






在上节教你阅读 Cpython 的源码(一)中,我们从编写Python到执行代码的过程中看到Python语法和其内存管理机制。
在本节,我们将从代码层面去讨论 ,Python的编译过程。
调用Python二进制文件可以通过以下五种方式:
1.使用-c和Python命令运行单个命令
2.使用-m和模块名称启动模块
3.使用文件名运行文件
4.使用shell管道运行stdin输入
5.启动REPL并一次执行一个命令
整个运行过程你可以通过检查下面三个源文件进行了解:
1.Programs/python.c是一个简单的入口文件。
2.Modules/main.c汇集加载配置,执行代码和清理内存整个过程的代码文件。
3.Python/initconfig.c从系统环境加载配置,并将其与任何命令行标志合并。
此图显示了如何调用每个函数:
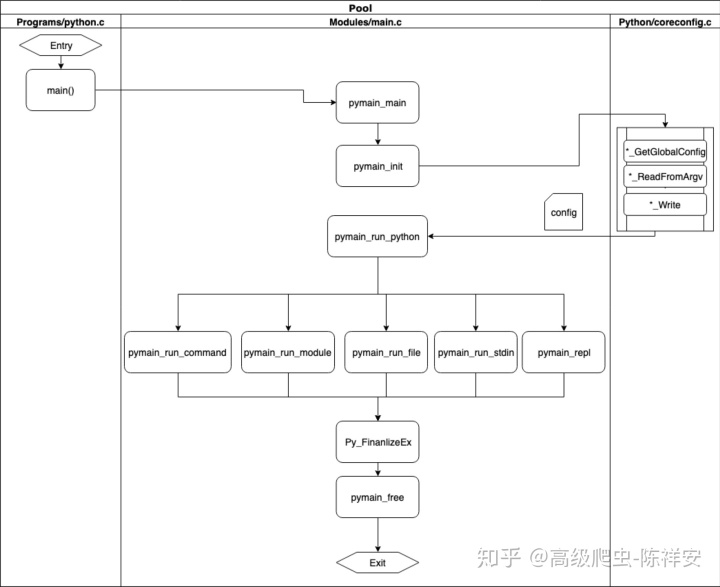
执行模式由配置确定。
CPython源代码样式:
与Python代码的PEP8样式指南类似,CPython C代码有一个官方样式指南,最初于2001年设计并针对现代版本进行了更新。
这里有一些命名标准方便你调试跟踪源代码:
- 对公共函数使用Py前缀,静态函数不使用。Py_前缀保留用于
Py_FatalError等全局服务例程。特定的对象(如特定的对象类型API)使用较长的前缀,例如PyString_用于字符串函数。 - 公众函数和变量,使用首写字母大写,单词之间下划线分割的形式,
例如:PyObject_GetAttr,Py_BuildValue,PyExc_TypeError。 - 有时,加载器必须能够看到内置函数。
我们使用_Py前缀,例如_PyObject_Dump。 - 宏应具有混合字母前缀,首字母大写,例如
PyString_AS_STRING,Py_PRINT_RAW。
创建运行环境的配置
通过上图可以看到,在执行Python代码之前,首先会建立配置。在文件Include/cpython/initconfig.h中名为PyConfig的对象会定义一个配置的数据结构。
配置数据结构包括以下内容:
- 各种模式的运行时标志,如调试和优化模式
- 执行模式,例如是否传递了文件名,提供了stdin或模块名称
- 扩展选项,由-X 指定
- 运行时设置的环境变量
配置数据主要是CPython在运行时用于启用和禁用各种功能。Python还附带了几个命令行界面选项。
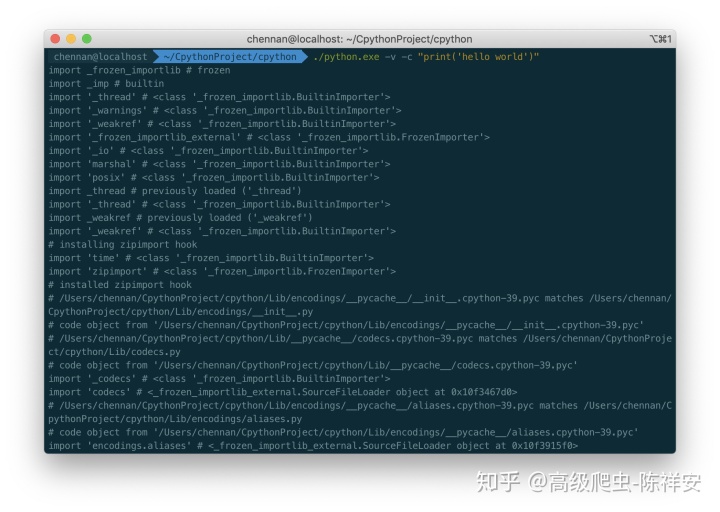
在Python中,你可以使用-v标志启用详细模式。在详细模式下,Python将在加载模块时将消息打印到屏幕:
$ ./python.exe -v -c "print('hello world')"
# installing zipimport hook
import zipimport # builtin
# installed zipimport hook
...
