





上一篇:通过Linux Kernel参数探索TCP连接的建立
//图片来自于网络
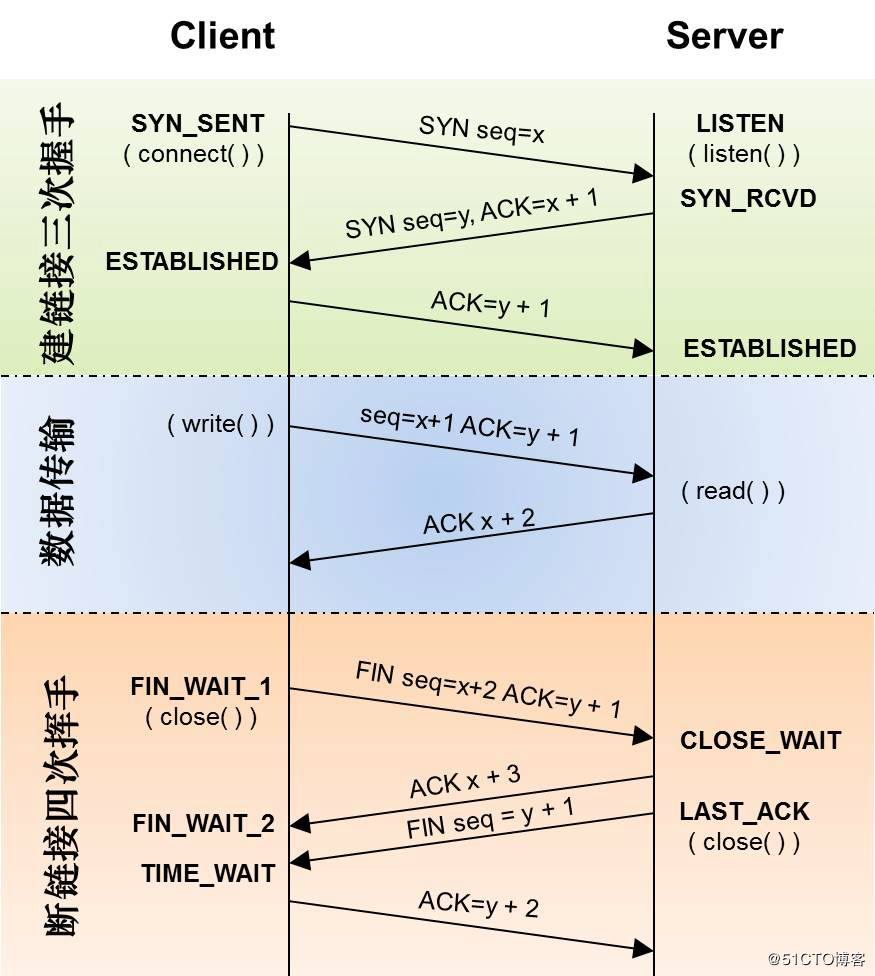
TCP连接中的数据传输 影响TCP数据传输的因素中,比较常见的有:1 接收窗口
可以理解成接收端所能提供的TCP套接字的缓冲区大小。
接收端利用其在TCP头中指定的滑动窗口值(Window Size)
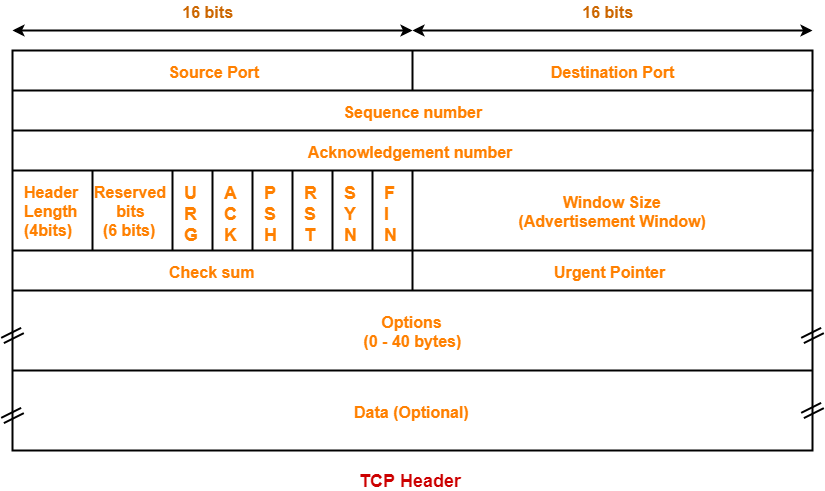
和窗口缩放因子(Window Scaling),
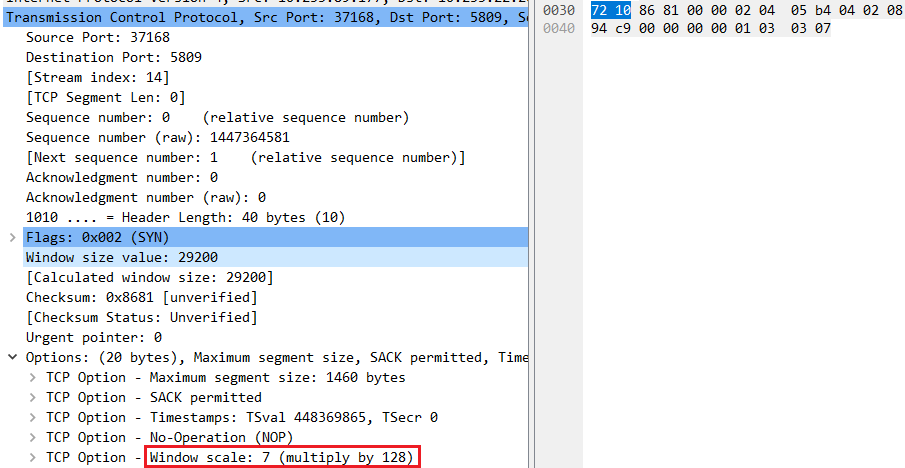
来告诉发送端对它所发送的数据能提供多大的缓冲区。
TCP头中的窗口(Window size)字段由16位bit所定义,窗口缩放因子最大为14(即放大16384),所以接收端能最大提供65535 * 16384 = 1G字节的TCP报文缓冲。
当然这个是理论值,实际环境中的每个TCP连接,连接双方使用的接收窗口比这个值要小很多很多。如上图所示,初始接收窗口为29200。这个值其实是20个MSS的大小( 初始接收窗口大小已固化在Linux kernel中,不能通过参数修改)。 后续的接收窗口大小会在TCP连接双方的通信中动态调整。2 net.ipv4.tcp_rmem
在实际网络条件允许的基础上,是不是把接收窗口设置成TCP接收缓存最大值(对应kernel参数net.ipv4.tcp_rmem,它定义了最小值、默认值和最大值,分别是4096bit,87380bit和4194304bit)就行了呢?
答案是否。因为有应用读缓存存在。
3 应用读缓存
用于应用的延时读及一些调度信息。
Linux使用kernel参数net.ipv4.tcp_adv_win_scale指出应用读缓存与接收窗口的比例关系。也就是说,Linux将要从TCP接收缓存(就是上面提到的tcp_rmem)中拿出1/(2^tcp_adv_win_scale)字节出来做应用读缓存。
有些场景下,为了在内网环境中达到高性能,我们可以指定TCP连接的接收缓存(net.ipv4.tcp_rmem)为一个固定值。它的计算方式是:
先通过BDP(bandwidth-delay product,带宽时延积)来估算出接收窗口最大值。即bandwith(bits/sec) * RTT / 2;
然后通过tcp_adv_win_scale比例计算出应用读缓存;
上述两者的和,即是TCP连接的接收缓存大小。
4 net.ipv4.tcp_moderate_rcvbuf = 1
在一个好的网络质量条件下,更大的接收缓存可以通知对端一次性地传输更多的内容,减少RTT。很明显这样可以让用户得到更好的服务体验。
但把TCP接收缓存设置成理想网络的最大值,当有成千上万个客户端来进行高并发连接时,服务端内存再大也不够用。 我们希望的场景应该是,在并发连接比较少时,把缓存限制放大一些,让每一个TCP连接满负荷工作;
当并发连接很多时,由于系统内存资源限制,就把缓存限制缩小一些,使每一个TCP连接的缓存小一些,以容纳更多的连接。
