





xpath的语法已经掌握了,接下来可以进入实战了,爬取天气情况,本篇实战,我只爬取温度信息,利用一个小的爬虫实例向你演示如何利用xpath爬取数据
1. 网页分析
我想爬取的网址为
【北京天气】北京今天天气预报,今天,今天天气,7天,15天天气预报,天气预报一周,天气预报15天查询www.weather.com.cn这里,我只想爬取北京城区当天的温度信息
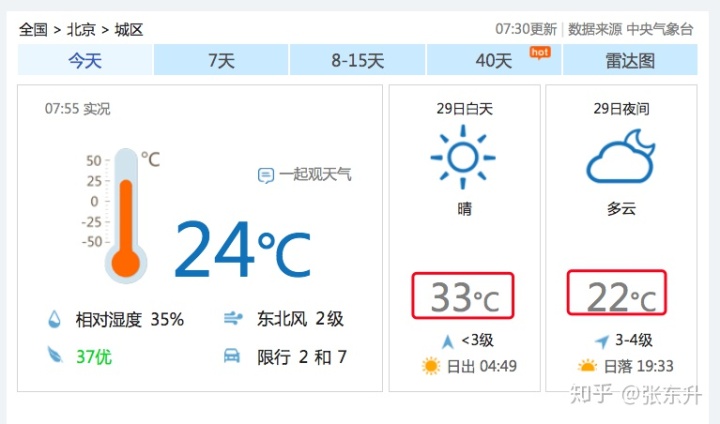
打开网址,然后打开谷歌浏览器的开发者工具,使用元素选择器(下图上方红框内的箭头按钮)点击33°C, 就可以在Elements选项卡里看到所选中的元素信息了
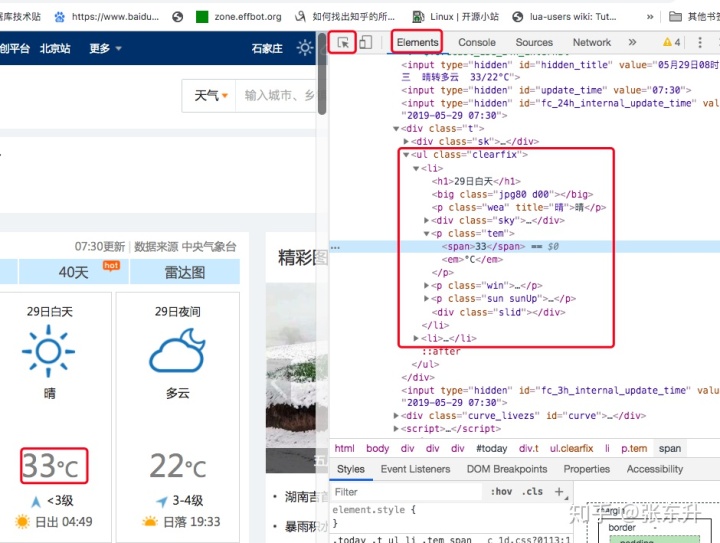
继续分析,白天和夜间的天气信息都在两个li节点下,这两个li都在<ul class="clearfix"> 节点下,其中,温度信息在<p class="tem"> 节点下。
通常,我会习惯性的先获取<ul class="clearfix"> 节点,这样,我就可以从这个节点出发继续寻找其他信息的节点了,但这个网页里有两个<ul class="clearfix"> 节点,其中一个并没有包含天气信息,所以,我这次直接通过路径选取p节点,我的选取路径如下
//ul[@class='clearfix']//p[@class='tem']// 表示选取节点时不考虑节点出现的位置,只要节点tag符合要求就会被选取,ul虽然选取了两个,但是从ul继续向下选取p节点时,符合class='tem' 的节点就只有上图Elements红框内的两个p节点符合要求了,这样,就得到了两个p节点。
p节点下,又包含了span和em节点,一个是温度的数值,一个是温度的单位,遇到这种情况,需要在路径表达式中使用string
2. 示例代码
import requests
import time
from functools import wraps
from lxml import etree
class HttpCodeException(Exception):
pass
def retry(retry_count=5, sleep_time=1):
def wrapper(func):
@wraps(func)
def inner(*args, **kwargs):
for i in range(retry_count):
try:
res = func(*args, **kwargs)
return res
except:
time.sleep(sleep_time)
continue
return None
return inner
return wrapper
@retry()
def get_html(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.87 Mobile Safari/537.36',
'Host': 'www.weather.com.cn',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
}
res = requests.get(url, headers=headers)
if res.status_code != 200:
raise HttpCodeException
res.encoding = 'utf-8'
return res.text
def crawl_weather(url):
html = get_html(url)
html = etree.HTML(html)
tem_lst = []
tem_nodes = html.xpath("//ul[@class='clearfix']//p[@class='tem']")
for index, node in enumerate(tem_nodes):
text = node.xpath("string(.)")
text = text.strip()
tem_lst.append(text)
return tem_lst
if __name__ == '__main__':
url = "http://www.weather.com.cn/weather1d/101010100.shtml"
data = crawl_weather(url)
print(data)














 2712
2712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