你可以在PyConfig的struct中的Include/cpython/initconfig.h中看到此标志的定义:
/* --- PyConfig ---------------------------------------------- */
typedef struct {
int _config_version; /* Internal configuration version,
used for ABI compatibility */
int _config_init; /* _PyConfigInitEnum value */
...
/* If greater than 0, enable the verbose mode: print a message each time a
module is initialized, showing the place (filename or built-in module)
from which it is loaded.
If greater or equal to 2, print a message for each file that is checked
for when searching for a module. Also provides information on module
cleanup at exit.
Incremented by the -v option. Set by the PYTHONVERBOSE environment
variable. If set to -1 (default), inherit Py_VerboseFlag value. */
int verbose;
在Python/initconfig.c中,建立了从环境变量和运行时命令行标志读取设置的逻辑。
在config_read_env_vars函数中,读取环境变量并用于为配置设置分配值:
static PyStatus
config_read_env_vars(PyConfig *config)
{
PyStatus status;
int use_env = config->use_environment;
/* 获取环境变量 */
_Py_get_env_flag(use_env, &config->parser_debug, "PYTHONDEBUG");
_Py_get_env_flag(use_env, &config->verbose, "PYTHONVERBOSE");
_Py_get_env_flag(use_env, &config->optimization_level, "PYTHONOPTIMIZE");
_Py_get_env_flag(use_env, &config->inspect, "PYTHONINSPECT");
对于详细设置,你可以看到如果PYTHONVERBOSE存在,PYTHONVERBOSE的值用于设置&config-> verbose的值,如果环境变量不存在,则将保留默认值-1。
然后再次在initconfig.c中的config_parse_cmdline函数中,用命令行标志来设置值:
static PyStatus
config_parse_cmdline(PyConfig *config, PyWideStringList *warnoptions,
Py_ssize_t *opt_index)
{
...
switch (c) {
...
case 'v':
config->verbose++;
break;
...
/* This space reserved for other options */
default:
/* unknown argument: parsing failed */
config_usage(1, program);
return _PyStatus_EXIT(2);
}
} while (1);
此值之后由_Py_GetGlobalVariablesAsDict函数复制到全局变量Py_VerboseFlag。
在Python中,可以使用具名元组类型的对象sys.flags访问运行时标志,如详细模式,安静模式。-X标志在sys._xoptions字典中都可用。
$ ./python.exe -X dev -q
>>> import sys
>>> sys.flags
sys.flags(debug=0, inspect=0, interactive=0, optimize=0, dont_write_bytecode=0,
no_user_site=0, no_site=0, ignore_environment=0, verbose=0, bytes_warning=0,
quiet=1, hash_randomization=1, isolated=0, dev_mode=True, utf8_mode=0)
>>> sys._xoptions
{'dev': True}
除了initconfig.h中的运行时配置外,还有构建配置,它位于根文件夹中的pyconfig.h内。
此文件在构建过程的配置步骤中动态创建,或由Visual Studio for Windows系统动态创建。
可以通过运行以下命令查看构建配置:
$ ./python.exe -m sysconfig
读取文件/输入
一旦CPython具有运行时配置和命令行参数,就可以确定它需要执行的内容了。
此任务由Modules/main.c中的pymain_main函数处理。
根据新创建的配置实例,CPython现在将执行通过多个选项提供的代码。
通过-c输入
最简单的是为CPython提供一个带-c选项的命令和一个带引号的Python代码。
例如:
$ ./python.exe -c "print('hi')"
hi
下图是整个过程的流程图
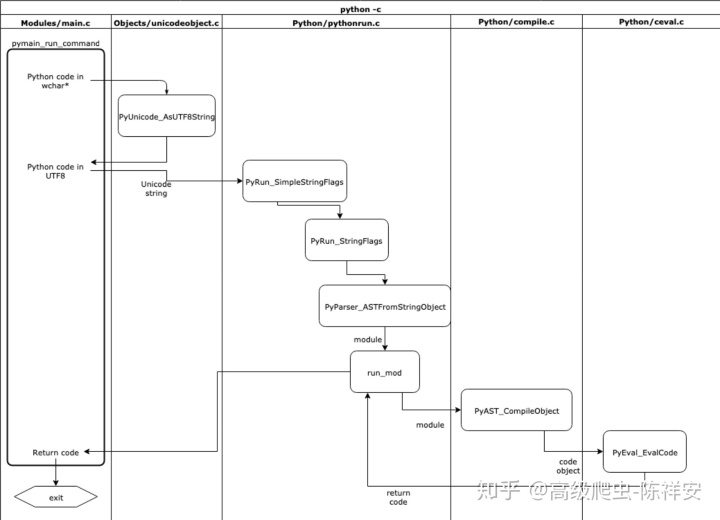
首先,在modules/main.c中执行pymain_run_command函数,将在-c中传递的命令作为C程序中wchar_t *的参数。
wchar_t*类型通常被用作Cpython中Unicode的低级存储数据类型,因为该类型的大小可以存储utf8字符。
将wchar_t *转换为Python字符串时,Objects/unicodetype.c文件有一个辅助函数PyUnicode_FromWideChar,它会返回一个PyObject,其类型为str。然后,通过PyUnicode_AsUTF8String,完成对UTF8的编码,并将Python中的str对象转换为Python字节类型。
完成后,pymain_run_command会将Python字节对象传递给PyRun_SimpleStringFlags执行,但首先会通过 PyBytes_AsString将字节对象再次转换为str类型。
static int
pymain_run_command(wchar_t *command, PyCompilerFlags *cf)
{
PyObject *unicode, *bytes;
int ret;
unicode = PyUnicode_FromWideChar(command, -1);