5 发送窗口
TCP是全双工的协议,会话的双方都可以同时接收、发送数据。TCP会话的双方都各自维护一个“发送窗口”和一个“接收窗口”。各自的“接收窗口”大小设置前面已经说过了。而各自的“发送窗口”则取决于对端通告的“接收窗口”。
即,发送窗口大小应该等于对方的接收窗口大小。 那是不是可以说,在得知了对方的接收窗口大小后,发送方可以一次性把等于对方接收窗口大小的数据报文一次性发出呢? 理想情况下是。 但现实网络如此复杂,TCP协议本身是需要保证数据的可靠传输的。一旦有报文丢失或延迟,协议栈将会花更多时间来处理重传和乱序,传输效率反而降低。 所以,拥塞窗口的概念出现了。6 拥塞窗口
拥塞窗口指在得到发送方确认前,最大允许传输的未经确认的数据。主要为了避免网络拥塞。
拥塞窗口初始值无法通过Linux kernel参数修改,默认值是10个MSS( 初始拥塞控制窗口大小经历过好几个阶段的调整。在kernel 3.0以后调到了10) 。它可以通过ip route命令临时调整。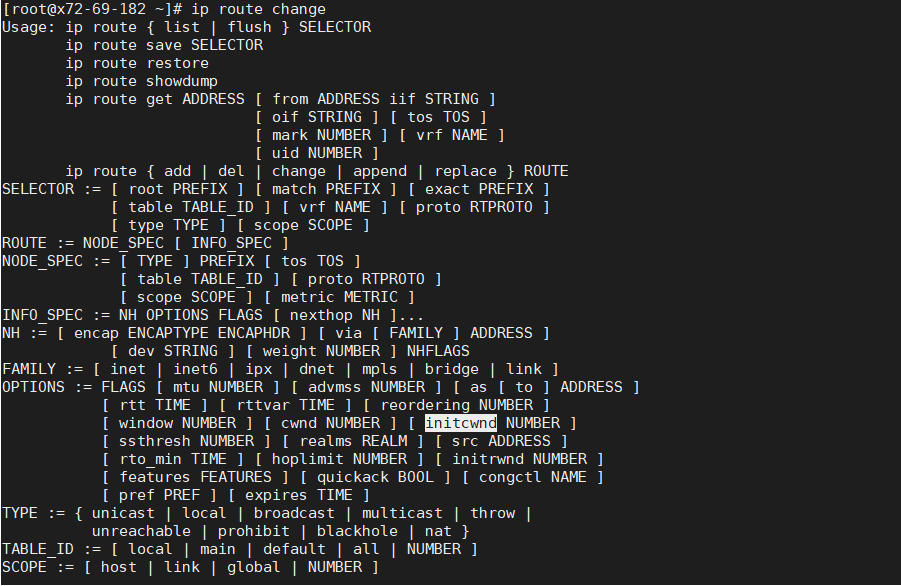 拥塞窗口大小无需像接收窗口一样通知给接收方,它在
达到慢启动阈值前呈指数级增长(对应慢启动算法)。
一旦拥塞窗口值大于了慢启动阈值,拥塞窗口则从指数增长调整为线性增长(对应拥塞避免算法),以避免引发网络阻塞。
综上所述,网络中实际传输的未经确认的数据大小 = min(rwnd, cwnd)。rwnd=接收窗口,cwnd=拥塞窗口。
拥塞窗口大小无需像接收窗口一样通知给接收方,它在
达到慢启动阈值前呈指数级增长(对应慢启动算法)。
一旦拥塞窗口值大于了慢启动阈值,拥塞窗口则从指数增长调整为线性增长(对应拥塞避免算法),以避免引发网络阻塞。
综上所述,网络中实际传输的未经确认的数据大小 = min(rwnd, cwnd)。rwnd=接收窗口,cwnd=拥塞窗口。
7 慢启动阈值(slow-start threshold)
初始慢启动阈值在TCP协议中建议为尽量大,Linux kernel 3.2中把它指定为常数0x7fffffff,即2G字节。这个值已超过了接收窗口理论最大值(1G)。
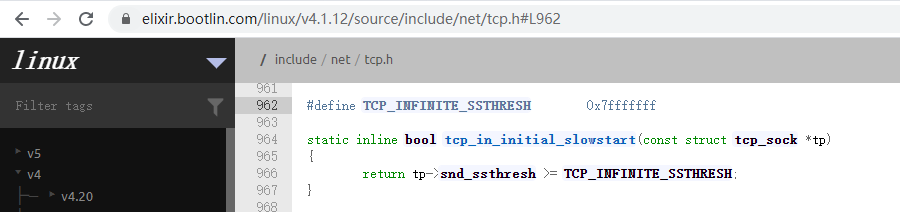 结合拥塞窗口,可以理解为:
TCP传输网络在未出现丢包、且网络条件足够好的情况下,拥塞窗口可以一直按指数增长到接收窗口最大值。
结合拥塞窗口,可以理解为:
TCP传输网络在未出现丢包、且网络条件足够好的情况下,拥塞窗口可以一直按指数增长到接收窗口最大值。
如果出现基于RTO超时的丢包场景:
1.慢启动阈值降低为当前拥塞窗口大小值的一半 2.把拥塞窗口大小恢复成初始值 3.此时拥塞窗口大小
如果出现收到三次重复ACK(即发送端满足启动快速重传丢包标准):
慢启动阈值修改为:max(在外数据值/2, 2 * MSS)
将拥塞窗口大小设为(慢启动阈值+ 3 * MSS)。可简单地理解为拥塞窗口减小到了原来的一半;
