






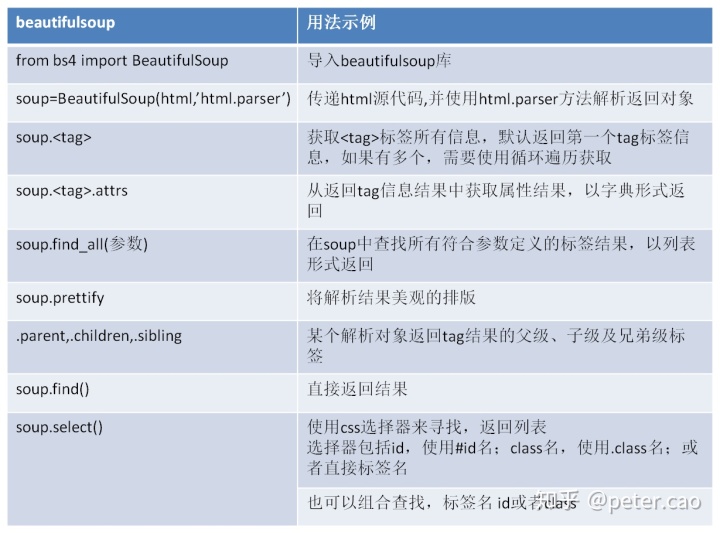
爬虫常规技术:Requests+BeautifulSoup
用python来进行爬虫有许多方法,同时有许多第三方库,也就是python社区开源的库可以使用。我们先来介绍常规爬虫方法,即使用第三方库Requests和BeautifulSoup。Requests库是用于发送请求,获得网页源代码;BeautifulSoup用于对源代码进行解析,在源代码中精确定位获得所需的信息。本篇内容较多,不过都是实用之言,还请耐心往下阅读。
(1)熟悉网页HTML代码和HTTP请求
这是最最基础知识,爬虫就是对网站内容进行爬取,所以先要认识网页是怎么构成的,如果还不熟悉,可以百度一下,或者参考本专栏之前的文章:
peter.cao:WEB/APP开发基础之旅--HTML入门1zhuanlan.zhihu.com

同时还需要知晓HTTP协议及常见的请求方式:
peter.cao:WEB/APP开发基础之旅--HTTP协议简介zhuanlan.zhihu.com
(2)安装第三方库Requests+BeautifulSoup
requests是一个第三方库,也就是其他开发人员使用python自行研发后开源贡献出来的库,而不是python官方自己研发的内置模块。下面是requests库的介绍和使用文档,大家可以参考。
快速上手 - Requests 2.18.1 文档requests.kennethreitz.org上述requests库主要作用是给网站发送HTTP请求,如果请求反馈状态成功,则可以获得网站对应页面的源代码;如果是请求的API,则可能获得网站某个页面的json数据。我们知道网页源代码就是各种HTML标签和CSS样式代码构成,在网页头部或者尾部会有一些JAVASCRIPT脚本。这种内容距离我们想爬取某个数值或者某个区域的内容还比较远,也就是后面我们是需要从这个源代码里精确定位到某个DIV或者某个标签,进而取得其中的文本值。BeautifulSoup库就可以用来达到这个目标,该库也是一个第三方库,主要用于对HTML代码进行解析。翻译成中文就是漂亮的汤,很有意思的名字。由于这两个库都是第三方库,因此在使用时首先都需要下载安装。Python对于第三方库的安装非常简便,直接使用其内置的pip install命令就可以完成。不过有些第三方库受限于国内GK的缘故,有的时候下载会出现问题,所以还需要使用国内的镜像站点。幸好这两个库可以正常下载安装,无需担忧了。
安装这两个库,安装时启动window系统自带的命令行窗口,即cmd窗口,然后在弹出的命令行里输入:pip install requests,如下窗口:
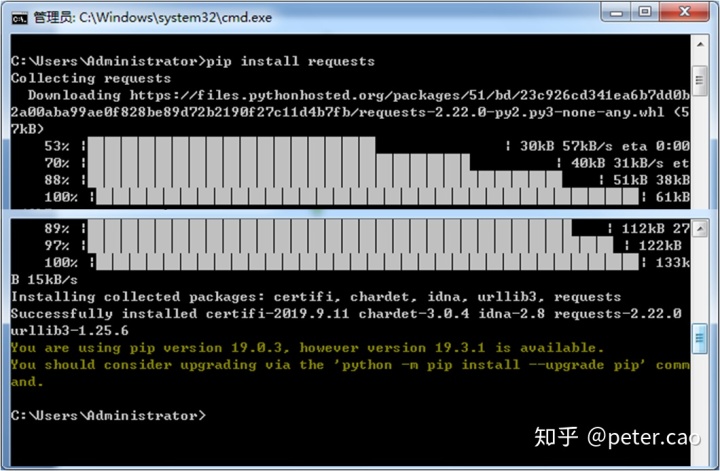
系统会自动下载requests库并安装到本地磁盘上。
同样的方法来安装BeautifulSoup,此时在cmd命令行需要输入:
pip install beautifulsoup4两个第三方库都下载安装后,接下里就可以在python编辑器中开始使用了。
(3)如何理解requests库?