if (unicode == NULL) {
goto error;
}
if (PySys_Audit("cpython.run_command", "O", unicode) < 0) {
return pymain_exit_err_print();
}
bytes = PyUnicode_AsUTF8String(unicode);
Py_DECREF(unicode);
if (bytes == NULL) {
goto error;
}
ret = PyRun_SimpleStringFlags(PyBytes_AsString(bytes), cf);
Py_DECREF(bytes);
return (ret != 0);
error:
PySys_WriteStderr("Unable to decode the command from the command line:n");
return pymain_exit_err_print();
}
将wchar_t *转换为Unicode,字节,然后转换为字符串大致相当于以下内容:
unicode = str(command)
bytes_ = bytes(unicode.encode('utf8'))
# call PyRun_SimpleStringFlags with bytes_
PyRun_SimpleStringFlags函数是Python/pythonrun.c的一部分。它的目的是将这个简单的命令转换为Python模块,然后将其发送以执行。由于Python模块需要将__main__作为独立模块执行,因此它会自动创建。
int
PyRun_SimpleStringFlags(const char *command, PyCompilerFlags *flags)
{
PyObject *m, *d, *v;
m = PyImport_AddModule("__main__"); #创建__main__模块
if (m == NULL)
return -1;
d = PyModule_GetDict(m);
v = PyRun_StringFlags(command, Py_file_input, d, d, flags);
if (v == NULL) {
PyErr_Print();
return -1;
}
Py_DECREF(v);
return 0;
}
一旦PyRun_SimpleStringFlags创建了一个模块和一个字典,它就会调用PyRun_StringFlags函数,它会创建一个伪文件名,然后调用Python解析器从字符串创建一个AST并返回一个模块,mod。
你将在下一节中深入研究AST和Parser代码。
通过-m输入
执行 Python 命令的另一个方法,通过使用 -m 然后知道一个模块名。一个典型的例子是python -m unittest,运行一个unittest测试模块。使用-m标志意味着在模块包中,你想要执行__main__中的任何内容。它还意味着你要在sys.path中搜索指定的模块。所以,使用这种搜索机制之后,你不需要去记忆unittest模块它位于那个位置。
为什么会这样呢?接下来就让我们一起看看原因。
在Modules/main.c中,当使用-m标志运行命令行时,它会调用pymain_run_module函数,并将传入模块的名称作为modname参数传递。
然后CPython将导入标准库模块runpy,并通过PyObject_Call函数执行它。导入模块的操作是在函数PyImport_ImportModule进行的。
static int
pymain_run_module(const wchar_t *modname, int set_argv0)
{
PyObject *module, *runpy, *runmodule, *runargs, *result;
runpy = PyImport_ImportModule("runpy");
...
runmodule = PyObject_GetAttrString(runpy, "_run_module_as_main");
...
module = PyUnicode_FromWideChar(modname, wcslen(modname));
...
runargs = Py_BuildValue("(Oi)", module, set_argv0);
...
result = PyObject_Call(runmodule, runargs, NULL);
...
if (result == NULL) {
return pymain_exit_err_print();
}
Py_DECREF(result);
return 0;
}
在这个函数中,您还将看到另外两个C API函数:PyObject_Call和PyObject_GetAttrString。
因为PyImport_ImportModule返回一个核心对象类型PyObject *,所以需要调用特殊函数来获取属性并调用它。
在Python中,如果你需要调用某个函数属性,你可以使用getattr()函数。类似的,在C API中,它将调用Objects/object.c文件中的PyObject_GetAttrString方法。如果你要在python中运行一个callable类型的对象,你需要使用括号运行它,或者调用其__call__()属性。在Objects/object.c中对__call__()进行了实现。
hi = "hi!"
hi.upper() == hi.upper.__call__() # this is the same
runpy模块就在Lib/runpy.py,它是纯Python写的。
执行python -m <module>相当于运行python -m runpy <module>。
创建runpy模块是为了抽象在操作系统上定位和执行模块的过程。
runpy做了一些事情来运行目标模块:
- 为你提供的模块名称调用
__import __() - 将
__name__(模块名称)设置为名为__main__的命名空间 - 在
__main__命名空间内执行该模块
runpy模块还支持执行目录和zip文件。
通过文件名输入
如果Python命令的第一个参数是文件名,例如,python test.py。Cpython会打开一个文件的句柄,类似我们在Python中使用open(),并将句柄传递给Python/pythonrun.c. 文件里的PyRun_SimpleFileExFlags()。
这里有三种方式:
1.如果文件后缀是.pyc,就会调用run_pyc_file()。
2.如果文件后缀是.py,将调用PyRun_FileExFlags()。
3.如果文件路径是stdin,用户运行了命令| python会将stdin视为文件句柄并运行PyRun_FileExFlags()。
下面是上述过程的C代码
int
PyRun_SimpleFileExFlags(FILE *fp, const char *filename, int closeit,
PyCompilerFlags *flags)
{
...
