






导语:上期我们谈了谈如何高效的入门 Python 编程,了解了 Python 的编程环境以及常用的包,如 Pandas、Matplotlib、Numpy 等。这次我们将以实践项目的形式,帮助大家快速的上手 Python,并简单运用一下上述的包,让我们一起开始吧!
1 开始前的准备工作
上期谈过,Python是一种胶水语言,它能做的事情太多。但是,对于一个初学者来说,如何开始一个 Python 的实践项目,或者说是从哪个角度切入会是一个比较好的选择呢?本文将以一个简单的例子来谈谈如何开始。
众所周知,当前 Python 被用于数据科学是大多数科研人员的第一选择。而在数学科学中,Python 即可以用于前期的数据处理、数据分析,也可以用于开发模型、仿真模拟。前者无需太多相关知识背景,只需明确数据分析的目标即可;而后者则需要设计好研究计划,做好研究方案。
因此,不要一开始就想入门机器学习、深度学习等,这是不符合学习规律的。那么,我们应该如何快速上手呢?
其实,最简单也是最有趣的开始,就是准备一个你了解的数据集,不要太大,用 Python 来分析数据以及绘制数据图可能是一个非常好的开始。那么,在开始之前,你可能需要做好以下准备工作:
1.1 安装软件,初次调试
如果你还不知道安装哪个软件,那么推荐你直接安装 Anaconda,具体的介绍可参见零基础如何快速入门 Python 编程?谈谈个人看法。如果你耐心阅读了该期的内容,并学习了相关的基础语法,那么你将很快上手。
我们了解过,Anaconda 开发环境中包含了 Jupyter Notebook 和 Spyder 两个编程环境,并且推荐以 Jupyter Notebook 作为开始基础语法练习的编程环境。然而,本次我们的目的是利用 Python 来进行简单的数据分析和绘制图表,这样就非常有必要用到 Spyder,它的工作界面如下图所示:
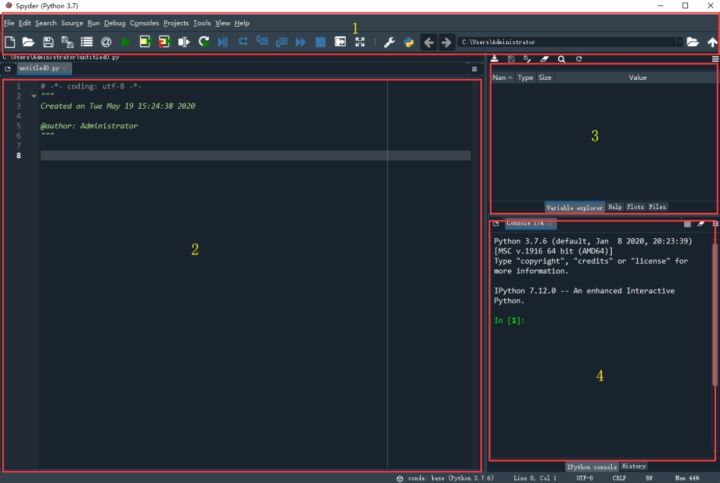
为什么要选择 Spyder 作为数据分析时的工具呢?因为,它不仅内嵌了 Python 主程序,最重要的是它可以非常方便的管理变量以及实时显示处理结果和绘制的图表。我们不妨来深入了解一下这个编辑器,先不管语法到底应该如何写。
我们将 Spyder 工作界面大致分为 4 个区域,1 表示工具栏,常用的设置选项均聚集于此地;2 表示代码区,我们的代码一般都是在这里开始逐行编写;3 表示变量区「主要是」,当我们利用软件读取数据后,数据表中的变量将呈现在这里;4 表示工作台,比如每次运行代码后的结果将呈现在这里。
好了,到这里我们已经明白了需要用 Spyder「内嵌 Python 的开发环境」 来分析数据,并大致了解了它的工作界面,那就让我们开始下一步的挑战。
1.2 明确目标,梳理思路
接下来,我们想要立即开始数据分析或绘制图表还存在一定的困难,因为还有一些问题我们没有解决,大家可以思考一下。
好吧,我们就加快进程开门见山吧。想要实现简单的数据分析和绘制图表,这个简单的任务存在几个关键问题。
如何将数据导入至软件中?
