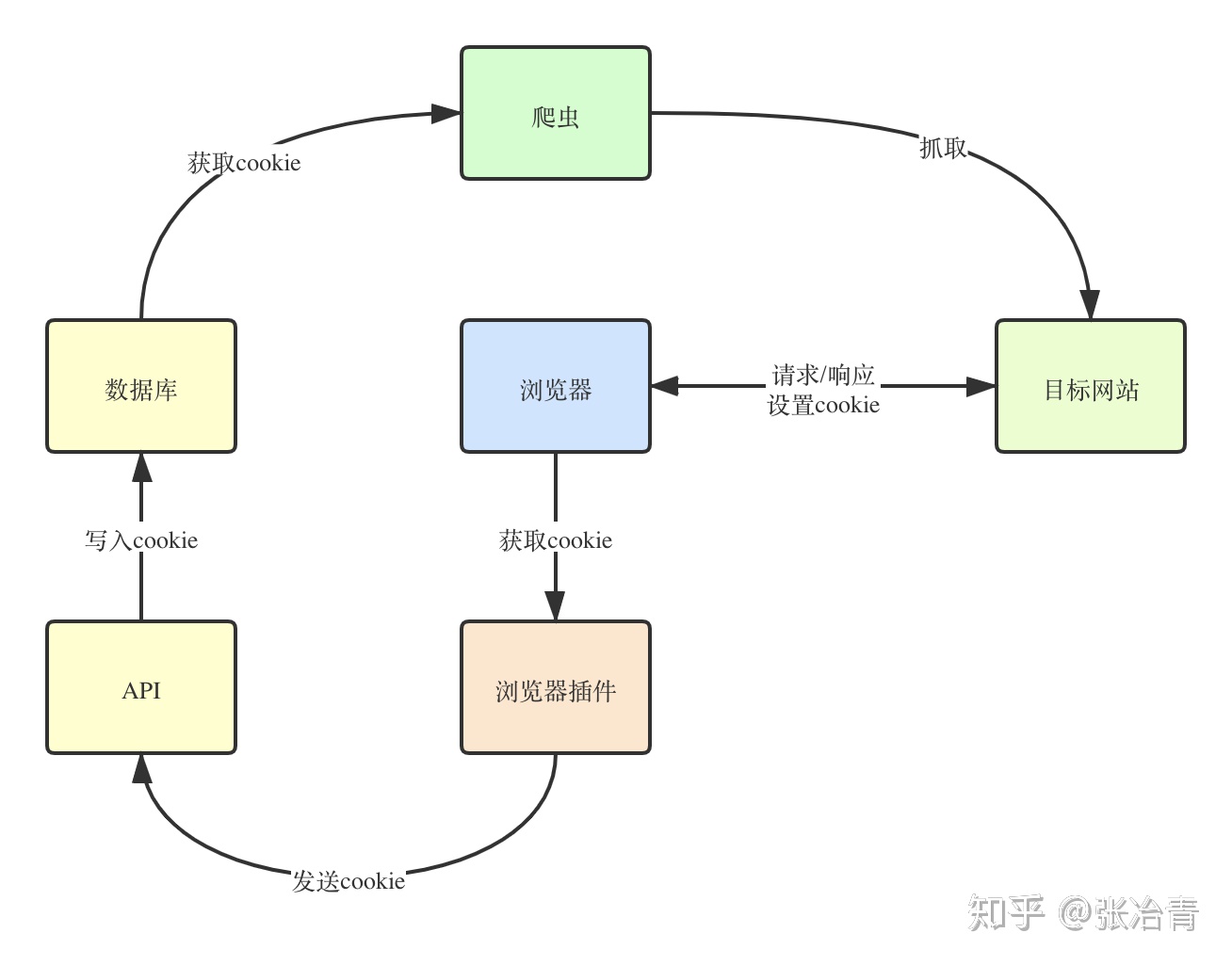
简单来说,步骤如下:
- 我们通过浏览器获取目标网站的 Cookie(输入验证码登录后);
- 然后利用浏览器插件从浏览器中获取对应目标网站的 Cookie;
- 浏览器插件发送获取的 Cookie 到后台 API;
- API 将接收到的 Cookie 写入数据库中;
- 爬虫从数据库中获取 Cookie,并在每次请求时带上 Cookie。
这样,我们就完成了一个抓取登录后网站信息的流程。其中,黄色部分的数据库和 API 都可以换做本地文件,当然为了生产环境可用,我们还是推荐用 API + 数据库的方式。
浏览器插件
简介
浏览器插件主要是为了扩展浏览器功能,让用户在浏览器上实现一些比较实用功能的工具。本文将采用的是 Chrome 浏览器插件,因为开发比较简单,使用人数也较多。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1746
1746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









