





原标题:运用Python多线程爬虫下载漫画
前言:
以前,我都是买漫画书看的,那个时候没有电脑。今天,我到网上看了一下,发现网上提供漫画看,但是时时需要网络啊!为什么不将它下载下来呢!
1.怎样实现
这个项目需要的模块有:requests、urllib、threading、os、sys
其中requests模块也可以不用,只要urllib模块即可,但我觉得requests模块爬取数据代码量少。
os模块主要是为了创建文件夹,sys主要是为了结束程序(当然,这里我只是判断是否已经存在我即将创建的文件夹,如果存在,我就直接结束程序了,这个位于代码的开头)。
1.1 爬取我们需要的数据(网页链接、漫画名称、漫画章节名称)

我爬取漫画的网址为:https://www.mkzhan.com/
我们到搜索栏上输入 一个漫画名称
我输入的是:斗破苍穹,点击搜索,可以看到这个界面:
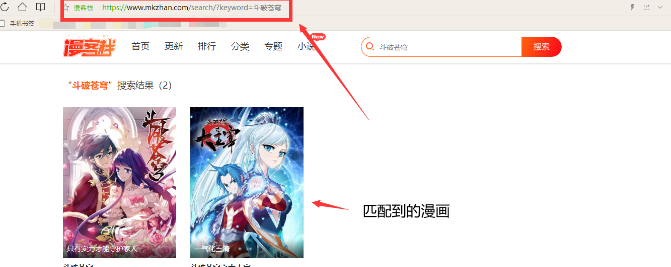
对这个网址进行分析:https://www.mkzhan.com/search/?keyword={}
大括号代表的内容就是我们输入的漫画名称,我们只要这样组合,就可以得到这个网址:
from urllib importparse
_name=input('请输入你想看的漫画:')
name_=parse.urlencode({'keyword':_name})
url='https://www.mkzhan.com/search/?{}'.format(name_)
之后,就是对这个网址下面的内容进行爬取了,这个过程很容易,我就不讲了。
我们点击一下其中的一本漫画,来到这个界面
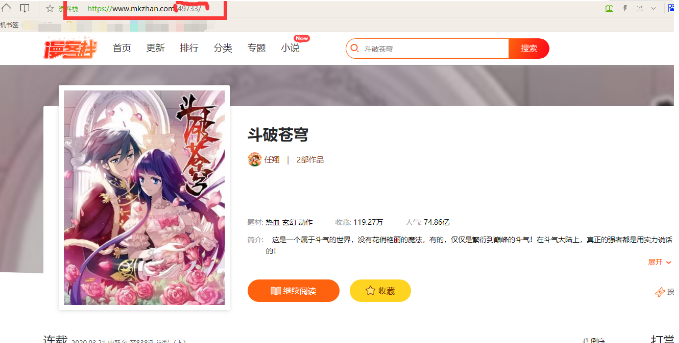
这个网址,需要我们从上一个网址中得到并进行拼接,我们需要得到这个网址下面的漫画所有章节的链接和名称。
我们按F12来到开发者工具:
可以发现这些章节的内容在这个标签下面:
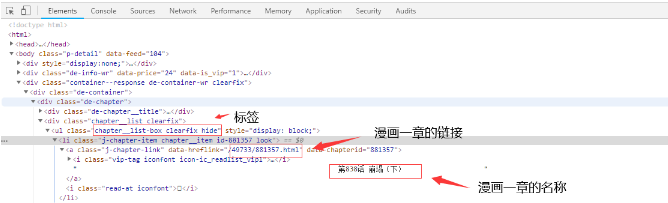
html1=requests.get(url=url1)
content1=html1.text
soup1=BeautifulSoup(content1,'lxml')
str2=soup1.select('ul.chapter__list-box.clearfix.hide')[0]
list2=str2.select('li>a')
name1=[]
href1=[]for str3 inlist2:
href1.append(str3['data-hreflink']) #漫画一章的链接
name1.append(str3.get_text().strip()) #漫画一章的题目,去空格
这样我们就可以得到我们想要的内容了,我们点击其中的一章进入,发现里面只不过是一些图片罢了,我们只需把这些图片下载下来就行了。