如何选用任意变量所在的数据列?
如何进行简单的描述性统计?
如何绘制简单的数据图?
带着问题开始实践,或许是比较高效的一种学习方法。不论如何,就我们开始逐个攻克吧!
2 动手开始实践
2.1 准备数据集
在开始处理数据之前,需要先有一组可供我们分析的数据。为了方便,我们就直接以一组包含速度(Speed)、加速度(Acceleration)和车头间距(Headway)的数据集开始吧。这组数据大小为 1000*3,即 1000 行 3 列,部分数据如下(本次数据及代码见文末二维码):
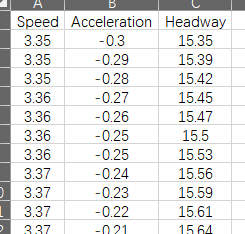
在你自己的操作过程中,可以任意选取你喜欢的数据集来实践,这不是问题的重点。
2.2 读取数据集
可能已经习惯了利用 Excel 或者是其他菜单式操作软件来打开数据,这次我们要以代码的形式打开。首先,还是需要打开 Spyder ,它内嵌了 Python 的主程序,如果直接利用 Spyder 来打开数据表,这在通常来看不是一个很好的选择。此时,我们需要借助辅助工具「包」来解决这个问题。
上一期我们已经聊过,Pandas 在处理表格数据时优势明显,那么现在就需要用这个包来读取数据。你可以这样认为:Spyder 就像一个最普通的「木板」,而包就像「木轮子」,他们组合在一起就能发挥更强大的功能。也就是说,包只是一个实现某些功能的代码组合,它依然是用 Python 语言写的,只不过是封装好的,用户无需再去为了一个功能重复写相应的代码。
那么,Pandas 如何实现读取数据集呢?显然,需要先调用它,也可以理解为激活它,让它准备开始工作。比如:
# 导入 Pandas 包
这句代码非常容易理解,就是将 pandas 导入到程序中,并简称为 pd,这样后边我们再使用它时就只用声明 pd 就可以啦。
然后是读取数据集,假设数据集的文件格式是 CSV 的,那么我们需要写的代码为:
# 读取数据集
这句代码不难理解,我们来逐个分析,这里假设你已经学完上期推荐的基础语法。data 表示的是新建的变量,这个可以根据实际的需求来命名,因为我们读取的是原始数据,我习惯性命名为 data,你也可以命名自己喜欢的,但前提是容易看懂表达什么。
pd.read_csv( ),如果把括号内的内容先去掉,就只剩下了这句语句,它表示的意义已经很明确了。pd 表示的是调用 pandas 包,.read_csv( ) 表示的是要用读取 CSV 文件的方法,就是说,如果给定数据表的路径,这句代码就能实现读取数据,并载入 Spyder 中。
最后剩下括号内的文件路径了。注意到 C: 之后的显然是数据表的路径,放在桌面(Desktop)上的,如果你不知道文件的路径是什么,可以打开电脑的搜索功能,搜 CMD(命令提示符),打开后将数据表直接拖拽进去便显示路径了。
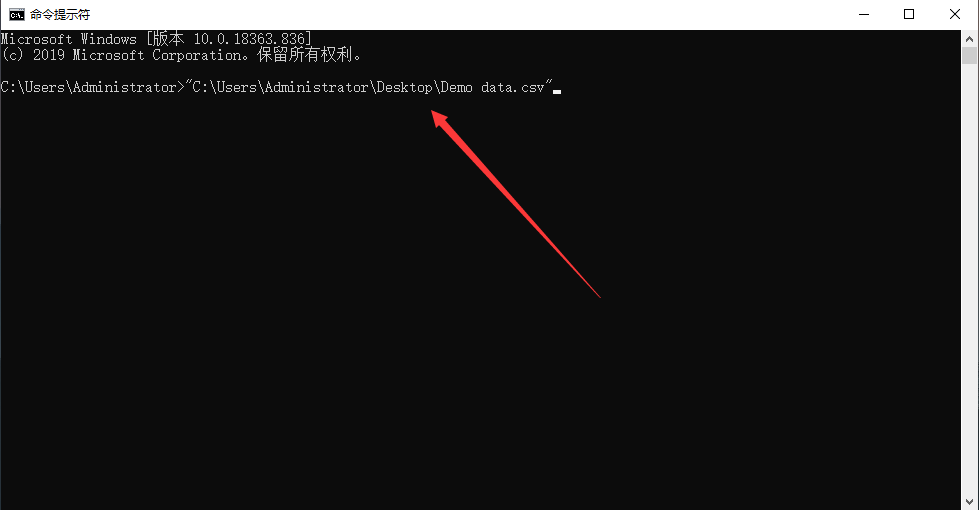
也许你还注意到,文件路径是用单引号包含起来的,这是通用的写法;此外,在引号的左侧出现了字母 r,它是用来转义的,也就是说没有字母 r,这行代码就实现不了数据读取,也就是 pd.read_csv( ) 不能识别括号中的路径。这是什么原因呢?如果你有兴趣,可以网页查询一下,这里就不再解释,因为这不是学习的重点,我们会用它就好了。