requests库安装路径默认会在python安装目录下的Lib/site-packages里,目录如下:
可以看到都是一些py文件,打开其中的_init_.py初始化文件,如下源码:
# -*- coding: utf-8 -*-
内容比较多,我们重点关注注释部分的用法说明和靠底部的导入方法。首先来看用法说明:
>>> import requests
>>> r = requests.get('https://www.python.org')
>>> r.status_code
200
>>> 'Python is a programming language' in r.content
True
... or POST:
>>> payload = dict(key1='value1', key2='value2')
>>> r = requests.post('https://httpbin.org/post', data=payload)
>>> print(r.text) 这里介绍了requests的两种http请求方法:get和post。之前讲HTTP协议的时候介绍过,get请求是从服务器网址获取数据,post请求是往服务器发送数据。因此在requests库使用get方法时,默认只需要传递一个网址url即可,然后返回一个response对象,通过调用这个response对象的content方法就可以获得网页的源代码;使用post方法时,需要首先封装一个数据容器,如说明中使用字典容器,然后在requests的post方法中给定请求的url地址和数据容器,执行后也会返回一个response对象。
源码中靠底部的导入方法代码如下:
from . import utils #导入工具
from . import packages #导包
from .models import Request, Response, PreparedRequest #导入响应模型
from .api import request, get, head, post, patch, put, delete, options #导入各种请求方法
from .sessions import session, Session #导入session
from .status_codes import codes #导入状态码用之前介绍过的module模块使用方法,对比requests包的目录文件,就可以看明白from .api import request,get,post等导入请求方法的代码,说明这些方法都写在api文件中,如果想搞清楚这些方法的源代码,就可以打开api文件来查看,这里截取get方法如下:
def get(url, params=None, **kwargs):
r"""Sends a GET request.
:param url: URL for the new :class:`Request` object.
:param params: (optional) Dictionary, list of tuples or bytes to send
in the query string for the :class:`Request`.
:param **kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
kwargs.setdefault('allow_redirects', True)
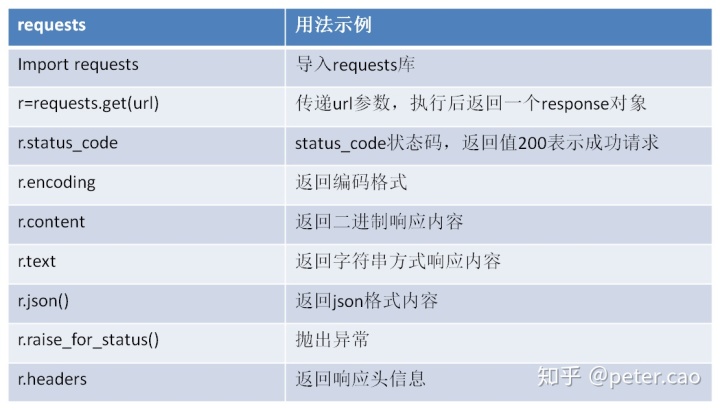
return request('get', url, params=params, **kwargs)有兴趣的可以去研究一下过程。这里我们先搞定get方法获取网页内容,主要使用方法总结如下:
(4)使用requests案例
简单爬取网页代码,以http://pypi.org网站首页为例:
那接下来就在Anaconda的spyder模块中开始编写代码,用一个实例说明获得网页源代码的过程:
# -*- coding: utf-8 -*-
"""Created on Mon Oct 28 22:00:10 2019
@author: caojianhua
"""
import requests
#编写一个函数用于获取HTML源代码
def getHtml(url): #构建一个函数用于获取网页的源代码
r=requests.get(url) #使用get请求,返回response对象
print(r.status_code) #查看请求的状态码
print(r.text) #查看字符串形式的源代码
