





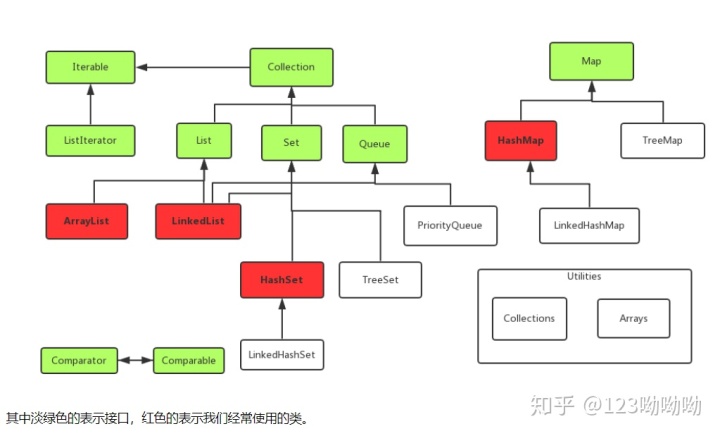
如图所示,为我们常用的容器类
由上面的图可以非常清楚的看到,Java中的容器的继承结构
在顶层有很多接口,这些接口声明了很多的基本的抽象方法,之后的许多类按照不同的方式实现这些接口,
同时可能在增加一些自己的方法,从而形成了不同功能的容器,比如:ArrayList类与LinkedList类都继承了List接口,
但是他们在实现List的接口时,方法体并不一样,这样一来就形成了不一样的容器,这些容器都位于java.util包中
Java容器类类库的用途是保存对象,可以将其分为2个概念。
Collection
一个独立元素的序列,这些元素都服从一条或多条规则。其中List必须按照插入的顺序保存元素、Set不能有重复的元素、Queue按照排队规则来确定对象的产生顺序(通常也是和插入顺序相同)
Map
一组成对的值键对对象,允许用键来查找值。ArrayList允许我们用数字来查找值,它是将数字和对象联系在一起。而Map允许我们使用一个对象来查找某个对象,它也被称为关联数组。或者叫做字典。
接下来一一介绍讲解这些类的具体功能和需要注意的地方
1 . List
List承诺可以将元素维护在特定的序列中。List接口在Collection的基础上加入了大量的方法,使得可以在List中间可以插入和移除元素。下面主要介绍2种List;
1.1 ArrayList
是线性表中的数组,也就是说这个类中的数据域实际上就是一个对象数组,
因此,他有数组的一切的特性,还有同时封装在一起的方法
因此对于查找来说,速度是非常的快的,但是删除与插入操作就相对较慢,而且ArrayList是线程不安全的
优点在于随机访问元素快,但是在中间插入和移除比较慢
ArrayList的初始化有三种:
private transient Object[] elementData;
public ArrayList() {
this(10);
}
public ArrayList(int initialCapacity) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
}
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
size = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
}ArrayList其实就是采用的是数组(默认是长度为10的数组)。所有ArrayList在读取的时候是具有和数组一样的效率,它的时间复杂度为1
1.2 LinkedList
就像名字显示的那样,LinkedList是线性表当中的链表,也就是说这个类中的数据域实际上就是一个对象链表,
还有同时封装在一起的方法,值的注意的是内部的这个链表是一个双向的循环链表,
也就是说,插入语删除操作是非常快的,但是查找较慢,同样,LinkedList是线程不安全的。
ListedList采用的是链式存储。链式存储就会定一个节点Node。包括三部分前驱节点、后继节点以及data值。所以存储存储的时候他的物理地址不一定是连续的。
查看一下它的中间插入操作
public void add(int index ,E element){
checkPositionIndex(index);
if(index == size)
linkLast(element);
else
linkBefore(element , node(index));
}
void linkBefore(E e ,Node<E> succ){
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred , e ,succ);
succ.prev = newNode;
if(pred ==null)
firsrt = newNode;
else
pred.next = newNode;
size++;
modCount++;
}从代码我们可以看出先获取插入索引元素的前驱节点,然后把这个元素作为后继节点,然后在创建新的节点,而新的节点前驱节点和获取前驱节点相同,而后继节点则等于要移动的这个元素。所以这里是不需要循环的,从而在插入和删除的时候效率比较高。
我们在来看看查询(我们可以分析出它的效率要比ArrayList低了不少)
Node<E> node(int index){
if(index < (size >>1)) {//除以二
Node<E> x = first; //首先查看index属于前一半还是后一半,然后进行遍历,直到index的节点
for(int i = 0; i<index; i++)//查询效率时间复杂度为n
x = x.next;
return x;
}else{
Node<E> x = last;
for(int i = size - 1;i > index; i--)
x=x.prev;
return x;
}
}2 . Set(集合)
1、Set 中不接受任何重复的元素,如果试图将重复的对象加到同一个Set对象当中的话,是不能加入的;所谓的相同的对象,是根据equals(参数)方法来判定的
Set最常用的就是测试归属性,很容易的询问出某个对象是否存在Set中。
2、一般Set最常用于判定一个指定元素的归属性问题,即判定一个元素是否已经在在当前的集合当中了!可见查找是Set型容器的最常用的、最重要的方法了;Set与Collection具有完全一样的接口,实际上Set就是Collection,只是应用的行为不同罢了!