m = PyImport_AddModule("__main__");
...
if (maybe_pyc_file(fp, filename, ext, closeit)) {
...
v = run_pyc_file(pyc_fp, filename, d, d, flags);
} else {
/* When running from stdin, leave __main__.__loader__ alone */
if (strcmp(filename, "<stdin>") != 0 &&
set_main_loader(d, filename, "SourceFileLoader") < 0) {
fprintf(stderr, "python: failed to set __main__.__loader__n");
ret = -1;
goto done;
}
v = PyRun_FileExFlags(fp, filename, Py_file_input, d, d,
closeit, flags);
}
...
return ret;
}
使用PyRun_FileExFlags()通过文件输入
对于使用stdin和脚本文件方式,CPython会将文件句柄传递给位于pythonrun.c文件中的PyRun_FileExFlags()。PyRun_FileExFlags()的目的类似于用于-c输入PyRun_SimpleStringFlags(),Cpython会把文件句柄加载到PyParser_ASTFromFileObject()中。
我们将在下一节介绍Parser和AST模块
因为这是一个完整的脚本,所以它不用像使用-c的方式需要通过PyImport_AddModule("__main__")创建__main__模块。
与PyRun_SimpleStringFlags相同,一旦PyRun_FileExFlags()从文件创建了一个Python模块,它就会将它发送到run_mod()来执行。
run_mod()可以在Python/pythonrun.c中找到,并将模块发送到AST以编译成代码对象,代码对象是用于存储字节码操作的格式,并保存到.pyc文件中。
C代码片段
static PyObject *
run_mod(mod_ty mod, PyObject *filename, PyObject *globals, PyObject *locals,
PyCompilerFlags *flags, PyArena *arena)
{
PyCodeObject *co;
PyObject *v;
co = PyAST_CompileObject(mod, filename, flags, -1, arena);
if (co == NULL)
return NULL;
if (PySys_Audit("exec", "O", co) < 0) {
Py_DECREF(co);
return NULL;
}
v = run_eval_code_obj(co, globals, locals);
Py_DECREF(co);
return v;
}
我们将在下一节中介绍CPython编译器和字节码。
对run_eval_code_obj()的调用是一个简单的包装函数,然后它会调用Python/eval.c文件中的PyEval_EvalCode()函数。PyEval_EvalCode()函数是CPython的主要评估循环,它会迭代每个字节码语句并在本地机器上执行它。
使用run_pyc_file() 通过编译字节码输入
在PyRun_SimpleFileExFlags()中,有一个判断子句为用户提供了.pyc文件的文件路径。如果文件路径以.pyc结尾,则不是将文件作为纯文本文件加载并解析它,它会假定.pyc文件的内容是字节码,并保存到磁盘中。
文件Python/pythonrun.c中的run_py_file()方法,使用文件句柄从.pyc文件中编组(marshals)代码对象。编组(Marshaling)是一个技术术语,作用是将文件内容复制到内存中并将其转换为特定的数据结构。磁盘上的代码对象数据结构是CPython编译器缓存已编译代码的方式,因此每次调用脚本时都不需要解析它。
C代码
static PyObject *
run_pyc_file(FILE *fp, const char *filename, PyObject *globals,
PyObject *locals, PyCompilerFlags *flags)
{
PyCodeObject *co;
PyObject *v;
...
v = PyMarshal_ReadLastObjectFromFile(fp);
...
if (v == NULL || !PyCode_Check(v)) {
Py_XDECREF(v);
PyErr_SetString(PyExc_RuntimeError,
"Bad code object in .pyc file");
goto error;
}
fclose(fp);
co = (PyCodeObject *)v;
v = run_eval_code_obj(co, globals, locals);
if (v && flags)
flags->cf_flags |= (co->co_flags & PyCF_MASK);
Py_DECREF(co);
return v;
}
一旦代码对象被封送到内存,它就被发送到run_eval_code_obj(),它会调用Python/ceval.c来执行代码。
词法分析(Lexing)和句法分析(Parsing)
在阅读和执行 Python 文件的过程中,我们深入了解了解析器和AST模块,并对函数PyParser_ASTFromFileObject()函数进行了调用。
我们继续看Python/pythonrun.c,该文件的PyParser_ASTFromFileObject()方法将拿到一个文件句柄,编译器标志和PyArena实例,并使用PyParser_ParseFileObject()将文件对象转换为节点对象。
节点对象将使用AST函数PyAST_FromNodeObject转换为模块。
C代码
mod_ty
PyParser_ASTFromFileObject(FILE *fp, PyObject *filename, const char* enc,
int start, const char *ps1,
const char *ps2, PyCompilerFlags *flags, int *errcode,
PyArena *arena)
{
...
