





- Oracle11g 安装 (B级)
参照以下网址:
• http://blog.csdn.net/u013047660/article/details/20660215
• http://blog.sina.com.cn/s/blog_1378be1bc0102v334.html
• http://www.cnblogs.com/sunada2005/articles/2687301.html二. Oracle11g 卸载(B级)
参考以下文档:
• http://blog.sina.com.cn/s/blog_6a24a6de01015xl7.html
• http://blog.csdn.net/pan_tian/article/details/9272089
• http://www.2cto.com/database/201501/369060.html
• http://blog.sina.com.cn/s/blog_6a24a6de01015xl7.html- 关于Oracle (B级)
• A、数据库的版本
• Oracle 8及8i:i表示的internet,向网络发展,过渡版本,只有一张vcd。8i是过渡性品。
• Oracle9i:是现在使用最广泛版本,8i的升级版。1CD
• Oracle10g:700M过渡性产品,其中g表示的是网格计算。以平面网格,以中心查找。
• Oracle11g:完整性产品,最新版本2G。
• Oracle12c:the world's first database designed for the cloud• B、安装的Oracle注意点:
• 1)、关闭防火墙
• 2)、断开网络• C、用户
• 1)、sys 超级管理员 bjsxt
• 2)、system 普通管理员 bjsxt
• 3)、scott 普通的用户 tiger• D、实例 -->数据库
• E、数据库实例名 统一使用orcl
• gzsxt
• scott -->tiger*未来会见到的项目架构模型:
Html,css,javascript java(servlet,spring,mvc,struts2,hibernete,mybast(等等)) -
Oracle,mysql- Oracle 服务及查询命令 查看PPT课件 02_oracle
- 远程连接 Oracle 、创建 Oracle 实例 查看PPT课03_oracle
- Oracle 遇到的问题 查看PPT课件 04_oracle
*七.别名、去重distinct (A级)
A)为表添加注释:
---Commnet on table emp is ‘雇员表’;
或者可以在软件里面手动添加和修改(找到对应的表-点击鼠标右键-选中edit进入界面-在general的界面中找到comments进行添加和修改)B)为列添加注释:
---comment on column emp.Empo is ‘雇员工号’;
C)select--from--where 句型:
Select [distinct] {*,column alias,....}
From table alias
where 条件表达式D) Alias (别名) 命名的三种方式:
1)column alias (非文字类命名推荐使用,用英文字母命名时会自动转换为大写)
2)column “alias” (文字类或对命名有严格要求大小写等推荐)
3)column as alias (同1)E)检索列有以下几种:
1) select col from tableName(表名) (单个列)
2)select col1,col2,col3 from tableName (多个列)
3)select * from tableName (所有列)
使用通配符(*)的优点:书写方便,可以检索未知列
使用通配符的缺点:降低检索的性能
注意:只查询固定列数据的时候,建议不要使用“*”,效率低F) distinct (去重) 关键字
distinct必须放在开头
用于多字段时,每个字段不一样才去重Where条件(A级)
- 条件比较:
– =,!=,<>,<,>,<=,>=,any,some,all
– is null,is not null
– between x and y
– in(list),not in(list)
原理:
Where(记录){
If(sal==800)
{
Syso();
}
If(sal==2200)
{
Syso();
}
.......
}
– exists(sub-query)、not exists(sub-query)
原理:
while(emp所有记录){
while(dept所有记录){
If(true){
syso()....