此时拥塞窗口大小>慢启动阈值,理论上发送端进入拥塞避免阶段。但实际进入的是一个叫“快速恢复”(Fast Recovery)的阶段: 每接收一个重复ACK,拥塞窗口大小值暂时增加 1 MSS。 当接收到一个正确的ACK,将拥塞窗口重设为 第一步中慢启动阈值(即,max(在外数据值/2, 2 * MSS)),消除临时膨胀。 此时拥塞窗口大小=慢启动阈值,发送端还是处于拥塞避免阶段。
8 丢包与重传
随着拥塞窗口大小的增加,可能会导致网络过载,进而出现丢包。而TCP协议是一个保证可靠性传输的协议,网络中丢失的报文必然会被发送端重新发起传输。
丢包重传最简单的做法是:TCP对每一个报文段都有一个定时器,称为重传定时器(RTO),当RTO超时且还没有得到数据确认,那么TCP发送端就会对该报文段进行重传。
上述这个RTO无法通过kernel参数配置,TCP协议通过一个高度动态的算法,根据实时RTT来不断调整其时间间隔大小(在还未获得连接双方实际RTT的时候,初始的RTO自kernel 2.6.18开始指定为1s)。
 依靠RTO超时进行重传会带来比较大的延迟,特别是在跨洲际网络RTT比较大情况下,单纯依靠RTO来进行重传,网络服务质量不可忍受。
快速重传算法应运而生,算法概要记录在RFC 5681中。
依靠RTO超时进行重传会带来比较大的延迟,特别是在跨洲际网络RTT比较大情况下,单纯依靠RTO来进行重传,网络服务质量不可忍受。
快速重传算法应运而生,算法概要记录在RFC 5681中。
9 快速重传
前提:
- 要求接收方每收到一个失序的TCP报文段后就立即发出重复确认(为了使发送方及早知道没有到达对方),而不要等待自己发送数据时才进行确认。
- 如果接收序列号空间存在洞(gap in the sequence space),新接收的报文完全填充了这个洞或者部分填充了这个洞,TCP也应该立即回复一个ACK确认包以便发送端及时获取接收端相关的信息。
发送方只要连续收到3个重复确认(ACK)就应当立即重传未被确认的报文段。
其中这个数字3,是RFC的建议。Linux kernel通过参数net.ipv4.tcp_reordering来控制,默认值为3。另外Linux可能还会根据乱序测量的结果来更新实际工作的重复确认门限值。它的范围最终会在[net.ipv4.tcp_reordering, net.ipv4.tcp_max_reordering]之间。
此算法弊端:
当有多个连续丢包时,每次重传一个包,收到重传包的ack后,再循环上述过程判断下一个丢包,效率太低。
10 选择性重传
前提:
TCP收、发双方都支持SACK(Linux kernel通过参数net.ipv4.tcp_sack控制,默认值为1,即使能)。
在本规范中,我们将“重复确认”定义为一个段,该段携带一个标识先前unacknowledged的和un-SACKed SACK块,该块是一个在HighACK和HighData之间的八位字节。在这个定义下,携带新SACK数据的ACK被视为重复确认,即使它携带新数据、改变通告窗口或移动累积确认点,这与[RFC5681]中重复确认的定义不同。
简单地说,启用 SACK 后,携带 SACK 的多个连续ACK ,即使ACK值不相同,但如果包含了重复的SACK段,也会被定义为重复 ACK。