node *n = PyParser_ParseFileObject(fp, filename, enc,
&_PyParser_Grammar,
start, ps1, ps2, &err, &iflags);
...
if (n) {
flags->cf_flags |= iflags & PyCF_MASK;
mod = PyAST_FromNodeObject(n, flags, filename, arena);
PyNode_Free(n);
...
return mod;
}
谈到了PyParser_ParseFileObject()函数,我们需要切换到Parser/parsetok.c文件以及谈谈CPython解释器的解析器-标记化器阶段。
此函数有两个重要任务:
1.在Parser/tokenizer.c中使用PyTokenizer_FromFile()实例化标记化器状态tok_state结构体。
2.使用Parser/parsetok.c中的parsetok()将标记(tokens)转换为具体的解析树(节点列表)。
node *
PyParser_ParseFileObject(FILE *fp, PyObject *filename,
const char *enc, grammar *g, int start,
const char *ps1, const char *ps2,
perrdetail *err_ret, int *flags)
{
struct tok_state *tok;
...
if ((tok = PyTokenizer_FromFile(fp, enc, ps1, ps2)) == NULL) {
err_ret->error = E_NOMEM;
return NULL;
}
...
return parsetok(tok, g, start, err_ret, flags);
}
tok_state(在Parser/tokenizer.h中定义)是存储由tokenizer生成的所有临时数据的数据结构。它被返回到解析器-标记器(parser-tokenizer),因为parsetok()需要数据结构来开发具体的语法树。
在parsetok()的内部,他会调用结构体tok_state,在循环中调用tok_get(),直到文件耗尽并且找不到更多的标记(tokens)为止。tok_get()位于Parser/tokenizer.c文件,其实为类型迭代器(iterator),它将继续返回解析树中的下一个token。
tok_get()是整个CPython代码库中最复杂的函数之一。它有超过640行的代码,包括数十年的边缘案例,以及新语言功能和语法。
其中一个比较简单的例子是将换行符转换为NEWLINE标记的部分:
static int
tok_get(struct tok_state *tok, char **p_start, char **p_end)
{
...
/* Newline */
if (c == 'n') {
tok->atbol = 1;
if (blankline || tok->level > 0) {
goto nextline;
}
*p_start = tok->start;
*p_end = tok->cur - 1; /* Leave 'n' out of the string */
tok->cont_line = 0;
if (tok->async_def) {
/* We're somewhere inside an 'async def' function, and
we've encountered a NEWLINE after its signature. */
tok->async_def_nl = 1;
}
return NEWLINE;
}
...
}
在这个例子里,NEWLINE是一个标记(tokens),其值在Include/token.h中定义。
所有标记都是常量int值,并且在我们运行make regen-grammar时生成了Include/token.h文件。PyParser_ParseFileObject()返回的node类型对下一阶段至关重要,它会将解析树转换为抽象语法树(AST)。
typedef struct _node {
short n_type;
char *n_str;
int n_lineno;
int n_col_offset;
int n_nchildren;
struct _node *n_child;
int n_end_lineno;
int n_end_col_offset;
} node;
由于CST可能是语法,令牌ID或者符号树,因此编译器很难根据Python语言做出快速决策。
这就是下一阶段将CST转换为更高层次结构的AST的原因。此任务由Python/ast.c模块执行,该模块具有C版和Python API版本。在跳转到AST之前,有一种方法可以从解析器阶段访问输出。CPython有一个标准的库模块parser,它使用Python API去展示C函数的内容。该模块被记录为CPython的实现细节,因此你不会在其他Python解释器中看到它。此外,函数的输出也不容易阅读。输出将采用数字形式,使用make regen-grammar阶段生成的symbol和token编号,存储在Includ/token.h和Include/symbol.h中。
>>> from pprint import pprint
>>> import parser
>>> st = parser.expr('a + 1')
>>> pprint(parser.st2list(st))
[258,