break;
}
}
}
– like _ ,%,escape ‘‘ _% escape ‘’
条件表达式中字符串匹配操作符是‘like’
%通配符 表示任意字符出现次数
_通配符 表示任意字符出现一次
注意:不能过度使用通配符。如果其他操作符能达到目的,就不要使用通配符
确实需要使用通配符时,除非绝对必要,否则不要把通配符用到搜索模式最开始处,因为这样搜索起来是最慢的
2.逻辑复合条件
->优先级:not > and > or
->计算次序问题的解决,最好用括号进行分组处理
3)sql优化问题:
and:把检索结果较少的条件放到后面
or:把检索结果较多的条件放到后面重要语法(A级)
order by 查询结果排序
order by col asc(升)/desc(降) (单个列排序)
order by col1 asc(desc),col2 desc(asc) (多个列排序)
instersect 交集
union all 全集
union 并集
minus 差集
函数 (A级)>函数分为:组函数(聚合函数)和单行函数
-->单行函数有以下几种:
a)字符函数
- 含义:字符函数全以字符作为参数,返回值分为两类:a)返回字符值
b)返回数字值
关键字:
–concat(string1,string2) 连接两个字符串 ||
–initcap(string) string中每个单词首字母大写
–Lower(string) 以小写形式返回string
–lpad,rpad 填充字符型数据
–ltrim/rtrim (string1,string2) 去除左/右两端对应的字符
–trim(A from B) 去除两端对应的字符
–Substr() 提取字符串的一部分substr(string,1,2)
1对应字符所在的位置(index),2->对应提取的长处(java中是从0开始,Oracle中是从1开始)
–upper(string)以大写形式返回string
–Instr()字符串出现的位置, instr( string ,’A‘)
–Length()字符串长度b)时间函数
语法:
select current_time() from dual mysql:时间
select current_date() from dual mysql:日期
select current_timestamp() from dual mysql:日期时间MySQL有关的网址:
http://dev.mysql.com/doc/refman/5.7/en/date-and-
time-functions.html#function_str-to-date
• http://dev.mysql.com/doc/refman/5.7/en/date-and-
time-functions.html#function_date-format
• http://dev.mysql.com/doc/refman/5.7/en/
• http://dev.mysql.com/doc/refman/5.7/en/cast-functions.html#function_convertc)数字函数
- 定义:数字函数以number类型参数返回number值
- 关键字:
–round(number, n)返回四舍五入后的值
--mod(number, n) 求余数
--ceil(number) 向上取整
--floor(number)向下取整
--trunc(number, n) 返回截取后的值
->如果n不为整数则截取n整数部分,如trunc(5555.033333) 5555
->如果n>0则截取到n位小数,如 trunc(5555.66666,2.1) ->5555.66
->如果n<0则截取到小数点向左第n位,小数前其它数据用0表示 。 如trunc(5555.66666,-2.6) ->5500d)日期和时间函数
- 定义:Oracle以内部数字格式存储日期
- 关键字:
--sysdate/current_date(mysql) 以date类型返回当前的日期
--Add_months(d,x) 返回加上x月后的日期d的值
--last_day(d) 返回所在月份的最后一天
--months_between(date1,date) 返回date1 和date2之间月的数目e)转换函数
- 定义:标量数据可以有类型的转换,转换分为两种:a)隐式类型转换 b)显示类型转换
- 隐性类型转换可用于:
--字符和数字的相互转换&字符和日期的相互转换 如:
->varchar2 or char number
->varchar2 or char date
->number varchar2
->date varchar2
例子:
->select * from emp where empno=to_number(‘8000’)
