





HBase简介及其在大数据生态圈的位置
HBase简介
HBase是一个分布式的、面向列的开源数据库
来源于google的Bigtable
HBase在Hadoop之上提供了类似于Bigtable的能力(是基于Hadoop的HDFS进行存储)HBase不同于一般的关系数据库,它适合非结构化数据存储
Bigtable是什么
Bigtable是压缩的、高性能的、高可扩展性的、基于Google GFS文件系统的数据库
用于存储大规模的结构化数据
在扩展性和性能方面有很大的优势什么是面向列的数据库
即列式数据库,就是把每一列中的数据值放在一起进行存储
对应的就是行式数据库(常见的有关系型数据库):把每一行的数据放在一起存储,存储完了之后就存储下一行的数据
如下图: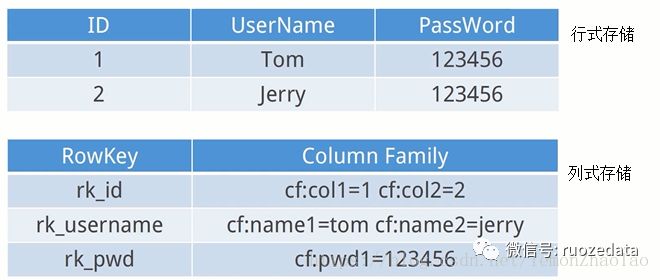
那么列式存储有什么好处呢?
假如我们使用的是关系型数据库,现在要去存一堆数据,这时候我们需要去建立表结构,然后去维护相关的索引,如果当数据量过大的时候,查询起来可能就很慢了。
而列式存储,每一列都是单独进行存放的,在读取某列数据的时候速度更快,降低了IO;而且每一列的数据类型都是统一的,这样就易于压缩;行式存储擅长随机读取的操作,列式存储擅长于大批量的数据查询。
对于行式和列式的使用,还是得需要看具体的需求。
为什么HBase适合非结构化数据存储
结构化数据与非结构化数据的概念
结构化数据:可以用二维表格形式存储的数据
非结构化数据:图片、文档这些可以认为为非结构化数据
我们可以将这些非结构化数据以二进制的方式存到HBase里面,这样无论是存储还是查询都是比较方便快捷的,而且很容易进行扩展
HBae在大数据生态圈中的位置
HBase是Apache基金会顶级项目
HBase基于Hadoop的核心HDFS系统进行数据存储,类似于Hive
Hive是基于Hadoop的数据仓库工具,用来对于一段时间内的数据进行分析查询,而不是进行实时的数据查询HBase可以存储超大数据并适合用来进行大数据的实时查询
HBase与HDFS
HBase建立在Hadoop文件系统之上,利用了Hadoop的文件系统的容错能力
HBase提供了对数据的随机实时读/写访问功能
HBase内部使用哈希表,并存储索引,可将在HDFS文件中的数据进行快速查找
HBase使用场景
瞬间写入量很大,常用数据库不好支撑或需要很高成本支撑的场景
数据需要长久保存,且量会持久增长到比较大的场景
HBase不适用于有join,多级索引,表关系复杂的数据模型
HBase数据存储模型
CAP定理
CAP定理就是对于一个分布式计算系统不可能同时满足以下三点:
一致性(所有节点在同一时间具有相同的数据)
可用性(保证每个请求不管成功或者失败都有响应,但不保证获取的数据为正确的数据)
分区容错性(系统中任意信息的丢失或失败不会影响系统的继续运作,系统如果不能在某一个时限内达成数据一致性,就必须在上面两个操作之间做出选择)
那么对于分布式数据系统,分区容错性是最基本的要求,否则就失去了存在的意义,因此需要在一致性和可用性上做出取舍:在很多情况下会牺牲一致性从而来换取可用性,比如:Cassandra就是AP类型的,当然,牺牲一致性,只是要求不像关系型数据库一样,要求强一致性,而是要求系统能达到最终一致性。而HBase属于CP类型的,是强一致性的,它的每一行有regionserver、rowkey、版本标签等来组合,从而保证行的一致性
ACID定义
数据库事务正确执行的4个基本要素