[332,
[306,
[310,
[311,
[312,
[313,
[316,
[317,
[318,
[319,
[320,
[321, [322, [323, [324, [325, [1, 'a']]]]]],
[14, '+'],
[321, [322, [323, [324, [325, [2, '1']]]]]]]]]]]]]]]]],
[4, ''],
[0, '']]
为了便于理解,你可以获取symbol和token模块中的所有数字,将它们放入字典中,并使用名称递归替换parser.st2list()输出的值。
import symbol
import token
import parser
def lex(expression):
symbols = {v: k for k, v in symbol.__dict__.items() if isinstance(v, int)}
tokens = {v: k for k, v in token.__dict__.items() if isinstance(v, int)}
lexicon = {**symbols, **tokens}
st = parser.expr(expression)
st_list = parser.st2list(st)
def replace(l: list):
r = []
for i in l:
if isinstance(i, list):
r.append(replace(i))
else:
if i in lexicon:
r.append(lexicon[i])
else:
r.append(i)
return r
return replace(st_list)
你可以使用简单的表达式运行lex(),例如a+ 1,查看它如何表示为解析器树:
>>> from pprint import pprint
>>> pprint(lex('a + 1'))
['eval_input',
['testlist',
['test',
['or_test',
['and_test',
['not_test',
['comparison',
['expr',
['xor_expr',
['and_expr',
['shift_expr',
['arith_expr',
['term',
['factor', ['power', ['atom_expr', ['atom', ['NAME', 'a']]]]]],
['PLUS', '+'],
['term',
['factor',
['power', ['atom_expr', ['atom', ['NUMBER', '1']]]]]]]]]]]]]]]]],
['NEWLINE', ''],
['ENDMARKER', '']]
在输出中,你可以看到小写的符号(symbols),例如'test'和大写的标记(tokens),例如'NUMBER'。
抽象语法树
CPython解释器的下一个阶段是将解析器生成的CST转换为可以执行的更合理的结构。
该结构是代码的更高级别表示,称为抽象语法树(AST)。
AST是使用CPython解释器进程内联生成的,但你也可以使用标准库中的ast模块以及C API在Python中生成它们。
在深入研究AST的C实现之前,理解一个简单的Python代码的AST是很有用的。
为此,这里有一个名为instaviz的简单应用程序。可以在Web UI中显示AST和字节码指令(稍后我们将介绍)。
小插曲
这里我需要说下,因为我按照原文的例子去照着做,发现根本就运行不起来,所以我就和大家说我的做法。
首先,我们不能通过pip的方式去安装运行,而是从github上把他的源码下载下来,然后在其文件下创建一个文件。
该程序需要在Python3.6+的环境下运行,包含3.6。
1.下载
https://github.com/tonybaloney/instaviz.git
2.写脚本
随意命名,比如example.py,代码如下
import instaviz
def example():
a = 1
b = a + 1
return b
if __name__ == "__main__":
instaviz.show(example)
3.目录结构如下
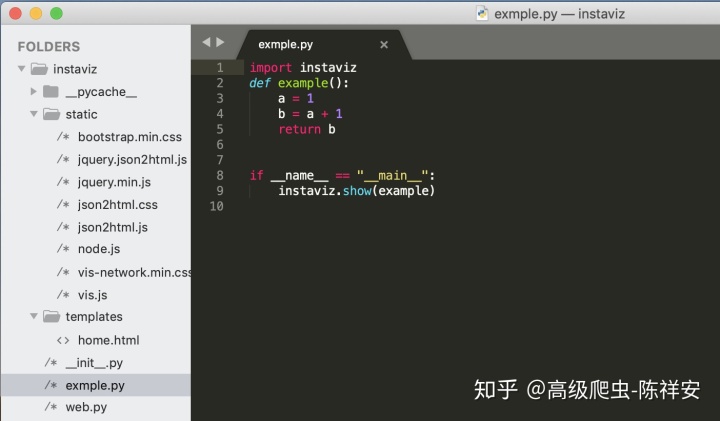
4.修改文件web.py
将原来的server_static函数和home函数用下面的代码替换
@route("/static/<filename>")
def server_static(filename):
return static_file(filename, root="./static/")
@route("/", name="home")
@jinja2_view("home.html", template_lookup=["./templates/"])
def home():
global data
data["style"] = HtmlFormatter().get_style_defs(".highlight")
data["code"] = highlight(
"".join(data["src"]),
PythonLexer(),
HtmlFormatter(
linenos=True, linenostart=data["co"].co_firstlineno, linespans="src"
),
)
return data
5.运行
好了,现在可以运行example.py文件了,运行之后会生成一个web服务(因为这个模块是基于bottle框架的),然后浏览器打开http://localhost:8080/