->select *from emp where hiredate=’20-2月-1981’(或to_date(‘20-2月-1981’,’dd-mm-yyyy’) )
注:尽管数据类型之间进行隐性转换,仍然建议使用显示转换函数,以保持良好的设计风格3..显性类型转换可用于:
->关键字:
to_char(number,format)
->用于将Number类型参数转换为varchar2类型,
如果指定了format(样式),它会控制整个转换。
to_number(string, format) && to_date(string,format)
->将char或varchar2类型的string转换为date类型
->将char或varchar2类型的string转换为number类型f)单行函数嵌套
定义:
->单行函数可以被嵌入到任何层
->执行顺序:嵌套函数从最深层到最低层求值
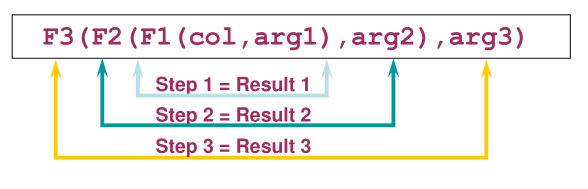
g)其他函
1)decode(条件,值1,翻译值1,值2,翻译值2,...值n,翻译值n,缺省值) 等值匹配
->与switch语句用法相似
->一般用于条件参数较少时优先推荐使用,且参数值为常量或定值
->可与组函数一起作为表中的列来用 如:
--select max(decode(a.type, 1, a.value)) "姓名" from emp 摘自经典面试题1 2) case when then else end
-> 格式:
case [<表达式>]
when <表达式条件值1> then <满足条件时返回值1>
[when <表达式条件值2> then <满足条件时返回值2>
……
[else <不满足上述条件时返回值>]] 可省去,就情况而定
End
->与if..else..语句用法相似
->一般用于 条件参数为变量的场所
->可与组函数一起作为表中的列用 如:
-- select sum(case when ts.subject ='语文' then ts.score end) 语文 from emp 摘自经典面试题4
->也可以单独作为表中的列 如:
-- select (case when a.语文 >= 80 then '优秀'
when a.语文 >= 60 and a.语文 < 80 then '及格'
when a.语文 < 60 then '不及格'
end) "语文" from emp 摘自经典面试题4-->组函数
- 定义:组函数基于多行数据返回单个值
- 关键字:
• avg()返回某列的平均值 用于数字类型
• min()返回某列的最小值 适用于任何于任何数据类型
• max()返回某列的最大值 适用于任何于任何数据类型
• sum()返回某列值的和 用于数字类型
• count()返回某列的行数 组函数除了count(*)外,都跳过空值而处理非空值
• 组函数仅在选择列表和Having子句中有效3.用法:
->可以和decode/case when then else end 使用 如:
- max(decode(a.type, 1, a.value)) "姓名"
- sum(case when ts.subject ='语文' then ts.score end) 语文
->一般在放在select后面from前面 如:
--select avg/min/max/sum/count(参数) from 表
4)组函数不能处理null 解决方法:
->可以利用分组函数中的nvl函数迫使分组函数包括空值
--select avg(nvl(comm,0)) from emp9.分组函数
- 语法:
->nvl() NVL函数迫使分组函数包括空值 可以和组函数一起使用
-> group by
• 创建分组
– group by 子句
– Group by 子句可以包含任意数目的列。
• 除组函数语句外,select语句中的每个列都必须在group by 子句中给出。
– 如果分组列中具有null值,则null将作为一个分组返回。如果列中有多
行null值,他们将分为一组。
– Group by 子句必须出现在where子句之后,order by 子句之前。
• 过滤分组(having子句)
– Where过滤行,having过滤分组。
– Having支持所有where操作符。
• 分组和排序
– 一般在使用group by 子句时,应该也给出order by子句。
• 使用group by 子句将表分成小组
--结果集隐式按降序排列,如果需要改变排序可以使用order by子句• 注意
(1) 出现在select列表中的字段,如果出现的位置不是在组函数中,那么必须出现在group by子句中
--select deptno,avg(sal) from emp group by deptno
(2) group by 列可以不在select列表中