数据读取涉及的代码讲解完了,很简单的样子,那接下来需要你将上述两行代码逐个敲进 Spyder 中,注意不要偷懒复制啊,刚开始一定要敲一敲,更有感觉,代码如下:
# 导入 Pandas 包
然后,点击工具栏的开始按钮,或者直接快捷键 F5,之后你会在变量区发现数据已经被载入了。

可以看到变量区从左至右依次显示了:变量 data,数据类型是 DataFrame,大小是(1000,3),值「列名称」含速度、加速度和车头间距。
好了,到这里我们就实现了数据集读取的目标了,只是两行代码,并且这个代码可以反复利用,你只需要修改文件的路径即可。但也许注意,这个代码仅适应于 CSV 文件格式的,其他格式的也有相应的代码,不过更推荐使用 CSV 格式。
2.3 选取数据集中的列
在读取数据集之后,我们不必着急去数据分析。因为,往往我们在开始数据分析之前,需要学会如何任意地去选择数据集中的部分数据,这很重要。因此,让我们放慢节奏慢慢来。
我们已经知道导入的数据集包含三列,现在需要将三列数据单独分配给指定的变量,以供后边使用;但这不是必须的。请看以下代码:
# 变量赋值
注意,我们的代码是连续的,现在的代码是紧跟在之前的两行代码之后的。与数据读取类似,这里是将数据集中的每一列分别赋给对应的变量,比如第一行代码:data [' Speed '] 表示选取数据 data 中的 Speed 所在列的所有数据,添加 = 符号之后,就是将其赋值给 s。也就是说,运行代码后,s 便表示 速度整列数据,后两行代码同理。
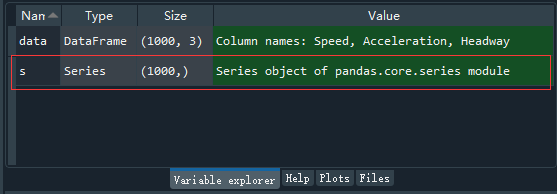
此时,可能有些同学有疑问了,如果要是只想选择某列的前几行,或者中间的任意行呢?这个也很好办,先看以下代码:
# 变量赋值
注意,为了区分变量,这次将速度所在的列命名为大写的 S,这也就告诉我们 Python 是区分大小写的。同样,我们来逐个代码分析:data.iloc[ ].values 这个代码表示要索引某个位置(.iloc[ ])的值(.values),具体到代码来说就是 data.iloc[0:4, 0].values 表示要索引数据 data 的第 0~4 行和第 0 列的交集,说白了就是第 0 列的前 5 行。
注意,可能你发现序号是从 0 开始的,这就是 Python 的与众不同之处,它是从0开始计数的,0~4 行表示真实数据表的 1~5 行,这个大家要慢慢习惯。
那么,上述代码就显而易见了,就是将第 0 列(真实的第 1 列)中的前 5 行赋值给变量 S,第 1 列是速度。通过调整方括号中的数字,便可以实现选取任意数据的目的了。
2.4 简单的描述性统计分析
Python 支持我们常见的运算符直接运算,所以通过上述变量赋值,便可以实现我们想做的众多数据分析任务。这里先不谈更加深入的数据挖掘,我们先简单实验一下如何快速的对数据集进行描述性统计。
还是以我们开始利用的数据 data,我们拿到数据之后,往往第一步是对数据做简单的描述性统计,以观察数据的大致分布。而常用的,一般是 Pandas 包中的一个方法:.describe (),这个代码可以快速得到统计结果,代码如下:
# 导入 Pandas 包
这个数据结果就不用过多解释了,它太容易看懂了。以此为起点,大家可以去深入挖掘 Pandas 包的各种用法吧!记住,实践出真知,动手才能学会!
