





MySQL索引种类

1、主键索引
创建表时,若显式指定主键字段,则MySQL将使用该字段作为主键索引;若没有显式指定主键,则系统将根据一定的规则选择一个字段作为主键。
2)特点、作用、缺点索引值有序、列值唯一(不可以有null)、表中只有一个
加速查询每记录行全部数据 ,减少磁盘IO
索引需要占用磁盘空间、对于InnoDB的主键索引,需要更多的磁盘空间
2、唯一索引
2)特点、作用、缺点
索引值有序、索引列值唯一(可以有null)、一张表可以有多个唯一索引、对于唯一索引来说,由于索引定义了唯一性,查找到第一个满足条件的记录后,就会停止继续检索。
加速查询、避免数据出现重复、减少磁盘IO
索引需要占用磁盘空间
3)创建命令
CREATE UNIQUE INDEX index_name ON table_name(col_field);3、普通索引
2)特点、作用、缺点
索引值有序、对于普通索引来说,直到找到所有不满足条件的记录后,才会停止检索
仅加速查询
4、组合(复合)索引
多列值组成一个索引,专门用于组合搜索,其效率大于索引合并2)特点、作用、缺点
多字段组成的索引、要求满足最左匹配原则。
加速查询多字段数据
5、全文索引
对文本的内容进行分词,进行搜索
其他索引名词解释
1、聚集(簇)索引
具体参考
https://blog.csdn.net/qq_29373285/article/details/85254407
数据行的 物理顺序(记录行指针)与列值(一般是主键的那一列)的 逻辑顺序相同,一个表中只能拥有一个聚集索引。需要知道的是,聚集索引并不是一种单独的索引类型,而是一种 数据存储方式。对于使用InnoDB引擎创建的表,只有主键就是聚集索引,其余都是非聚集索引。 聚集索引的优缺点?page=163 聚集索引与非聚集索引的区别? 根本区别是: 表记录的排列顺序(数据行的物理顺序)和与索引的排列顺序是否一致 。 Innodb引擎主键索引是聚集索引,其余索引都是非聚集索引。参考《高性能MySQL》page=162
其余区别:
聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个
聚集索引存储记录是物理上连续存在,而非聚集索引是逻辑上的连续,物理存储并不连续
聚集索引插入数据时速度要慢(时间花费在“物理存储的排序”上,也就是首先要找到位置然后插入),查询数据比非聚集数据的速度快
2、二级(辅助)索引
除主键索引外,其他索引都称之为二级(辅助)索引,其特点是 二级索引的叶子节点(B+Tree索引模式)存储的是索引字段和主键字段 。 也就是说当查询的结果集是该索引字段和主键字段时,就可以避免回表操作,其实就是覆盖索引。 InnoDB引擎在二级索引上使用的是共享锁,即读锁 。
3、覆盖索引
覆盖索引并不是一种具体的索引类型,而表示的是查询sql的返回结果等于索引树下叶子节点保存的值,而不需要进行回表操作,减少磁盘IO操作。 因而,对于联合索引,只要查询的字段与联合索引一致或查询的字段满足最左匹配原则,都是覆盖索引。 覆盖索引优缺点?page=171.
如何验证一个SQL使用了覆盖索引呢?EXPLAIN SELECT XXX FROM TABLE_NAME WHERE XXX;表 user Innodb引擎索引:PK(id) key(name,phone),unique(sex)select sex from user where sex=? //是select * from user where name=? //不是select id,sex from user where sex=? //是,注意辅助索引下存的主键select name,phone from user where sex=? //不是不是同一个b+treeselect phone from user where name=? //是4、前缀索引
索引字段长度选取的越长,占用的磁盘空间就越大,相同的数据页能放下的索引值就越少,搜索的效率也就会越低。为了平衡索引占用磁盘空间大小与查询效率,引入了前缀索引进行优化。ALTER TABLE table_name ADD KEY(col_name(n))定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本
无法使用前缀索引做order by 和group by,这样会走全表扫描
无法使用前缀索引做覆盖扫描,即无法使用覆盖索引
//如身份证ID alter table t add ID_crc int unsigned, add index(ID_crc); select field_list from t where ID_crc=crc32('input_ID_string') and ID='xxx'; 相同点:两者都只能支持等值查询。
不同点:1)字段个数。2)CPU消耗。3)查询效率。
5、索引最左前缀原则
在B+tree索引模式下,判断是否走索引进行查询的判断逻辑是where条件中第一个字段是否是索引最左边的。 现在有表index_table且索引为(a)、(a,b)、(a,b,c)。判断下面的查询SQL是否走索引?select * from index_table where a=xxx;//走索引(a)select * from index_table where a=xxx and b=xxx ;//走索引(a,b)select * from index_table where a=xxx and c=xxx ;//走索引????select * from index_table where b=xxx and c=xxx ;//不走索引6、索引下推/索引条件推送
索引下推/索引条件推送(index condition pushdown),这是MySQL5.6+版本开始提供的,在此之前, 不允许MySQL将索引列的过滤条件传到存储引擎层。导致存储引擎查询更多的数据行,而在服务器层进行条件判断,过滤不符合条件的。现在t_user表上有联合索引(name,age),使用下面的SQL进行查询数据。//根据索引最左前缀原则,将使用name索引并筛选出携带“张”的主键IDselect * from t_user where name like '张%' and age=10 and ismale=1;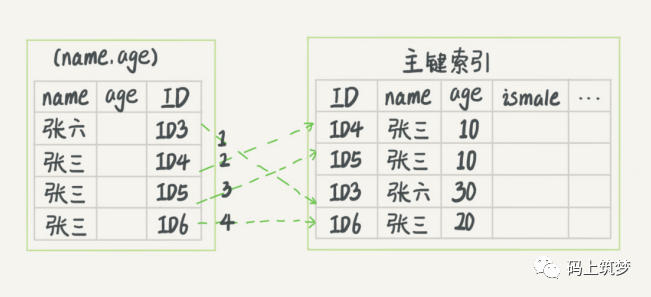
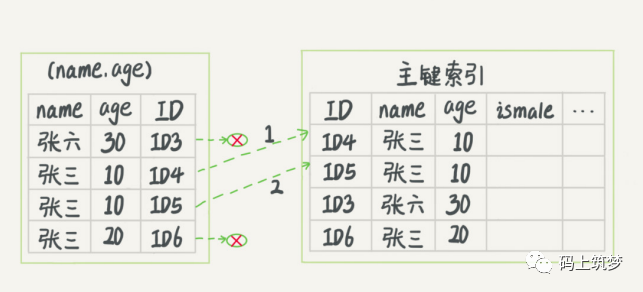
7、索引合并
在MySQL5.0+版本后,引入索引合并策略,在一定程度上可以使用表上的多个单列索引来定位指定数据行。 如何查看当前查询SQL使用了索引合并特性? 索引合并有啥作用?一般,系统使用索引合并表示当前表上的索引建的很糟糕,这时候就需要使用组合索引了,而不是单列索引。参考《高性能MySQL》157-158















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