--select avg(sal) from emp group by deptno
(3 ) 不能在where子句中使用组函数,不能在where子句中限制组,使用having对分组进行限制&*Select句子顺序

sql语句执行过程
读取from子句中的基本表、视图的数据, [执行笛卡尔积操作]
选取满足where子句中的条件表达式的元组
按group 子句中指定列的值分组,同时提取满足having子句中组的条件表达式的那些组(having表达式的用法和where用法相似) 10连接函数
定义:-为什么要连表,因为要查的数据在两张表,但是又想显示在一个结果集中
- 连接函数有以下几种:
->1992语法的连接
a)语法规则:
select table1.colunm,table2.colunm
from table1,table2
where table1.colunm1=table2.colunm2
b) 在where子句中写入连接条件
c)当多个表中有重名列时,必须在列的名字前加上表名作为前缀
d)连接类型:
等值连接 equi join 笛卡尔积
->笛卡尔积定义:
• 检索出的行的数目将是第一个表中的行数乘以第二个表中的行数
• 检索出的列的数目将是第一个表中的列数加上第二个表中的列数
• 应该保证所有联结都有 where子句,不然数据库返回比想要的数据多得多的数据
非等值连接 non equi join
1) <,>,<=,>=,!=连接时称非等值连接
外连接 outer join
外连接:在等值基础上,确保一张(主表)的记录都存在 从表 满足则匹配,不满足补充null
外链计算符(+)
->(+)放等号右边表示左边外连接(显示左边表的全部行),反之表示右边外连接(显示右边表的全部行)
自连接 self join (特殊的等值连接)
e) 缺点:
(1)语句过滤条件和表连接的条件都放在了where子句中
(2)当条件过多时,联结条件多,过滤条件多时,就容易造成混淆
->1999语法的连接
定义:1999修正了1992的缺点:把联结调节,过滤条件分开,包括以下新的table join的句法结构:
cross join 交叉连接 (不用on连接)
产生一个笛卡尔积, 就象是在连接两个表格时忘记加入一个WHERE子句一样
--语法结构:
->select emp.empno,emp.ename.emp.deptno.dept.loc from emp,dept
->select emp.empno,emp.ename.emp.deptno.dept.loc from emp cross join dept
natural join 自然连接 (特殊的等值连接) (不用on连接)
--满足条件
->两个表有相同名字的列
->数据类型相同
->从两个表中选出连接列的值相等的所有行
语法:
select * from emp natural join dept
where deptno=10
--自然连接的结果不保留重复的属性
on子句 使用on创建连接
->自然连接的条件是基于表中所有同名列的等值连接
->为了设置任意的连接条件或者指定连接的列,需要使用on子句
->连接条件与其他的查询条件分开书写
->使用on子句使查询语句更加容易理解
--语法:
Select ename,dname from emp join dept on emp.deptno=dept.deptno
Where emp.deptno=30
outer 外连接
left outer join 左外连接
定义:在LEFT OUTER JOIN中,会返回所有左边表中的行,即使在右边的表中没有可对应的列值
--语法:
select e.ename,d.deptno,d.dname
from emp e,dept d
where d.deptno=e.deptno(+);
right outer join 右外连接
定义:RIGHT OUTER JOIN中会返回所有右边表中的行,即使在左边的表中没有可对应的列值。
--语法:
select e.ename,d.deptno,d.dname
from emp e,dept d
where e.deptno(+)=d.deptno;
full outer join 外连接
inner join 内连接
->inner join 默认内连接
->on连接表的条件
--三种语法表达方式:
->Select * from emp e inner join dept d on
e.deptno=d.deptno
->select * from emp e join dept d on e.deptno=d.deptno
->select * from emp ejoin dept d using(deptno)>子查询
- 定义:sql允许多层嵌套。子查询时,即嵌套在其他查询中的查询
- 理解子查询的关键在于查询当做一张表来看待。
- 外层的语句可以把内嵌的子查询返回的结果当成一张表使用