print(r.headers) #查看响应头信息
url='https://pypi.org/' #给定url地址,这里给的是pypi官方网站,也就是python第三方库官网
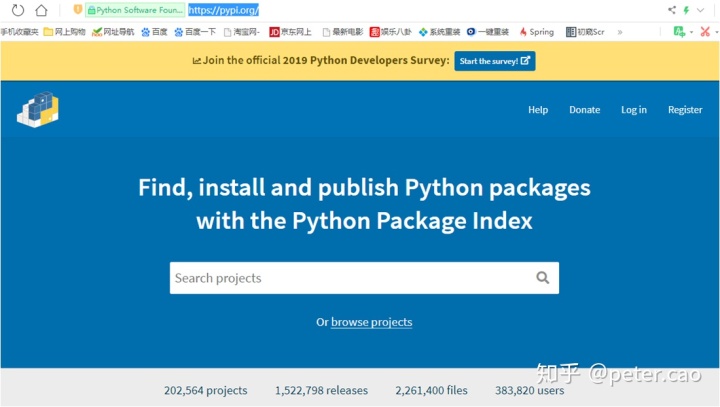
getHtml(url) #调用函数执行程序当执行程序后,在控制台shell中就会打印出爬虫结果。由于pypi网站首页HTML代码行数过多,这里无法显示完全,仅仅截取其中一部分。如下为四个段落中的内容:
<div class="horizontal-section horizontal-section--grey horizontal-section--thin horizontal-section--statistics">
<div class="statistics-bar">
<p class="statistics-bar__statistic">202,564 projects</p>
<p class="statistics-bar__statistic">1,522,810 releases</p>
<p class="statistics-bar__statistic">2,261,420 files</p>
<p class="statistics-bar__statistic">383,820 users</p>
</div>
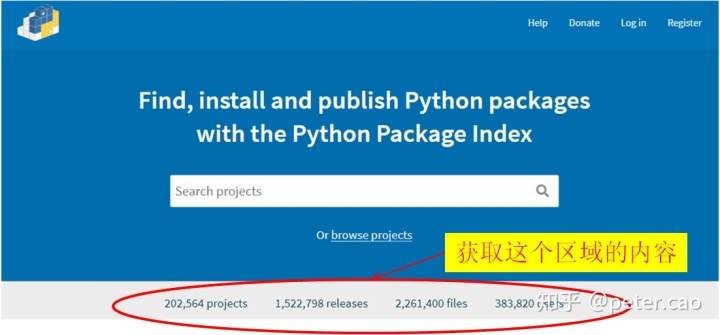
</div>如下为pypi官网截图,上述代码正好为截图底部四组数据的源代码:
为了使得爬取过程显得更加完整和健壮一些,我们加入异常处理代码:
import requests
#获取HTML源代码
def getHtml(url):
r=requests.get(url)
try:
r.encoding=r.apparent_encoding #赋予response对象编码
r.raise_for_status() #检查是否存在异常,如果有异常,直接跳出
html=r.text #将response的text赋值给html参数
headers=r.headers #将response的headers信息赋值给headers参数
except:
print("error")
return html,headers #返回html和headers参数
url='https://pypi.org/'
html,headers=getHtml(url) #获取爬取该url的html代码和headers信息
print(html) #打印查看HTML代码加入用户代理爬取较为复杂的网站,以查询IP所在地址的IP138网站为例
有关requests的get基本用法如上介绍,实际在爬取网站过程中,还需要修改用户代理。如果采用上述代码来获取源代码,在给对方服务器发送请求的时候是使用python代码和环境来发送的,有些网站是不接受这种请求方式的,而只允许从浏览器地址栏上输入url来发送http请求。也就是只接受使用浏览器软件来实现http请求,由此避免有些软件来恶意爬取。这种情况下就需要在上述代码中加入user-agent参数,让python代码模拟浏览器发送http请求。
例如在上述代码将url修改为查询IP地址的网站地址:http://www.ip138.com/后返回结果就出现了异常,无法正常连接。
ConnectionError: HTTPConnectionPool(host='sewer.ip138.com', port=80): Max retries exceeded with url: / (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x094345D0>: Failed to establish a new connection: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。'))此时需要设置一下用户代理,前面说到让python代码模拟浏览器进行访问,一般浏览器访问网站时其响应头有一行是浏览器信息:
User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36其中Mozilla/5.0支持IE浏览器,Chrome为谷歌浏览器,后面的为苹果浏览器。
将这一行信息加入到python爬虫代码中,就可以模拟浏览器访问了,代码如下:
# -*- coding: utf-8 -*-
"""Created on Mon Oct 28 22:00:10 2019