3、虽然Set有HashSet、TreeSet、LinkedSet三种实现类,但是在《thinking in java》 中明确指出,对于查找而言HashSet类失效率最高的一个类,所以在没有特殊的要求时,使用HashSet是最好的选择
2.1 HashSet
HashSet查询速度比较快,但是存储的元素是随机的并没有排序
public static void main(String[] args){
/**
* 没有顺序可循,这是因为hashset采用的是散列(处于速度考虑)
*/
Random random=new Random(47);
Set<Integer> intset=new HashSet<Integer>();
for (int i=0;i<10000;i++){
intset.add(random.nextInt(30));
}
System.out.print(intset);
}
2.2 TreeSet
TreeSet是将元素存储红-黑树结构中,所以存储的结果是有顺序的(所以如果你想要自己存储的集合有顺序那么选择TreeSet)
public static void main(String[] args){
Random random=new Random(47);
Set<Integer> intset=new TreeSet<Integer>();
for (int i=0;i<10000;i++){
intset.add(random.nextInt(30));
}
System.out.print(intset);
}
3.Queue(队列)
也就是说,Queue类型的容器专门用来用作容器来使用的,具有队列的特性
Queue有offer、peek、element、pool、remove等方法
offer是将元素插入队尾,返回false表示添加失败。peek和element都将在不移除的情况下返回对头,但是peek在对头为null的时候返回null,而element会抛出NoSuchElementException异常。poll和remove方法将移除并返回对头,但是poll在队列为null,而remove会抛出NoSuchElementException异常.
3.1 LinkedList类型的容器实现普通的队列、双向队列、栈等数据结构(LinkedList类同时实现了Queue接口)
我们可以通过将LinkedList的对象向上转型到Queue,这样一来的话就只能使用继承自Queue接口的专门用于队列的方法,使LinkedList对象看起来像一个完完全全的队列容器;对于双向队列,java中有一个专门用于实现双端队列的接口Deque,位于java.uitl包中,而且LinkedList类也实现了该接口,所以同样可以将LinkedList对象向上转型形成一个单纯的双端队列
3.2 PriorityQueue(优先级队列)
所谓的优先级队列就是在该队列的内部有一个堆的数据结构,实现了每次出对的元素,都是优先级最高的元素;
但是程序是如何知道每个元素的优先级的呢,这里有两种方式:自然方式和人为指定方式
所谓的自然方式是指,如果容器中的元素对象是String、Integer、或者是Character类型的内嵌数据类型的话,那么这种优先级是程序已经自行规定好的了,即“较小”的拥有较高的优先级;但是对于实际问题中的很多的元素都不是内嵌的数据类型,那么就要人为的指定优先级的设定规则,解决这一问题的方法就是,使元素类实现Comparable
接口,这个接口中只有一个方法
public int compareTo(Object obj)
只要在元素类中将该方法实现的话,那么程序就会自行的根据这个方法来设定优先级
PriorityQueue可以确保当你调用peek、pool、remove方法时,获取的元素将是对列中优先级最高的元素
六、Map(映射)
Map(映射)是一种将键对象和值对象进行映射的集合,需要注意的是如果值对象是Map类型的话那么,就形成了多级映射;
在实现该接口的类中效率最高的一个就是HashMap类,一般在没有特殊的要求的情况下最好及使用这个类型的容器,这个容器的用法和前面讲过的Hashtable容器非常相近,可以参照该部分的内容进行理解,其中最终要的一点是对于hashCode()和euqals()方法的重写;
另外需要注意的一点是:如果在哈希表的应用中,迭代性能比查找性能更加站上风,那么在设定初始容量时,就应该尽量的不让初始容量太高,而同时让装填因子设定的得尽量的高;如果是说实际使用哈希表的时候,有非常多的键值对要加入到该容器中的话,使用足够大的初始容量创建该容器,将使得映射关系更加有效的存贮,因为如果初始容量设定的过于小的话,那么容器就会按照规则不断的进行扩充,那么就会耗费非常多的时间
这里主要介绍一下HashMap的方法,大家注意HashMap的键可以是null,而且键值不可以重复,如果重复了以后就会对第一个进行键值进行覆盖。
put进行添加值键对,containsKey验证主要是否存在、containsValue验证值是否存在、keySet获取所有的键集合、values获取所有值集合、entrySet获取键值对。
public static void main(String[] args){
//Map<String,String> pets=new HashMap<String, String>();
Map<String,String> pets=new TreeMap<String, String>();
pets.put("1","张三");
pets.put("2","李四");
pets.put("3","王五");
if (pets.containsKey("1")){
System.out.println("已存在键1");
}
if (pets.containsValue("张三")){
System.out.println("已存在值张三");
}
Set<String> sets=pets.keySet();
Set<Map.Entry<String , String>> entrySet= pets.entrySet();
Collection<String> values= pets.values();
for (String value:values){
System.out.println(value+";");
}
for (String key:sets){
System.out.print(key+";");
}
for (Map.Entry entry:entrySet){
System.out.println("键:"+entry.getKey());
System.out.println("值:"+entry.getValue());
}
}














 1797
1797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