->子查询要用括号括起来
->将子查询放在比较运算符的右边(增强可读性)
4子查询的分类:
->单行子查询
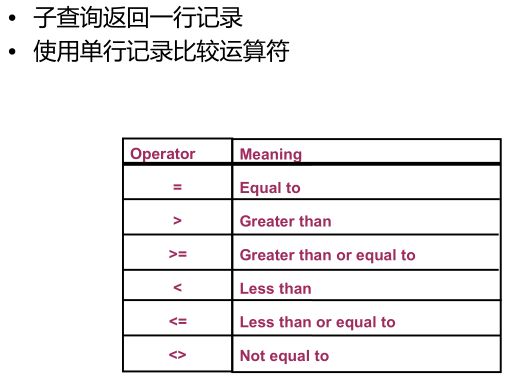
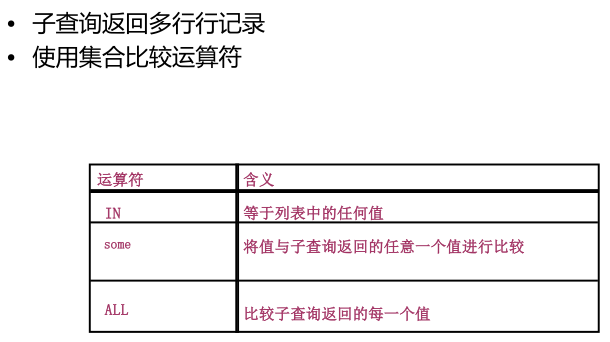
->多行子查询 (使用in)
--语法:
Select empno,ename
from emp where empno in(
select distinct mgr from emp
)
(注:在from子句中使用子查询)
->行转列
1.用组函数、分组
->select a1(有时候也没有),组函数的第一列,组函数的第二列,.....from table group by 值过多的列a1
2. 链表
select * from
(select 第一列的数据 where 条件=第一列) join
(select 第二列的数据 where 条件=第二列) on 第一列=第二列 相同值
join (select 第三列的数据 where 条件=第三列) on 第三列=第二列 相同值>$<DML、事务(B级)
定义:1.Sql的数据更新包括:插入(insert)、删除(delete)、修改(update)DML
2.往表中插入数据的语句是insert语句,方式有两种:元组值的插入和查询结果的插入
元组值的插入语法如下:
Insert into table[colunm[,colunm]] values(value[,value]) 一次插入操作直插入一次- 插入(insert)语句
语法:insert into tablename(colunm,....) select * from tablename2
创建一个临时表:create table temp as select * from emp where 1=2
执行插入:insert into ss select * from emp2.删除(delete)语句
语法:delete [from] table [where condition]
其语义是从基本表中删除满足条件表达式的元组
• Delete from table 表示从表中删除一切元组
• 如果想从表中删除所有的行,丌要使用delete,可使用truncate table 语句,完成相同的工作,但是速度更快(没有事务)3.修改(update)语句
update table set colunm=value[,colunm=value]..[where condition]
其语义是:修改基本表中满足条件表达式的那些元组的列值,
需修改的列值在set子句中指出> 事务(transaction)
1.什么叫事务?
>事务是一个操作序列。这些事务要么都做,要么都不做,是一个不可分割的工作单位,是数据环境中的逻辑工作单位
2.注意:
>事务是为了保证数据库的完整性
>事务不能嵌套
>在Oracle中,没有事务开始的语句,一个事物起始于DML(insert、delete、update)语句,结束与以下的几种情况:
-用户子显示执行commit语句提交操作或rollback语句回退
-当执行DDL(create、alter和drop)语句时事务自动提交
-用户正常断开连接时,事务自动提交
-系统崩溃或断电时事务自动提交
3.关键字commit&rollback
>commit表示事务成功的结束,此时搞死系统,数据路要进入一个新的正确状态,该事务对数据库的所有更新都以交付实施。每个commit语句都可以看成是一个事务成功的结束,同时也是另一个事务的开始
>rollback表示事务不成功的结束,此时告诉系统,已经发生错误,数据库可能处在不正确的状态,该事务对数据库的更新必须被撤销,数据库应该恢复该事务到初始状态。每个rollback语句同时也是另一个事务的开始
>一旦执行了commit语句,将目前对数据库的操作提交给数据库(实际写入 DB),以后就不能rollback进行撤销
>执行一个DDL,dcl语句或从sql*plus正常退出,都会自动执行commit命令
>savepoint test01 rollback to test01
4.提交或回滚前数据的状态
>以前的数据可恢复
>当前的用户可以看到DML操作的结果
>其他用户不能看到DML操作的结果
>被操作数据被锁住,其他用户不能修改这些数据
5.提交后的数据状态
>数据的修改被永远写在数据中
>数据以前的状态永久性丢失
>所有的用户都能看到操作后的数据
>记录锁被释放,其他用户可操作这些记录
6.回滚后数据的状态
>语句将放弃所有的数据修改
>修改的数据被回退
>恢复数据以前的状态
>行级锁被释放7.事务的ACID属性
















 1185
1185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