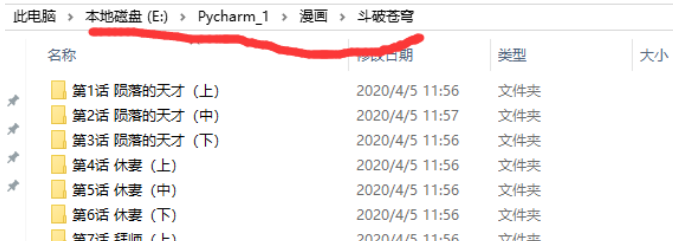
代码运行结果:


下载完成之后,会在同一个文件夹下面多出一个文件夹,文件夹的名称为你输入漫画名称,这个文件夹下面会有很多文件夹,这些文件夹的名称是漫画章节的名称。


2.完整代码:
importrequestsfrom urllib importparsefrom bs4 importBeautifulSoupimportthreadingimportosimportsys
_name=input('请输入你想看的漫画:')try:
os.mkdir('./{}'.format(_name))except:print('已经存在相同的文件夹了,程序无法在继续进行!')
sys.exit()
name_=parse.urlencode({'keyword':_name})
url='https://www.mkzhan.com/search/?{}'.format(name_)
html=requests.get(url=url)
content=html.text
soup=BeautifulSoup(content,'lxml')
list1=soup.select('div.common-comic-item')
names=[]
hrefs=[]
keywords=[]for str1 inlist1:
names.append(str1.select('p.comic__title>a')[0].get_text()) #匹配到的漫画名称
hrefs.append(str1.select('p.comic__title>a')[0]['href']) #漫画的网址
keywords.append(str1.select('p.comic-feature')[0].get_text()) #漫画的主题
print('匹配到的结果如下:')for i inrange(len(names)):print('【{}】-{} {}'.format(i+1,names[i],keywords[i]))
i=int(input('请输入你想看的漫画序号:'))print('你选择的是{}'.format(names[i-1]))
url1='https://www.mkzhan.com'+hrefs[i-1] #漫画的链接
html1=requests.get(url=url1)
content1=html1.text
soup1=BeautifulSoup(content1,'lxml')
str2=soup1.select('ul.chapter__list-box.clearfix.hide')[0]
list2=str2.select('li>a')
name1=[]
href1=[]for str3 inlist2:
href1.append(str3['data-hreflink']) #漫画一章的链接
name1.append(str3.get_text().strip()) #漫画一章的题目,去空格
defDownlad(href1,path):
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3756.400 QQBrowser/10.5.4039.400'}
url2='https://www.mkzhan.com'+href1
html2=requests.get(url=url2,headers=headers)
content2=html2.text
soup2=BeautifulSoup(content2,'lxml')
list_1=soup2.select('div.rd-article__pic.hide>img.lazy-read') #漫画一章中的所有内容列表
urls=[]for str_1 inlist_1:
urls.append(str_1['data-src'])for i inrange(len(urls)):
url=urls[i]
content3=requests.get(url=url,headers=headers)
with open(file=path+'/{}.jpg'.format(i+1),mode='wb') as f:
f.write(content3.content)returnTruedefMain_Downlad(href1:list,name1:list):whileTrue:if len(href1)==0:breakhref=href1.pop()
name=name1.pop()try:
path='./{}/{}'.format(_name,name)
os.mkdir(path=path)ifDownlad(href, path):print('线程{}正在下载章节{}'.format(threading.current_thread().getName(),name))except:passthreading_1=[]for i in range(30):
threading1=threading.Thread(target=Main_Downlad,args=(href1,name1,))
threading1.start()
threading_1.append(threading1)for i inthreading_1:
i.join()print('当前线程为{}'.format(threading.current_thread().getName()))
3.总结
我觉得这个程序还有很大的改进空间,如做一个ip代理池,这样再也不用担心ip被封了,另外,还可以做一个自动播放漫画图片的程序,这样就可以减少一些麻烦了。
注意:本程序代码仅供娱乐和学习,且莫用于商业活动,一经发现,概不负责。
如果大家觉得这个还可以的话,记得给我点一个小小的赞。














 1365
1365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