@author: caojianhua
"""
import requests
#获取HTML源代码
def getHtml(url):
headers={"user-agent":"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"}
r=requests.get(url,headers=headers) #增加响应头参数,用户代理
try:
r.encoding=r.apparent_encoding
r.raise_for_status()
html=r.text
headers=r.headers
except:
print("error")
return html,headers
url='http://www.ip138.com/'
html,headers=getHtml(url)
print(html)再来执行,就可以顺利获取HTML源代码了。同样由于HTML行数较多,这里截取一部分显示,主要是该网站查询入口处代码:
<div class="module mod-ip">
<h3>www.ip138.com iP查询(搜索iP地址的地理位置)</h3>
<iframe src="http://2000019.ip138.com/" rel="nofollow" width="100%" height="80" frameborder="0" scrolling="no"></iframe>
<form method="get" action="ips138.asp" target="_blank" name="ipform">
<p> 在下面输入框中输入您要查询的iP地址或者域名,点击查询按钮即可查询该iP所属的区域。
</p>
<p>
<label for="ip">iP地址或者域名</label>
<input class="input large-input" id="ip" type="text" name="ip" size="16"/>
<input type="hidden" name="action" value="2"/>
<input class="btn" type="submit" value="查询"/>
</p>
<p>
<a class="red" href="http://user.ip138.com/ip/lib/" rel="nofollow" target="_blank">离线iP数据库</a>
<a class="blue" href="http://user.ip138.com/ip/" rel="nofollow" target="_blank">iP查询接口</a>
<a class="green" href="https://www.chajiechi.cn/" target="_blank">劫持检测</a>
</p>
</form>
</div>其对应的网页截图如下:

爬取搜索引擎,url后加参数爬取,以百度搜索为例
前面几个案例都是获得对应网页的源代码。有的时候还希望获得表单输入后的执行结果,如百度搜索,在搜索栏输入关键词后,点击搜索按钮后会出现许多关联的结果。对于这种情况,我们只需要知道其url结构,就可以使用上述方式来爬取。
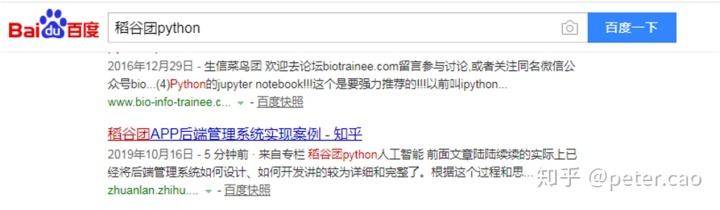
例如我们对百度搜索加关键词进行爬取,值得注意的是这个时候一定去看搜索时url如何构建。如我在百度搜索栏输入稻谷团python关键词,第三个搜索结果就是我的专栏。
这个是如何实现的呢?此时我们要在该页面打开网页开发者工具(键盘上使用F12),选择network栏,然后按F5刷新,此时该区域显示网页所有文件加载渲染过程。选择name列的第一项,点击headers,如下图:
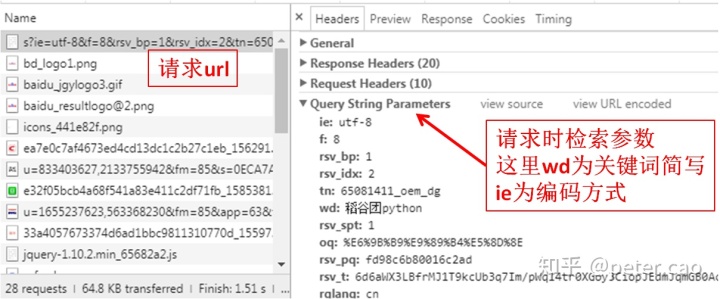