6.展示页面
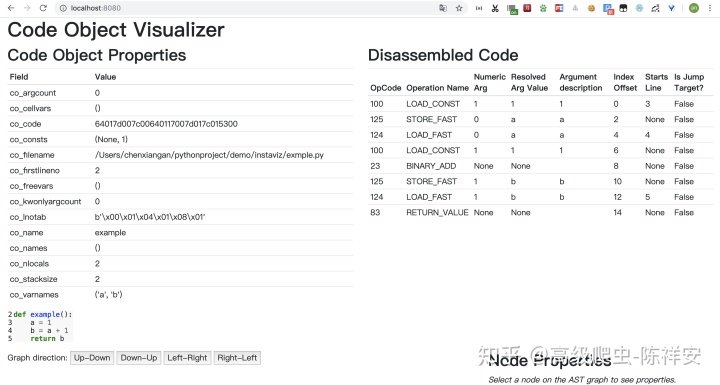
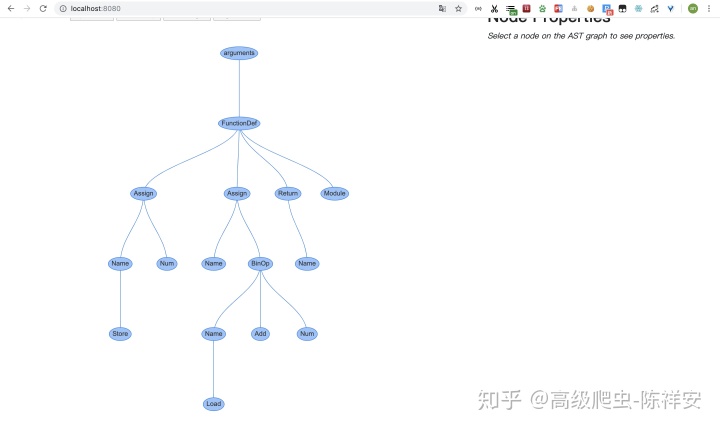
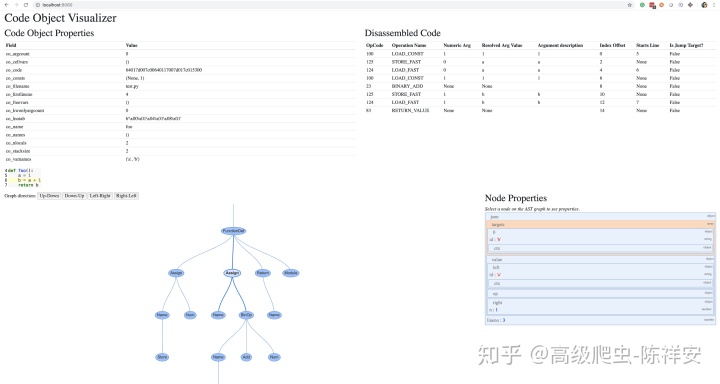
好了,我们继续原文的思路。
这里就到了展示图了
左下图是我们声明的example函数,表示为抽象语法树。
树中的每个节点都是AST类型。它们位于ast模块中,继承自_ast.AST。
一些节点具有将它们链接到子节点的属性,与CST不同,后者具有通用子节点属性。
例如,如果单击中心的Assign节点,则会链接到b = a + 1行:
它有两个属性:
- targets是要分配的名称列表。它是一个列表,因为你可以使用解包来使用单个表达式分配多个变量。
- value是要分配的值,在本例中是BinOp语句,a+ 1。
如果单击BinOp语句,则会显示相关属性:
left:运算符左侧的节点
op:运算符,在本例,是一个Add节点(+)
right:运算符右侧的节点
看一下图就了解了

。
在C中编译AST并不是一项简单的任务,因此Python/ast.c模块超过5000行代码。
有几个入口点,构成AST的公共API的一部分。
在词法分析(Lexing)和句法分析(Parsing)的最后一节中,我们讲到了对PyAST_FromNodeObject()的调用。在此阶段,Python解释器进程以node * tree的格式创建了一个CST。然后跳转到Python/ast.c中的PyAST_FromNodeObject(),你可以看到它接收node * tree,文件名,compiler flags和PyArena。
此函数的返回类型是定义在文件Include/Python-ast.h的mod_ty函数。
mod_ty是Python中5种模块类型之一的容器结构:
1.Module
2.Interactive
3.Expression
4.FunctionType
5.Suite
在Include/Python-ast.h中,你可以看到Expression类型需要一个expr_ty类型的字段。expr_ty类型也是在Include/Python-ast.h中定义。
enum _mod_kind {Module_kind=1, Interactive_kind=2, Expression_kind=3,
FunctionType_kind=4, Suite_kind=5};
struct _mod {
enum _mod_kind kind;
union {
struct {
asdl_seq *body;
asdl_seq *type_ignores;
} Module;
struct {
asdl_seq *body;
} Interactive;
struct {
expr_ty body;
} Expression;
struct {
asdl_seq *argtypes;
expr_ty returns;
} FunctionType;
struct {
asdl_seq *body;
} Suite;
} v;
};
AST类型都列在Parser/Python.asdl中,你将看到所有列出的模块类型,语句类型,表达式类型,运算符和结构。本文档中的类型名称与AST生成的类以及ast标准模块库中指定的相同类有关。Include/Python-ast.h中的参数和名称与Parser/Python.asdl中指定的参数和名称直接相关:
-- ASDL's 5 builtin types are:
-- identifier, int, string, object, constant
module Python
{
mod = Module(stmt* body, type_ignore *type_ignores)
| Interactive(stmt* body)
| Expression(expr body)
| FunctionType(expr* argtypes, expr returns)
因为C头文件和结构在那里,因此Python/ast.c程序可以快速生成带有指向相关数据的指针的结构。查看PyAST_FromNodeObject(),你可以看到它本质上是一个switch语句,根据TYPE(n)的不同作出不同操作。TYPE()是AST用来确定具体语法树中的节点是什么类型的核心函数之一。在使用PyAST_FromNodeObject()的情况下,它只是查看第一个节点,因此它只能是定义为Module,Interactive,Expression,FunctionType的模块类型之一。TYPE()的结果要么是符号(symbol)类型要么是标记(token)类型。
对于file_input,结果应该是Module。Module是一系列语句,其中有几种类型。
遍历n的子节点和创建语句节点的逻辑在ast_for_stmt()内。如果模块中只有1个语句,则调用此函数一次,如果有多个语句,则调用循环。然后使用PyArena返回生成的Module。
对于eval_input,结果应该是Expression,CHILD(n,0)(n的第一个子节点)的结果传递给ast_for_testlist(),返回expr_ty类型。然后使用PyArena将此expr_ty发送到Expression()以创建表达式节点,然后作为结果传回:
mod_ty
PyAST_FromNodeObject(const node *n, PyCompilerFlags *flags,
PyObject *filename, PyArena *arena)
{
...