3 让我们绘制一些漂亮的图片吧
分析数据可能在一开始是非常枯燥的,因为你难以看到直观的结果,对自己的激励作用就不是很明显。那么,就让我们来利用 Python 做一些可视化工具吧,这样我们可能更有兴趣学下去。
正如数据处理环节需要利用 Pandas 包一样,绘图也有专门的包,它叫做:matplotlib,这也上一节我们已经大致介绍过。现在就直接来用它吧,不用担心对它还不是很了解,在实践中掌握是最好的方法啦。
我们要想实现绘制图片的目的,前提是要有数据,所以前边我们做的工具就非常有必要了,现在我们把前文写的代码汇集到这里:
# 导入 Pandas 包(主要用于处理数据表格)
与之前的策略相同,我们在开始绘图之前需要导入相应的包,于是我们不仅要导入 Pandas 来处理数据,还要导入 matplotlib 包来绘制图像。因此,我们将代码列举如下:
# 导入 matplotlib 包(主要用于绘制图像)
注意,这个单独并不能单独写,这样它就没有意义了,需要与上一个代码框中的一起搭配使用。这行代码表示将 matplotlib 中的绘图模块 .pyplot 导入到程序中,并称它为 plt,后边再用这个库的模块时,只需要引用 plt 即可。这只是一种简略写法,没什么特殊含义。
此外,让我们一起来思考一下绘制图像需要解决哪些问题。
选择基础数据
设置画布大小
绘制折线图
调整线型、粗细、颜色、标签
添加横纵轴标题
添加图标题
添加图例
保存指定分辨率的图片
看似很简单的绘图问题,如果你细分起来,你会发现涉及的问题非常之多,上边只是列举了主要的操作,精细的绘图会需要更多的步骤来完成。但不要气馁,类似的绘图,只要你写好一个,今后就只用替换相应的数据就行了,代码可以不动,这就是编程的优势。
3.1 准备工作
现在,假设我们需要绘制加速度随时间变化的时间序列图像。那么,我们需要确定两个关键问题:第一,绘制时长是多少;第二,选择对应时长的加速度数据。
我们假设本文使用的数据记录间隔是 0.1 秒,现在需要绘制前 100 秒的加速度。根据前边的讲述,我们很容易将前 100 秒的加速度数据挑选出来,代码如下:
# 选择前100秒的加速度数据
注意:0:999 表示的是前 1000 行的数据,再记忆一下,Python 是从 0 开始计数的,因此不能写作 1:1000;所以后边的 1 表示的是数据表中的 第 2 列。也就是说,将数据表中第 2 列 的前 250 个数据点赋值给 A 保存,不要忘记时间间隔是 0.1 秒。
3.2 绘制图像
现在我们将绘图需要的加速度数据准备好了,可以开始绘制折线图了,先把代码和运行结果放在下面:
#设置画布的尺寸
显然,上述代码非常容易看明白,每行代码开头均为 plt,表示使用了 matplotlib 包中的绘图模块 .pyplot。第一行代码表示设置画布大小,只有先设置画布,才能在画布上绘图,这与我们日常的逻辑是一致的,不要深究代码为何这些写,只要记住括号中的数字表示画布的长和高即可。
