





最近看到很多同学回复关键词MySQL数据库,看来想要学习这方面的课程,所以小艾同学这次就专门整理了合集,你们回复关键词“mysql或者MySQL”就可以看到了,今天再为大家更新一篇关于MySQL数据库引擎InnoDB索引实现的教程,欢迎大家一起学习交流!
关于这节课将分为四大篇章讲解
1. InnoDB 采用 B+Tree这种数据结构来实现 B-Tree索引。
2. 为什么MySQL选择B+树做索引:
3. B+ 树的三个特点:
3. B+ 树的三个优点:
一、InnoDB 采用 B+Tree这种数据结构来实现 B-Tree索引
InnoDB 存储引擎采用“聚集索引”的数据存储方式实现B-Tree索引。
聚集的定义:数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引。
单单从定义来看是不是显得有点抽象,打个比方,一个表就像是我们以前用的新华字典,聚集索引就像是拼音目录,而每个字存放的页码就是我们的数据物理地址,我们如果要查询一个“好”字,我们只需要查询“好”字对应在新华字典拼音目录对应的页码,就可以查询到对应的“好”字所在的位置,而拼音目录对应的A-Z的字顺序,和新华字典实际存储的字的顺序A-Z也是一样的。现在用一个简单的示意图来大概说明一下在数据库中的样子:
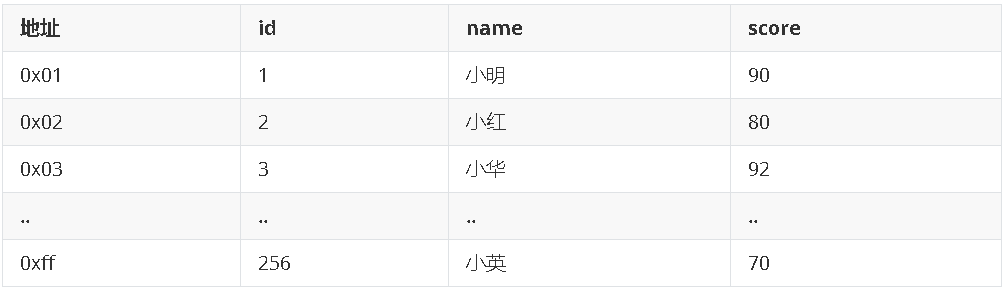
注:第一列的地址表示该行数据在磁盘中的物理地址,后面三列才是我们SQL里面用的表里的列,其中id是主键,建立了聚集索引。
结合上面的表格就可以理解这句话了吧:数据行的物理顺序与列值的顺序相同,如果我们查询id比较靠后的数据,那么这行数据的地址在磁盘中的物理地址也会比较靠后。而且由于物理排列方式与聚集索引的顺序相同,所以也就只能建立一个聚集索引了。
二. 为什么MySQL选择B+树做索引:
常见的数据库索引有下面三种类型:
第一是哈希表
哈希表相信大家都已经不陌生了,我们可以将数据库的索引字段后哈希并保存下来。只要哈希算法设计的合理,我们可以非常快地找到对应数据的一个存放地址,然后到对应的存放地址就可以快速地找到数据。那么,哈希索引有什么缺点呢?首先是哈希表比较适合在内存中使用,但是如果要落盘,就比较麻烦了,特别是哈希表扩容的时候,磁盘的很多数据都会修改。第二,哈希表没办法进行一个区间的筛选。
第二种则是数组索引
与上述的哈希表类似,但又有所不同。与哈希索引类似,数组索引的效率也是非常高的,在一个有序数组里面去查找元素,我们只要进行二分查找即可。但是数组索引的问题也是非常地明显,那便是插入非常的麻烦,你插入一个新的元素,就要把后面所有的元素都往后移动一下。所以,数组索引我们一般只有静态数据才会使用。
第三种:二叉树
有序数组都讲了,那么接下来肯定就是二叉树了,我们说的二叉树当然是二叉排序树,二叉排序树相对与数组,最大的优点是方便插入。但是同时也存在这么一个问题,因为索引的数据可能存在磁盘,那么如果索引的数据超过1000条的时候,就有可能要经过10次才能够找到最终的数据,而磁盘IO的瓶颈在于寻道跟旋转,效率必然会降低。所以,我们要尽量地减少在磁盘中寻道跟旋转的次数,所以多叉树就被广泛应用在数据库索引当中了。而在多叉树中,最常被使用的,便是B+树。
三. B+ 树的三个特点:
关键字数和子树相同
非叶子节点仅用作索引,它的关键字和子节点有重复元素
叶子节点用指针连在一起
首先第一点不用特别介绍了,在 B 树中,节点的关键字用于在查询时确定查询区间,因此关键字数比子树数少一;而在 B+ 树中,节点的关键字代表子树的最大值,因此关键字数等于子树数。
第二点,除叶子节点外的所有节点的关键字,都在它的下一级子树中同样存在,最后所有数据都存储在叶子节点中。根节点的最大关键字其实就表示整个 B+ 树的最大元素。
第三点,叶子节点包含了全部的数据,并且按顺序排列,B+ 树使用一个链表将它们排列起来,这样在查询时效率更快。
由于 B+ 树的中间节点不含有实际数据,只有子树的最大数据和子树指针,因此磁盘页中可以容纳更多节点元素,也就是说同样数据情况下,B+ 树会 B 树更加“矮胖”,因此查询效率更快。
B+ 树的查找必会查到叶子节点,更加稳定。
有时候需要查询某个范围内的数据,由于 B+ 树的叶子节点是一个有序链表,只需在叶子节点上遍历即可,不用像 B 树那样挨个中序遍历比较大小。
四、B+ 树的三个优点:
IO 次数少,磁盘读写代价低
B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
查询性能稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
B+树更适合基于范围的查询
B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低。
相关推荐
1、MySQL的分区分表和SQL性能优化详解
2、从设计、功能、架构、测试四方面谈谈我多年MySQL优化的经验
3、Docker容器操作命令:目录挂载与安装MySQL容器详解

回复关键词
Redis 分布式限流 MySQL alibaba JVM性能调优
看更多精彩教程
喜欢本文,记得点击个在看,或者分享给朋友哦!















 1713
1713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