在general选项中看到request url为:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=2&tn=65081411_oem_dg&wd=%E7%A8%BB%E8%B0%B7%E5%9B%A2python&rsv_spt=1&oq=%25E6%259B%25B9%25E9%2589%25B4%25E5%258D%258E&rsv_pq=fd98c6b80016c2ad&rsv_t=6d6aWX3LBfrMJ1T9kcUb3q7Im%2FpWq14tr0XGoy3CiopJEdmJqmGB0AcwMzZhKHn5REoSMrje&rqlang=cn&rsv_enter=1&rsv_dl=tb&inputT=7382&rsv_sug3=9&rsv_sug1=4&rsv_sug7=100&rsv_sug2=0&rsv_sug4=20397&bs=%E6%9B%B9%E9%89%B4%E5%8D%8E根地址为:https://www.baidu.com/,紧接着为s+问号,这里s是search的简写,问号是get请求带参数的一种方式,如https://www.baidu.com/s?ie=utf-8&&wd=python,这里get请求包括了两个变量参数,ie和wd,两者通过&&连接起来,ie默认给值为utf-8,wd为关键词缩写,就是百度输入框所输入的值。由此分析得出,如果我们要通过爬虫方式来进行百度搜索,而不是打开浏览器进入百度首页进行搜索,只需要按照这种url构建方式就可以完成。接下来我们来测试一下,同样适用搜索关键词为稻谷团python:
# -*- coding: utf-8 -*-
"""Created on Mon Oct 28 22:00:10 2019
@author: caojianhua
"""
import requests
#获取HTML源代码
def getHtml(url):
headers={"user-agent":"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"}
r=requests.get(url,headers=headers) #增加响应头参数,用户代理
try:
r.encoding=r.apparent_encoding
r.raise_for_status()
html=r.text
headers=r.headers
except:
print("error")
return html,headers
wd='稻谷团python' #给定搜索关键词
url='https://www.baidu.com/s?ie=utf-8&&wd='+wd #构建请求url
html,headers=getHtml(url) #调用getHtml函数,获得该页面的html代码
print(html)运行后部分结果代码如下:
<em>稻谷团</em>APP后端管理系统实现案例 - 知乎</a></h3>
<div class="c-abstract"><span class=" newTimeFactor_before_abs m">2019年10月16日 - </span>
5 分钟前 · 来自专栏 <em>稻谷团python</em>人工智能 前面文章陆陆续续的实际上已经将后端管理系统如何设计、如何开发讲的较为详细和完整了。根据这个过程和思...</div>
<div class="f13">
<a target="_blank" href="http://www.baidu.com/link?url=fJKL_Eo5hdGojfBzE-Nd_dVb0MrlTEr4-YJqg-ypLsBc-1hSzi4RiPJ1e4W6KPXNsXkSMwG72-m1sDdpMXOpd_" class="c-showurl" style="text-decoration:none;">zhuanlan.zhihu.... </a>
<div class="c-tools" id="tools_17324754045571694576_1" data-tools='{"title":"稻谷团APP后端管理系统实现案例 - 知乎","url":"http://www.baidu.com/link?url=fJKL_Eo5hdGojfBzE-Nd_dVb0MrlTEr4-YJqg-ypLsBc-1hSzi4RiPJ1e4W6KPXNsXkSMwG72-m1sDdpMXOpd_"}'>
<a class="c-tip-icon"><i class="c-icon c-icon-triangle-down-g"></i></a></div><span class="c-icons-outer"><span class="c-icons-inner"></span></span> - 到此为例,requests库的get请求方法主要内容就介绍完了。有关post请求或者其他http动作后续我们再讨论。接下来的任务就需要交给beautifulsoup库完成精确定位了。
(5)理解BeautifulSoup库
BeautifulSoup美味汤,名字挺有味。使用起来也很方便。由于其_init文件代码较长,这里不便于展示。不过在同一个site-packages里发现有cssselector也安装了,随着beautifulSoup一起安装的。后面我们可以使用。
