





 针对QMIX算法在复杂协作任务中表现不佳的问题,提出WeightedQMIX算法,通过为动作加权来确保最优策略的选择。实验表明,在多智能体任务中效果显著。
针对QMIX算法在复杂协作任务中表现不佳的问题,提出WeightedQMIX算法,通过为动作加权来确保最优策略的选择。实验表明,在多智能体任务中效果显著。

论文标题Weighted QMIX: Expanding Monotonic Value Function Factorisation,原文http://arxiv.org/abs/2006.10800v1,发表于NeurIPS 2020。
本文分析了QMIX算法在解决复杂协作任务时性能不佳的原因:由于最优动作价值被低估,总是选到次优联合策略。本文将QMIX转化为最优化问题,通过在引入一个加权来纠正这一点,以便能够忽略次优策略而选择最优策略,并且提出两种方案,(CW)QMIX和(OW)QMIX。最后在捕食者-猎物任务和星际SMAC任务中验证了算法效果。
背景
介绍一下QMIX算法。QMIX是最近几年比较受欢迎的多智能体强化学习算法,适用于CTDE框架,使用了值分解的思想,将全局Q分解为局部Q。QMIX算法在网上有很多相关的说明文章,这里就不详细说了。
QMIX需要满足单调性(monotonicity)约束:
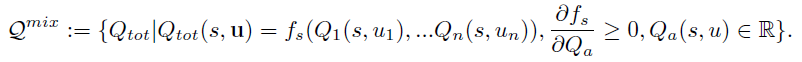
QMIX算法网络结构如下:
这篇文章将QMIX算法写成了最优化的形式:
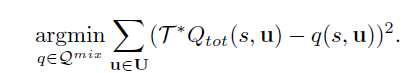
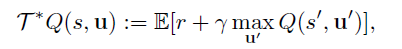
优化的目标是,所有动作td-error的平方和最小。这就带来了一个问题,一旦对几个次优联合动作的错误估计超过了对单个最优联合动作的更好估计,就会导致最优动作价值被低估,使选择的动作次优。
举个例子,对于两智能体三动作任务:
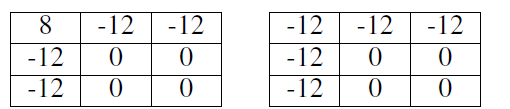
横轴是智能体1选择a,b,c三个动作,纵轴是智能体1选择a,b,c三个动作。左图是真实的pay-off矩阵,右图是QMIX学习到的。
可以看到,QMIX算法忽略了最优的a-a动作,认为这是不好的策略,而认为0值的次优策略是好的策略。
这是因为,QMIX对4个0值联合动作的错误估计超过了对1个12值最优联合动作的更好估计,对于目标函数来说,降低4个0值动作的误差要比降低1个12值动作误差更好。QMIX算法不能把最优动作的最高值提到-12以上,除非提高其他坏动作的值到-12以上,或者把0值动作的值降到-12以下。
这就会导致最优动作价值被低估,使选择的动作次优。
算法
本文认为,既然最后要贪婪地选取最优策略,那么精确地表示最优联合动作的值比表示次优联合动作的值更重要。
这就带来了本文的核心思想,为每一个动作加权:
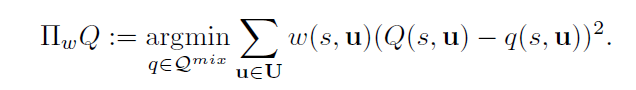
对于目标函数来说,给最优动作的权值要更大,给其他动作的权值更小,这样优化的时候就会倾向于将最优动作计算得更为准确。当w恒为1时,退化为普通的QMIX算法。
有两种赋权方式,第一种是理想情况下的中心加权,Idealised Central Weighting:
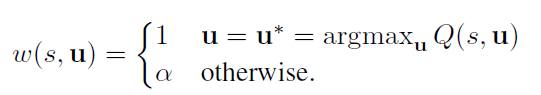
只有最优动作的权值为1,其他都是小于1的值。也就是对每个次优操作进行减重。