原子性(一个事务要么全部执行,要么全部不执行。如果执行过程中发生了错误,系统会回滚到最初的状态)
一致性(事务的运行,不会改变数据库中数据的一致性)
隔离性(2个以上的事务在执行的过程中,不会出现交错执行的状态(因为这样的话可能会导致数据的不一致))
持久性(一个事务执行成功之后,该事务对数据库的更改,要持久性的保存在数据库当中)
一个支持事务的数据库系统中必须得有这4个特性,否则在事务的过程当中就无法保证事务的正确性
HBase作为一个NoSQL数据库,为了性能不支持严格的ACID,只支持到单个的行
HBase概念
NameSpace:可以把NameSpace理解为RDBMS的“数据库”
1个NameSpace包含一组表Table:表名必须是能用在文件路径里的合法名字
这样做是因为HBase的表是映射成HDFS上相应的文件的,因此表名必须是合法的路径Row:在表里面,每一行代表着一个数据对象,每一行都是以一个Row Key来进行唯一标识的,Row Key并没有什么特定的数据类型,以二进制的字节来存储
Column:HBase的列由Column family和Column qualifier组成,由冒号(:)进行间隔;比如 family:qualifier
RowKey:可以唯一标识一行记录,不可被改变;改变的唯一方式是删除这个RowKey,再重新插入
Column Family:是一些Column的集合,1个Column Family所包含的所有的Column成员是有着相同的前缀;在物理上1个Column Family所有的成员是存储在一起的,存储的优化都是针对Column Family级别的;这就意味着1个- Column Family的成员都是用相同的方式进行访问的;在定义HBase表的时候需要提前设置好列族,表中所有的列都需要组织在列族里面;列族一旦定义好之后,就不能轻易的更改了,因为它会影响到HBase真实的物理存储结构
Column Qualifier:列族中的数据通过列标识(Column Qualifier)来进行映射,可以理解为一个键值对,Column Qualifier就是key
Cell:每一个RowKey、Column Family、Column Qualifier共同组成的一个单元;存储在Cell里面就是我们想要保存的数据;Cell存储的数据没有特定的数据类型,以二进制字节来进行存储
Timestamp:每个值都会有一个timestamp,作为该值特定版本的标识符;默认HBase中每次插入数据的时候,都会用timestamp来进行版本标识;读取数据时,如果这个时间戳没有被指定,就默认返回最新的数据;写入数据时,如果没有设置时间戳,默认使用当前的时间戳;每一个列族的数据的版本都由HBase单独维护;默认情况下,HBase会保留3个版本的数据
HBase与传统关系型数据的区别
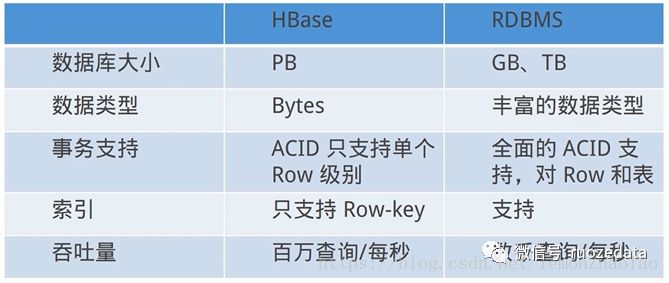
查询的时候只能通过API去查询,不支持SQL,所以也默认支持通过RowKey去进行查询
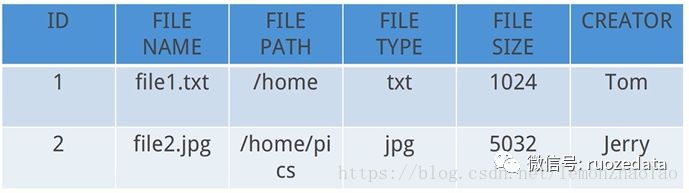
两者的数据排布方式有很大的区别:
传统的数据库就是行列的组织
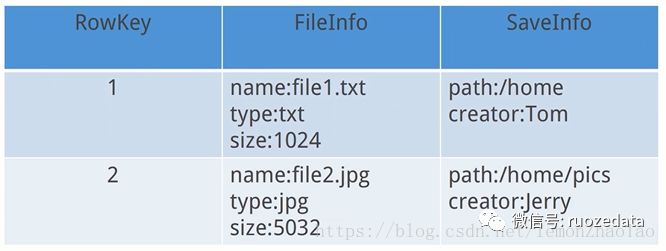
而对于HBase这种NoSQL数据库我们可以理解为稀疏的多维的map
每一行都是一个文件,每一列都是相关的属性
关系型数据库:
HBase:
HBase数据模型