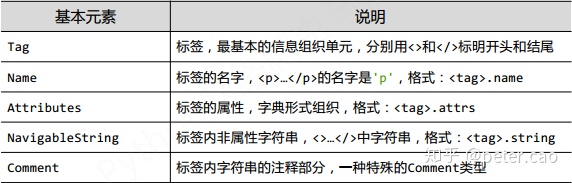
Beautifulsoup库使用的时候先将HTML源代码作为参数,然后加入html.parser参数,也就是对html源代码进行解析,返回一个解析对象。然后来调用该对象的一些方法实现网页内容的精确定位。在定位时就需要使用到HTML标签的一些基本构成元素。如下表:
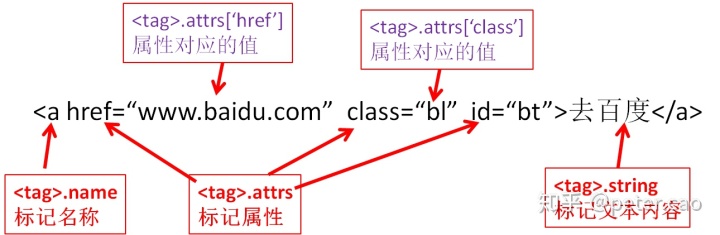
也可以用一张图来说明标签基本构成:
我们可以将该库的使用方法示例总结如下:
(6)Requests+BeautifulSoup库综合使用案例
这两个库要结合在一起使用,requests可以获取目标网页的源代码,然后使用beautifulsoup进行解析。接下来我们以两个案例说明综合使用方法。
第一个案例,想知道在http://pypi.org官网上目前有多少个python第三方库,有多少注册用户。该案例与前面requests获取官网首页源代码例子是一致的,我们需要在获取了源代码基础上进一步抓取到内容。即目标如图:
首先使用requests库获取该页面的源代码,也就是上面使用过的getHtml(url)函数,其返回结果即为页面源代码,然后在构建一个getString(html)函数,将上一步的输入作为参数,其中使用beautifulsoup来解析html,并通过css选择器定位到目标区域,获得具体的内容并以列表返回。最后在主函数中调用并打印结果。代码参考如下:
import requests
from bs4 import BeautifulSoup #导入BeautifulSoup库
def getHtml(url): #定义该函数获得目标url的HTML代码
headers={"user-agent": #设定用户代理
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/63.0.3239.132 Safari/537.36"
}
r=requests.get(url,headers=headers) #使用requests库的get方法,给目标url发送get请求
try:
r.encoding=r.apparent_encoding
r.raise_for_status() #如果无法连接将抛出异常
html=r.text #获得字符串形式源代码
except:
print("error")
return html #将获得的源代码返回
def getString(html): #构建函数获得目标区域的内容
soup=BeautifulSoup(html,'html.parser') #使用BeautifulSoup库对源代码解析,返回解析对象
results=soup.find_all("p",class_="statistics-bar__statistic") #使用find_all方法精确定位到目标区域
return results #以列表形式返回目标区域内容
if __name__=='__main__': #构建主函数main
url='https://pypi.org/' #给定爬取的网页地址
html=getHtml(url) #调用爬取网页源代码函数获得HTML代码
results=getString(html) #调用解析网页函数获得内容列表
for item in results: #遍历内容列表并输出
print(item.string)在Spyder中运行该代码,在控制台输出如下内容:
202,591 projects
1,522,959 releases
2,261,834 files
383,864 users这些正好是前面目标区域的内容,由此而获得了目前一共有20多万个第三方库,38万注册用户。
使用beautifulsoup库来解析网页时,上述代码中使用的是soup对象的findall()方法,并采用选择器和css来定位,即find_all('p',class_='statistics-bar__statistic'),定位到p段落标记,并使用css来精确定位,即寻找所有具有class名为statistics-bar_statistic的段落标记内容。找到后find_all()方法会返回一个列表对象。在主函数中访问遍历对象的string属性即获得了目标内容。也可以使用soup对象的select方法,可以写为:
