






一般认为正则表达式是比较难写的,我也这么认为,不过在工作上用的其实不多,正则表达式在基于文本的linux上用处是非常大的,而在基于对象的Python上其实没有什么用途,所以我们没有必要太深入的去学习正则表达式,学一个万能公式够用就行。
我这里所用的万能公式其实就是分组,举个例子,像这样的一段html代码,
‘’如何去匹配标签里面的内容那?最简单的一个办法是字符串切片
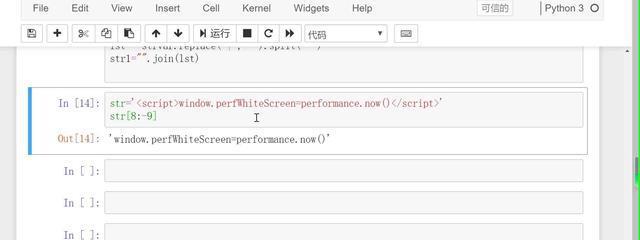
但是字符串切片相当于把代码写死了,对这个字符串可以这样切,对其他的字符串可能就不行了,所以有时候需要用正则找一些通用的公式,我们这里可以从'<>'上找思路,比如可以这样写

这个写法就是分组,稍微给大家讲解一些代码
import restr=''res=re.findall('\>(.*?)\(.*?)\
正则表达式中‘()’代表分组,一旦出现括号先优先匹配括号内的内容,也就说结果中只包含括号内的内容,这有什么好处那?好处就是我们在书写正则时不必再考虑什么开头,什么结尾,只需考虑要匹配的内容就行,这就是我所说的万能公式。
再举一个例子,现在我们需要匹配几个网址的域名,
‘ww.baidu.com,site.sougou.com,ftp.pku.com’














 485
485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