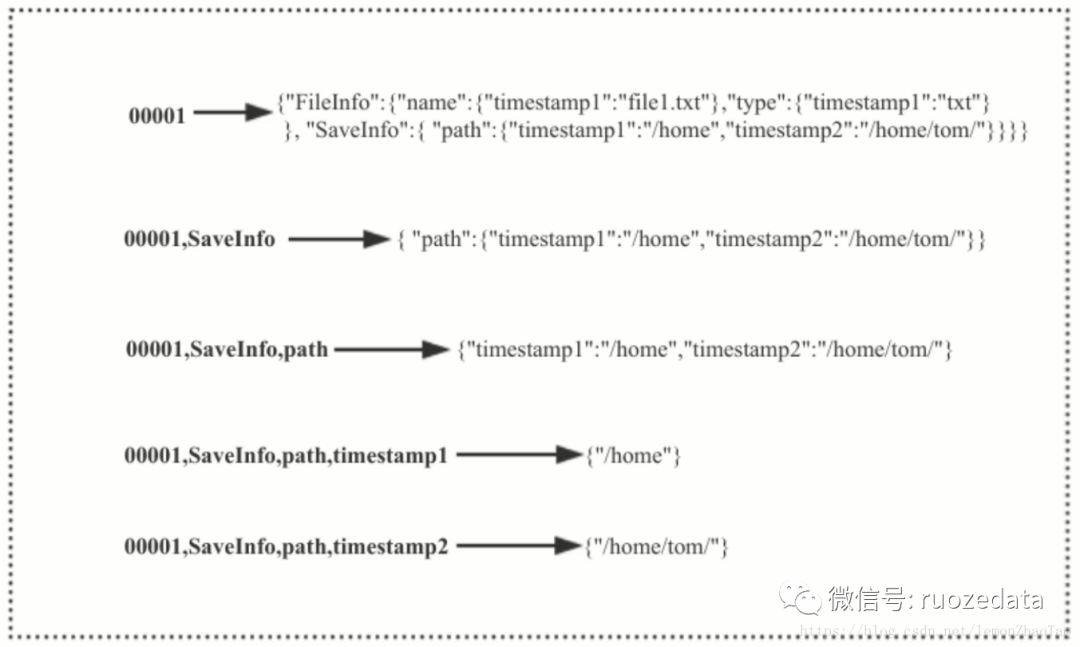
我们可以将HBase的存储模型想象成一个大的map
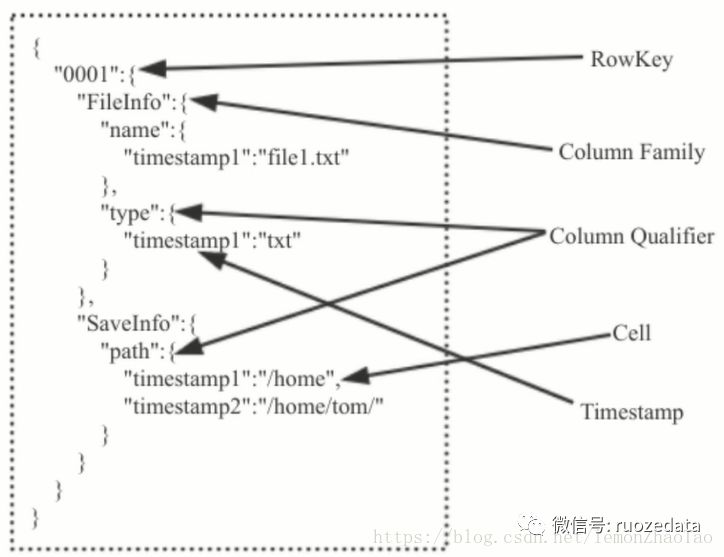
如果想去访问具体的值是层级递进的,从而最终得到我们想要的值
HBase基础架构
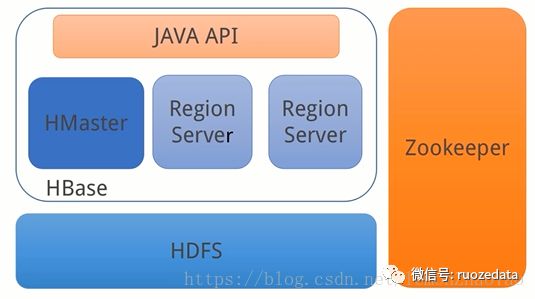
HBase依托于HDFS之上;整体上又划分为HMaster和RegionServer,在上层通过Java API提供查询的功能;通过Zookeeper进行管理
通过上图我们可以发现,HBase工作的三大模块:
HMaster
HMaster是HBase主/从集群架构中的中央节点
HMaster用于协调多个RegionServer、检测各个RegionServer的状态、并且平衡各个RegionServer之间的负载、同时还负责分配region到RegionServer
region:region是HBase中存储的最小的单元、是HBase表格的基本单位
HMaster维护表和Region的元数据,不参与数据的输入/输出过程
HBase本身是支持HA的,也就是说同时可以有多个HMaster进行运行,但是只有1个处于active状态;如果处于active的节点失效了,挂掉了,其它的HMaster节点就会选举出一个active节点来接管整个HBase集群
RegionServer
维护HMaster分配给他的region,处理堆这些region的io请求
当用户需要读取数据的时候会连接到对应的RegionServer,从相关的region中去获取数据负责切分正在运行过程中变的过大的region,从而保证查询的效率
Zookeeer
Zookeeper是HBase HA的解决方案,是整个集群的协调器
通过Zookeeper保证了至少有一个HMaster处于active状态
HMaster并不直接参与数据的读写操作,当我们使用HBase的API的时候,当我们想用HBase的API去读取数据的时候,我们并不需要知道HMaster的地址、也不需要知道RegionServer的地址,我们只需要知道Zookeeper集群的地址就可以了HMaster启动将系统加载到Zookeeper
Zookeeper保存了HBase集群region的信息、meta的信息等等维护着RegionServer的状态信息,知道哪些数据需要从哪些RegionServer去读取
HBase伪分布式环境部署
1hadoop@hadoop001:~ $ cd ~/softeware
2hadoop@hadoop001:~/software $ tar -zxvf hbase-1.2.4-bin.tar.gz –C ../app
3hadoop@hadoop001:~/software $ cd ../app
4hadoop@hadoop001:~/app $ cd hbase-1.2.4/conf
5hadoop@hadoop001:~/app/hbase-1.2.4/conf $ cp ~/app/hadoop-2.7.3/etc/hadoop
6/hdfs-site.xml .
7hadoop@hadoop001:~/app/hbase-1.2.4/conf $ cp ~/app/hadoop-2.7.3/etc/hadoop
8/core-site.xml .
9hadoop@hadoop001:~/app/hbase-1.2.4/conf $ vi hbase-env.sh