soup.select('.statistics-bar__statistic') #选择类名为statistics-bar__statistic的标记
soup.select('p.statistics-bar__statistic') #使用标签名+class名组合来定位这两种方式都可以获得最终需要的结果。
第二个案例,使用那个IP138查询网站获取输入IP后的响应结果。也就是通过编写程序获得IP138查询服务,并最终获得结果,而不是访问其网站。
这里首先需要构建一下查询服务的url,具体方法参考前面百度查询构建的方法。这里先打开ip138网站,在输入IP地址那输入一个ip地址,点击那个查询按钮后,会跳出一个新页面,这时注意观察新页面浏览器地址栏的url地址,变成了http://www.ip138.com/ips138.asp?ip=106.13.111.246&action=2。使用开发者工具查看network栏,第一项name发现也是这个request url信息,说明该网站查询时url就是这样构建的,根目录www.ip138.com,子页面为ips138.asp,加参数时使用?问号,参数1为ip,值就是输入的ip地址,参数2为action,值为2。因此在爬虫时构建url地址就可以采用这种方式,将ip地址作为变量等待输入。再仔细查看一下搜索的结果以及对应的HTML代码块如图:
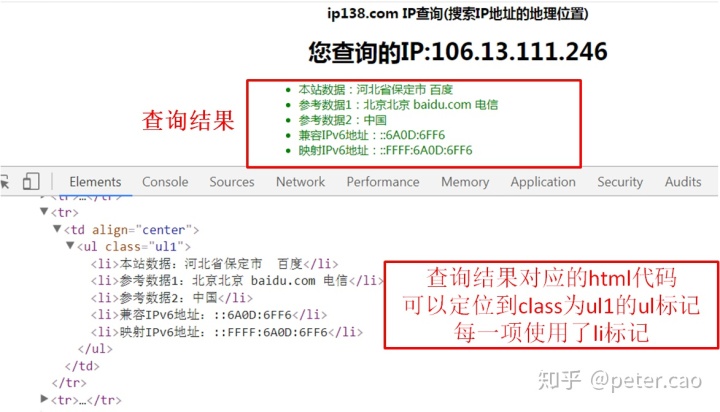
这样也奠定了我们后续使用beautifulsoup库解析网页代码的方式,可以使用select方法,也可以使用find_all方法,如find_all('ul li')或者select('ul li')。即查找所有ul标签下的li标记。具体代码参考如下:
"""Created on Mon Oct 28 22:00:10 2019
@author: caojianhua
"""
import requests
from bs4 import BeautifulSoup
def getHtml(url):
headers={"user-agent":
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/63.0.3239.132 Safari/537.36"
}
r=requests.get(url,headers=headers)
try:
r.encoding=r.apparent_encoding
r.raise_for_status()
html=r.text
except:
print("error")
return html
def getString(html,tag): #构建一个函数获取内容,tag为目标区的标记、或者标记与css组合
soup=BeautifulSoup(html,'html.parser')
results=soup.select(tag) #使用select方法解析网页,给定tag选择参数,返回解析结果
return results
if __name__=='__main__':
ip=input("输入您想查的ip地址:") #提示输入ip地址
url='http://www.ip138.com/ips138.asp?ip='+ip #构建查询的url
tag='ul li' #确定目标区的标记组合
html=getHtml(url) #获得查询后的网页源代码
results=getString(html,tag) #获得查询目标内容区
for item in results: #遍历目标内容文本,打印每一项
print(item.string)从如上两个案例实践来看,使用requests+beautifulsoup组合能够爬取到我们想要的内容,而且上述代码中两个函数通用性还很强,只需要在main函数中给定目标url和目标区tag标记组合,就可以获得结果。这样就可以将整个处理过程写成module模块,以便后续抓取其他网站时使用。同时在实践过程中估计大家也能体会到两点认识,第一就是爬虫也就是使用软件编程来获取网页内容,这是一种便利的数据采集方式,而不是在浏览器中去访问获取内容,毕竟浏览器上只能浏览。后续我们再讨论让数据保存成文件或者保存到mongodb数据库中。第二点就是使用这个组合方式在Python中运行时速度还是有点慢的,对于某些频繁变化内容的网站肯定不适用。所以本文标题定为常规爬虫技术,后续再讨论其他爬虫技术。















 3145
3145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