优点:选择性重传,可以反映接收端是否存在序列号洞(gap in the sequence space),进而允许发送端根据SACK的情况同时传输多个丢包。
如果重传的包数据比较多的话,又会导致本来就很忙的网络就更忙了。
接下来FACK出现,用它可以来实现重传过程中的拥塞流控。
11 FACK(Forward Acknowledgment)
Linux通过kernel参数net.ipv4.tcp_fack控制,默认值为1。即打开拥塞避免和快速重传功能。这个算法的启用必须在net.ipv4.tcp_sack=1的前提下。
快速重传和选择性重传算法解决了死等RTO再重传丢包,造成网络延迟大的不足。但当网络无法产生足够的连续重复确认时,这两种算法都将失效。 在不得已使用RTO超时重传之前,我们还可以使用早期重传算法来触发快速重传。12 早期重传(Early Retransmit)
ER使能前提:
net.ipv4.tcp_reordering = 3。
ER使能与tcp_thin_dupack(对应Linux kernel参数net.ipv4.tcp_thin_dupack,默认值为0,即关闭)使能冲突,默认tcp_thin_dupack为关闭。
TCP的重复确认(dup ACK)是由报文乱序或报文丢失触发的。当发出的总数据包的个数少于4个的时候,就会因为没有足够数量的dup ACK而不能触发快速重传(假设默认dup ACK门限是3)。
这样的场景,如果仍要使能快速重传,则需要依靠ER算法。
ER算法启用前下面两个条件必须同时满足:
- 发出去的但是还没有收到ACK确认的TCP报文个数(假设为oseg)小于4
- 缓存中没有未发送数据或者发送窗口受限不能发送新数据(如果允许发送新数据的话就可以进一步触发dup ACK来达到门限了)。
如果这个tcp连接未使能SACK,用来触发ER的dup ACK门限降低为oseg - 1
如果这个TCP连接支持SACK,触发ER的条件则变为,(oseg-1)个TCP包已经被SACK确认。
0:关闭ER
1:打开ER
2:打开ER,但是会延迟ER重传(延迟时间为RTT/4),这样可以在一定程度上减少网络的冗余重传
3:同时支持2和TLP算法(Tail Loss Probe)。kernel版本4.1.12默认值
4:仅使能TLP算法。
假设一个拥塞窗口的尾部N个报文全部丢失。由于缺乏后续的新报文触发接收端返回重复响应,当N小于4时还可以通过ER触发快速重传,可是当N>=4的时候,ER算法就束手无策了
TLP同样是一个发送端算法,主要目的是用来处理尾包连续丢失和整个发送窗口的报文都丢失场景。
TLP算法会在支持SACK的TCP连接还是Open状态(Open状态是linux拥塞控制中的一种状态,表示一个发送端顺序接收到了没有SACK选项的ACK报文同时没有发现任何丢包的痕迹,例如发现了RTO超时的丢包痕迹就不会触发TLP)的时候,设置一个Probe TimeOut (PTO)。