第二行更为简单,plot 单词本身含义就有绘图的意思,这个更加直白,就是将数据 A 绘制成折线图,甚至横轴时间我们都不用输入,它会自动匹配。
第三行代码表示将绘制的图像显示出来,注意这一行必须要有,不然代码运行后什么也没有。
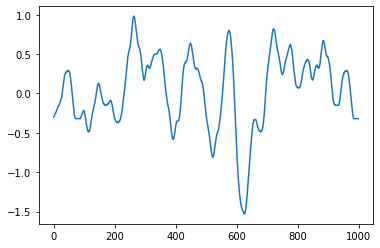
3.3 美化图像
基本的图像已经绘制出来了,但是你可能发现了,缺少了必要的横纵轴标题、图标题等等信息,并不是特别美观。因此,我们希望加上之前提到的信息,以美化图像。同样,我们先来看一下实现的代码:
# 绘制折线图,并适当美化图像
第 1 行代码中:lw 表示线宽,它是 line width 的缩写;ls 表示线条的风格,比如实线、虚线、点划线等;c 表示线条的颜色;label 表示线条的标签,图例显示的便是该标签。
第 2~3 行代码中:plt.xlabel 表示为 X 轴添加标题;plt.ylabel 表示为 Y 轴添加标题。
第 4 行代码中:.title 表示为整个图像添加标题,在图像的上方。
第 5 行代码中:.legend 表示为图像添加图例;而其中的 loc=1 则表示图例的位置,它是 location 的缩写。1 表示 图例位于图像的右上方,2、3、4 依次为逆时针旋转的位置(各个角),大家可以试试。
经过这几行代码,我们便实现了对图像基本的美化,添加了相应的属性,效果如下:
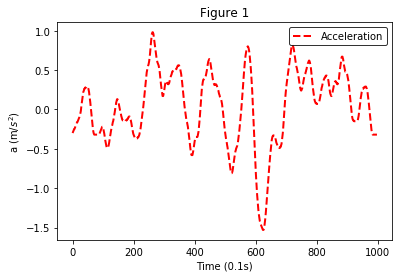
3.4 保存图片
虽然现在绘制的图像还不是特别的完美,但学到这里就够了,先停下来消化一下学习的代码,更加复杂的绘图操作放到今后需要的时候再学习吧。
那么现在,我们还差最后一步就可以完成这个实践项目了,就是把绘制的图像以指定的格式、分辨率保存一下。因此,在我们写作论文投稿时,杂志社往往会要求提供原始的图像,并规定有分辨率。下面我们以提供 TIFF 格式、分辨率 300 dpi 的图像为例,来学习一下如何保存为特定格式的图像:
# 保存图片
这行代码就是实现我们所说功能的代码了,plt.savefig 表示保存图像到指定路径、设置分辨率等;r 之后的路径我们应该已经很熟悉了,就是指定保存的位置,最好不要有中文。dpi 表示要设置的分辨率,后边 300 便是要设置的数值;最后一项 bbox_inches 表示是将保存的图像更加紧凑一些,截取过多的白色区域。
好了,让我们回过头来将绘制图像的整个过程代码整理到一块,运行一下吧!
# 导入 Pandas 包(主要用于处理数据表格)

这张图像变化了很多内容哦,注意观察一下代码中的变化,自己再去试试吧。比如:尝试调整一下数字或标题的字体、字号、刻度显示的间隔等等......
此外,由于每期分享的内容大多都包含有相应的资料、数据或软件等,这些都在公众号中的原文里给出了相应的链接,大家如有需要,可自行了解。















 260
260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