10export JAVA_HOME=~/app/jdk1.8.0_161
11# export HBASE_MASTER_OPTS=”$HBASE_MASTER_OPTS –XX:PermSize=128m –XX:MaxPermSize
12=128m”
13# export HBASE_REGIONSERVER_OPTS=”$HBASE_REGIONSERVER_OPTS –XX:PermSize=128m –XX:
14MaxPermSize=128m”
15hadoop@hadoop001:~/app/hbase-1.2.4/conf $ vi hbase-site.xml
1617 18 hbase.root.dir 19 hdfs://localhost:9000/hbase20 21 22 hbase.zookeeper.property.dataDir23 /home/hadoop/hadoop_data/zookeeper 24 25 26 hbase.cluster.distributed27 true28 29
30hadoop@hadoop001:~/app/hbase-1.2.4/conf $ cd ../bin
31hadoop@hadoop001:~/app/hbase-1.2.4/bin $ ./start-hbase.sh
32hadoop@hadoop001:~/app/hbase-1.2.4/bin $ jps
3313792 HQuorumPeer
3413968 HRegionServer
3513864 HMaster
3612156 NameNode
3712556 SecondaryNameNode
3814317 Jps
3912335 DataNode
40hadoop@hadoop001:~/app/hbase-1.2.4/bin $ ./hbase shell
41hbase(main):001:0> status
421 active master, 0 backup master, 1 servers, 0 dead, 2.0000 average load
43hadoop@hadoop001:~/app/hbase-1.2.4/bin $ cd ~/app/hadoop-2.7.3/bin
44hadoop@hadoop001: ~/app/hadoop-2.7.3/bin $ ./hdfs dfs –ls /
45Found 2 items
46drwxr-xr-x - hadoop supergroup 0 2018-07-15 17:23 /hbase
47drwxr-xr-x - hadoop supergroup 0 2018-07-15 17:08 /test
作者:若泽数据——呼呼呼
原文:
https://blog.csdn.net/lemonZhaoTao/article/details/81150397
回归原创文章:
若泽数据-高级班&线下班报名
高级班学员高薪offer32w,你比他高吗?
捷报: 高级班学员月薪22K及上周3家offer的面试题
刚出炉的3家大数据面试题(含高级),你会吗?
捷报:刚出炉年薪30w的offer和面试题
捷报:高级班学员年薪37.4W的offer及3家面试题
加我,进大数据V群















 773
773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