switch (TYPE(n)) {
case file_input:
stmts = _Py_asdl_seq_new(num_stmts(n), arena);
if (!stmts)
goto out;
for (i = 0; i < NCH(n) - 1; i++) {
ch = CHILD(n, i);
if (TYPE(ch) == NEWLINE)
continue;
REQ(ch, stmt);
num = num_stmts(ch);
if (num == 1) {
s = ast_for_stmt(&c, ch);
if (!s)
goto out;
asdl_seq_SET(stmts, k++, s);
}
else {
ch = CHILD(ch, 0);
REQ(ch, simple_stmt);
for (j = 0; j < num; j++) {
s = ast_for_stmt(&c, CHILD(ch, j * 2));
if (!s)
goto out;
asdl_seq_SET(stmts, k++, s);
}
}
}
/* Type ignores are stored under the ENDMARKER in file_input. */
...
res = Module(stmts, type_ignores, arena);
break;
case eval_input: {
expr_ty testlist_ast;
/* XXX Why not comp_for here? */
testlist_ast = ast_for_testlist(&c, CHILD(n, 0));
if (!testlist_ast)
goto out;
res = Expression(testlist_ast, arena);
break;
}
case single_input:
...
break;
case func_type_input:
...
...
return res;
}
在ast_for_stmt()函数里,也有一个switch语句,它会判断每个可能的语句类型(simple_stmt,compound_stmt等),以及用于确定节点类的参数的代码。
再来一个简单的例子,2**42的4次幂。这个函数首先得到ast_for_atom_expr(),这是我们示例中的数字2,然后如果有一个子节点,则返回原子表达式.如果它有多个字节点,使用Pow操作符之后,左节点是一个e(2),右节点是一个f(4)。
static expr_ty
ast_for_power(struct compiling *c, const node *n)
{
/* power: atom trailer* ('**' factor)*
*/
expr_ty e;
REQ(n, power);
e = ast_for_atom_expr(c, CHILD(n, 0));
if (!e)
return NULL;
if (NCH(n) == 1)
return e;
if (TYPE(CHILD(n, NCH(n) - 1)) == factor) {
expr_ty f = ast_for_expr(c, CHILD(n, NCH(n) - 1));
if (!f)
return NULL;
e = BinOp(e, Pow, f, LINENO(n), n->n_col_offset,
n->n_end_lineno, n->n_end_col_offset, c->c_arena);
}
return e;
}
如果使用instaviz模块查看上面的函数
>>> def foo():
2**4
>>> import instaviz
>>> instaviz.show(foo)
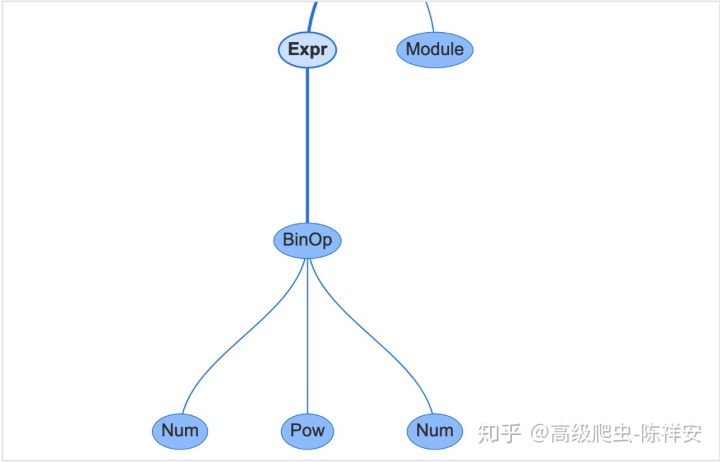
在UI中,你还可以看到其相应的属性:

总之,每个语句类型和表达式都是由一个相应的ast_for_*()函数来创建它。
参数在Parser/Python.asdl中定义,并通过标准库中的ast模块公开出来。
如果表达式或语句具有子级,则它将在深度优先遍历中调用相应的ast_for_*子函数。
结论
CPython的多功能性和低级执行API使其成为嵌入式脚本引擎的理想候选者。
你将看到CPython在许多UI应用程序中使用,例如游戏设计,3D图形和系统自动化。
解释器过程灵活高效,现在你已经了解它的工作原理。
在这一部分中,我们了解了CPython解释器如何获取输入(如文件或字符串),并将其转换为逻辑抽象语法树。我们还没有处于可以执行此代码的阶段。接下来,我们将继续深入,了将抽象语法树转换为CPU可以理解的一组顺序命令的过程。
-后续-
更多技术内容,关注公众号:python学习开发















 1040
1040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