当链路中有未被确认的数据包,同时在PTO超时时间内未收到任何ACK,则会触发tail loss probe。
TLP会选择传输序号最大的一个数据包作为tail loss probe包,这个序号最大的包可能是一个可以发送的新的数据包,也可能是一个重传包。
TLP通过这样一个tail loss probe包,如果能够收到相应的ACK,则会触发ER并执行快速重传,而不用等RTO超时再重传。
TCP连接建立后启用的定时器
1 重传定时器(Retransmission Timer)
前文已经介绍过了RTO的概念。
当发送段发送重传报文时,仍然可能出现丢包。这时RTO的计算采用一种叫做“指数退避”(binary exponential backoff)的方式。例如: 当RTO为1s的情况下,发生了数据重传,我们就用RTO=2s的定时器来重新传输数据。 下一次用4s、8s... 一直增加到超时上限为((2 << 9) - 1) * rto_base +(tcp_retries2 - 9) * TCP_RTO_MAX;其中rto_base=TCP_RTO_MIN=200ms,TCP_RTO_MAX=120s,tcp_retries2=15(它由kernel参数net.ipv4.tcp_retries2指定,默认值为15)。
2 Delayed ACK Timer
当一方接受到TCP segment,需要回应ACK。但是不需要立即发送,而是等上一段时间,看看是否有其他数据可以 捎带一起发送。这段时间便是 Delayed ACK Timer 。
3 Keepalive Timer
TCP socket 的 SO_KEEPALIVE option主要适用于这种场景:
连接的双方一般情况下没有数据要发送,仅仅就想尝试确认对方是否依然在线。
TCP keepalive 需要在应用程序层面针对其所用到的 Socket 进行开启。Linux无法强制所有 socket 启用keepalive.
Linux kernel只能设置如上心跳检测参数。
其它有价值的相关kernel参数
1 net.ipv4.tcp_retrans_collapse = 1
在TCP重传的时候,并没有限制TCP只能重传与初传完全相同的报文段大小,TCP允许执行重组包(repacketization),发送一个更大的TCP报文段,进而增加性能。
TCP在重传时候允许重组包同时提供了一种判别虚假重传的方法。
此kernel参数为非0值的时候打开重传重组包功能,为0的时候关闭重传重组包功能。
2 net.ipv4.tcp_retries1 = 3
3 net.ipv4.tcp_retries2 = 15
在RFC1122中有两个门限R1和R2。
当重传次数超过R1的时候,TCP向IP层发送negative advice,指示IP层进行MTU探测、刷新路由等过程,以防止由于网络链路发生变化而导致TCP传输失败。
当重传次数超过R2的时候,TCP放弃重传并关闭TCP连接。














 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









