





分区就是把一个数据表的文件和索引分散存储在不同的物理文件中。
用户所选择的、实现数据分割的规则被称为分区函数,这在MySQL中它可以是模数,或者是简单的匹配一个连续的数值区间或数值列表,或者是一个内部HASH函数,或一个线性HASH函数。
先验证MySql 是否支持分区?
MySQL从5.1开始支持分区功能:
SHOW VARIABLES LIKE '%partition%';
Empty set (0.00 sec)
如果查询结果显示Empty,表示不支持分区。但是上面的查询方法只是针对MySQL5.6 以下版本。
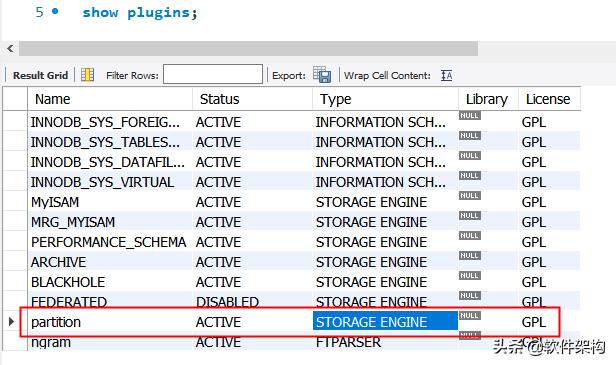
如果MySQL5.6以及以上版本,需要使用下面的查询命令:
show plugins;
上面的查询方法会显示所有插件,如果有红色框的记录(ACTIVE),表示支持分区。
分区的几种模式
(1)Range(范围)
这种模式允许DBA将数据划分不同范围。例如DBA可以将一个表通过separated年份划分成4个分区,2011前的数据,2011-2014 年的数据,2015-2019年的数据,以及任何在2020年(包括2020年)后的数据。
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY RANGE (YEAR(separated)) (
PARTITION p0 VALUES LESS THAN (2011),
PARTITION p1 VALUES LESS THAN (2015),
PARTITION p2 VALUES LESS THAN (2020),
PARTITION p3 VALUES LESS THAN MAXVALUE
);
执行完成之后,打开MySQL 的数据目录:

可以看到 employees#p#p0.ibd到employees#p#p3.ibd 文件,这些是分区的表空间文件。employees.frm 存放表结构。
由此可见,MySQL 通过分区把数据保存到不同的文件里,同时索引也是分区的。
相对于未分区的表来说,分区后单独的数据文件和索引文件的大小都明显降低,效率则明显提升。
(2)Hash(哈希)
这种模式允许DBA通过对表的一个或多个列的Hash Key进行计算,最后通过这个Hash码不同数值对应的数据区域进行分区。例如DBA可以建立一个对表主键进行分区的表。
CREATE TABLE storeworkersstoreworkers (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
job_code INT,
store_id INT
)
PARTITION BY HASH(store_id)
PARTITIONS 4
(3)Key(键值)
上面Hash模式的一种延伸,这里的Hash Key是MySQL系统产生的。
CREATE TABLE user (
id INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY KEY (id) PARTITIONS 4 (
PARTITION p0,
PARTITION p1,
PARTITION p2,
PARTITION p3
);
(4)List(预定义列表)
这种模式允许系统通过DBA定义的列表的值所对应的行数据进行分割。例如:DBA建立了一个横跨三个分区的表,分别根据2004年2005年和2006年值所对应的数据。
CREATE TABLE workers (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
job_code INT,
store_id INT
)
PARTITION BY LIST(store_id)(
PARTITION pNorth VALUES IN (3,5,6,9,17),
PARTITION pEast VALUES IN (1,2,10,11,19,20),
PARTITION pWest VALUES IN (4,12,13,14,18),
PARTITION pCentral VALUES IN (7,8,15,16)
);
(5)Composite(复合模式)
是以上模式的组合使用而已。举例:在初始化已经进行了Range范围分区的表上,我们可以对其中一个分区再进行hash哈希分区。
创建存储过程
下面存储过程,并调用该存储过程往前面的分区表中批量插入实验数据。
drop procedure if exists load_employees
DELIMITER //
CREATE PROCEDURE load_employees()
begin
declare v int default 0;
while v < 10000
do
insert into employees(id, fname, lname, hired, separated, job_code, store_id)
values (v,'rickie', 'lee',
adddate('2008-01-01',(RAND(v)*36520) mod 3652),
adddate('2010-10-01',(RAND(v)*36520) mod 3652),
CEIL(RAND()*15), CEIL(RAND()*100));
set v = v + 1;
end while;
end
//
DELIMITER ; #将语句的结束符号恢复为分号
执行存储过程,往employees 表中插入10000条数据:
call load_employees();
另外创建一个未分区表 employees_nopartition,同时也插入 10000条数据。
测试sql性能
分别查询分区表和未分区表,查看执行时间。
select count(*) from employees where separated > date '2011-01-01'and separated < date '2011-12-31';
select count(*) from employees_nopartition where separated > date '2011-01-01'and separated < date '2011-12-31';
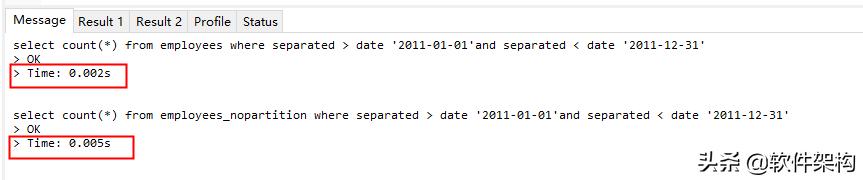
分区表的执行时间比普通表明显小。
通过explain语句来分析执行情况
EXPLAIN select count(*) from employees where separated > date '2011-01-01'and separated < date '2011-12-31';
EXPLAIN select count(*) from employees_nopartition where separated > date '2011-01-01'and separated < date '2011-12-31';
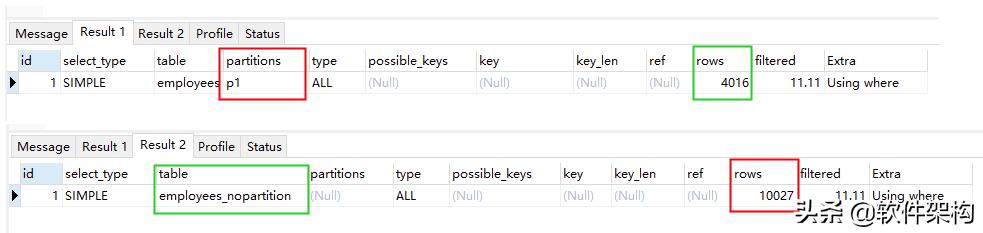
分区表执行扫描了4016 行,而普通表则扫描了10027 行。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