然而实际上,最优联合动作是不可知的,只能找到近似的最优联合动作。
第二种方式是乐观赋权,Optimistic Weighting:
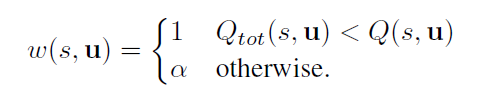
因为最优动作常常被低估,所以只要是被低估的动作,就认为有可能是最优动作(一种乐观的赋权方式)。
具体到深度强化学习的算法中,WQMIX使用另一个Q函数Q*来代替Qtot(QMIX),作为Q-target。Q*和QMIX类似,只不过没有单调性约束,表示能力更强,更接近于真实的联合Q值。
但是选动作的时候,由于真实的最优动作不可知,使用Qtot选出的动作作为Q*的动作。也就是:
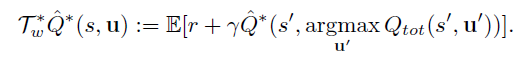
然后用加权的方式计算:
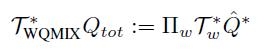
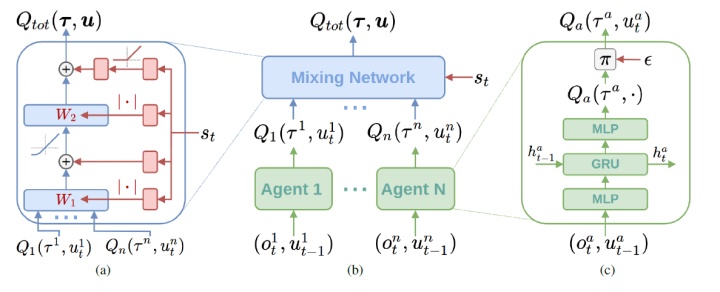
整体的神经网络结构如下:
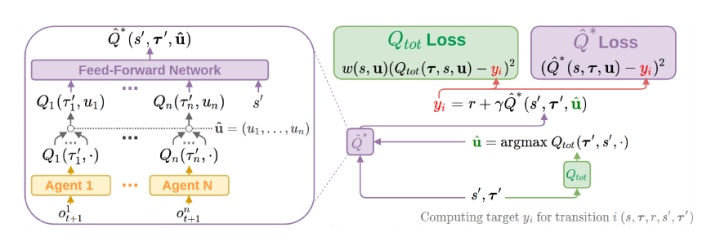
网络分为两个部分,Q*和Qtot。
Qtot网络用的是QMIX的网络,包括局部的Q网络和mixing net。Loss函数如下:
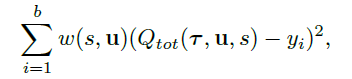
Target为:
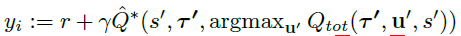
这里的target是用Q*计算出来的,不过Q*的动作又是Qtot选出的。
Q*的网络和QMIX的网络相似,但mixing net没有单调性约束,表示能力更强。Loss函数:
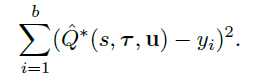
同样,Target为:
最后是权值,中心化权值(CW)的计算方式:
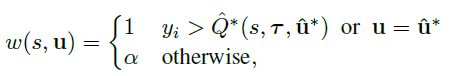
理论上应该给最优的联合动作的权值赋值为1,但实际上都采用的是近似方案。这里给出两种近似采取了最优动作的情况:
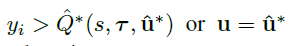
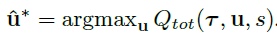
另一种赋权值的方法是乐观权值(OW):
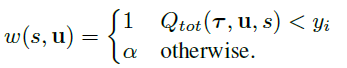
如之前所说,只要是被低估的动作,就认为有可能是最优动作。
实验
主要是在多智能体协作的任务中进行实验,测试agent之间的协调能力。
首先是捕食者-猎物玩家,包括8个agent的部分可观察捕食者-猎物任务,该任务需要agent之间协调得很好,因为当只有一个 agent(而不是两个agent)试图捕获猎物时,会提供惩罚。这就需要多个agent同时捕获猎物。
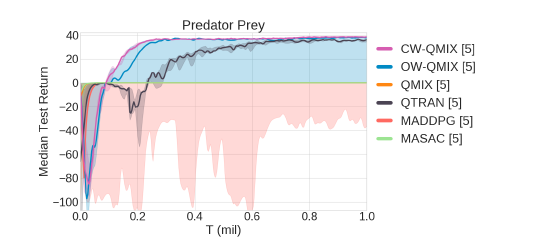
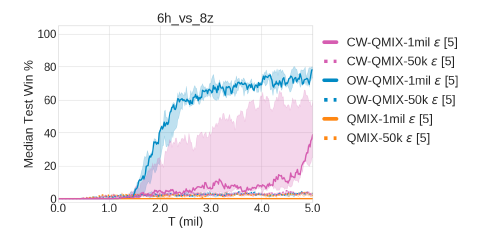
另外是星际争霸多智能体任务SMAC,在复杂任务中,WQMIX要比QMIX效果好很多。
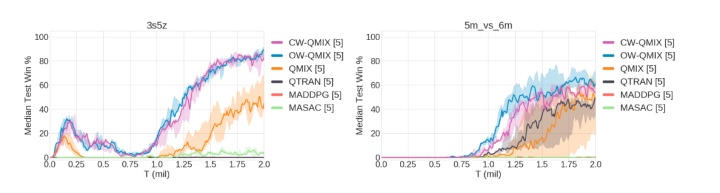
还有非常复杂的任务,6h_vs_8z,差距就更明显了(-后面是ε衰减步数,表示探索的程度)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









