





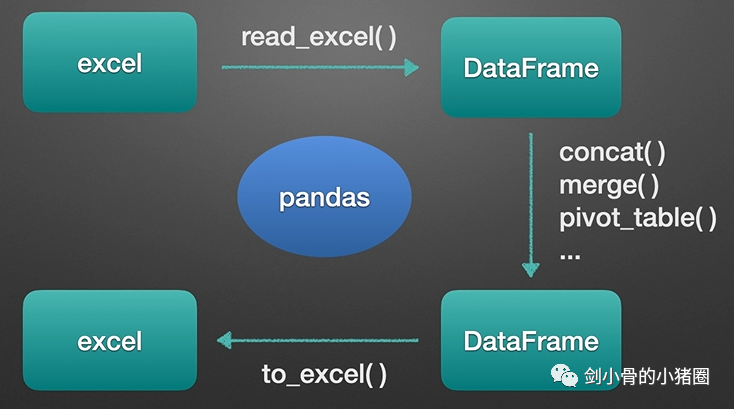
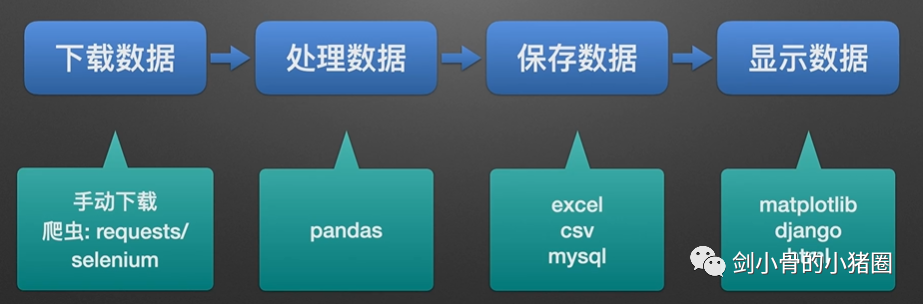
python工作中的有些场景,我们需要
下载数据 -> 处理数据 -> 保存数据 -> 显示数据。
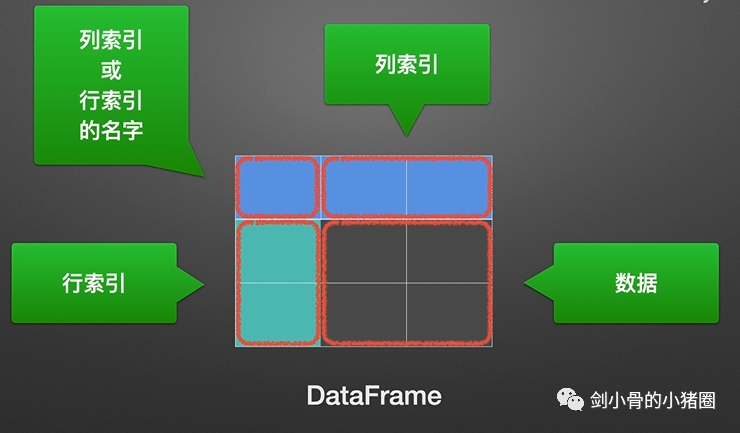
 列表/ numpy/ pandas
列表里面的元素可以是python里面的任意的对象,使用方便,但效率不高
numpy是多维的数组结构,只能保存同一类型的数据,通常是数值类型,加大了数值计算的效率
pandas工作在numpy之上,继承了numpy效率高的优点,且易于使用。
列表/ numpy/ pandas
列表里面的元素可以是python里面的任意的对象,使用方便,但效率不高
numpy是多维的数组结构,只能保存同一类型的数据,通常是数值类型,加大了数值计算的效率
pandas工作在numpy之上,继承了numpy效率高的优点,且易于使用。
 创建Series
创建Series
列表/ numpy/ pandas
列表里面的元素可以是python里面的任意的对象,使用方便,但效率不高
numpy是多维的数组结构,只能保存同一类型的数据,通常是数值类型,加大了数值计算的效率
pandas工作在numpy之上,继承了numpy效率高的优点,且易于使用。
创建Series
>>>import pandas as pd
>>> s =pd.Series([1,2,3],index=list('abc'),dtype='int64',name='num') # 创建Series方法一
>>> s
a 1
b 2
c 3
Name: num,dtype: int64
>>>
>>>s=pd.Series({'a':1,'b':2,'c':3}) # 创建Series方法二,字典的键就作为Series的索引
>>> s
a 1
b 2
c 3
dtype: int64
>>>
>>> s =pd.Series(3.0, index=['a', 'b', 'c']) #创建Series方法三,传入一个标量
>>> s
a 3.0
b 3.0
c 3.0
dtype: float64
>>>
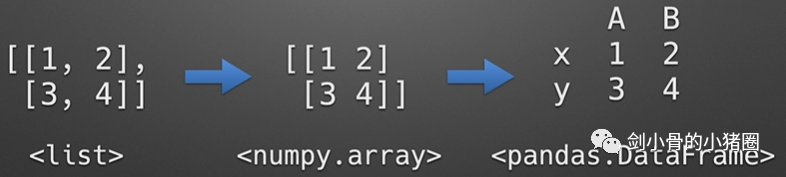
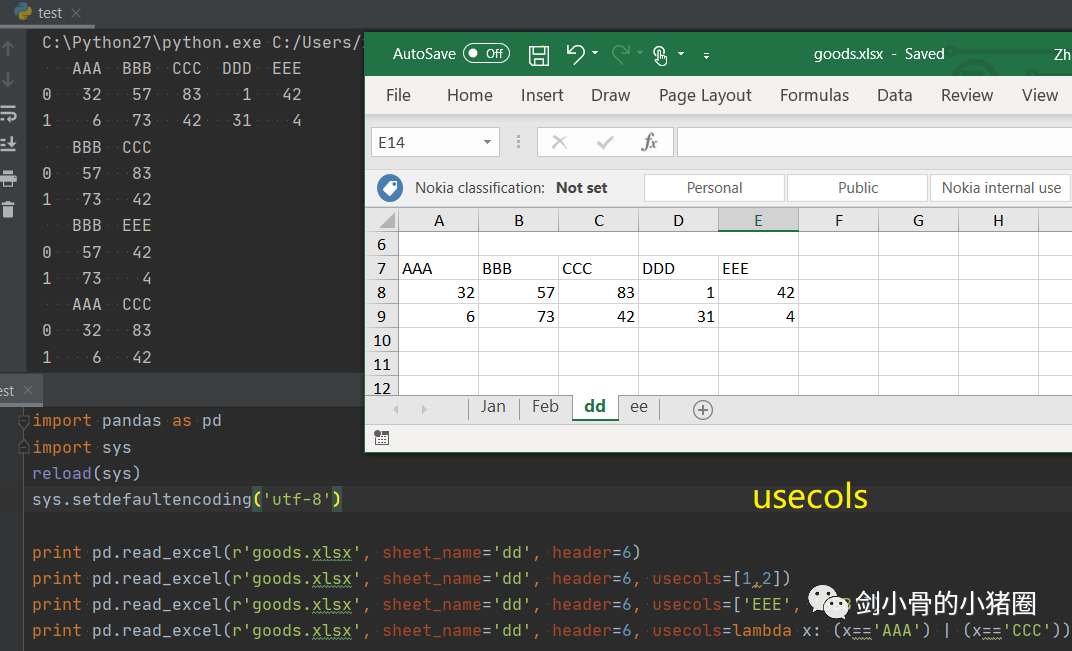
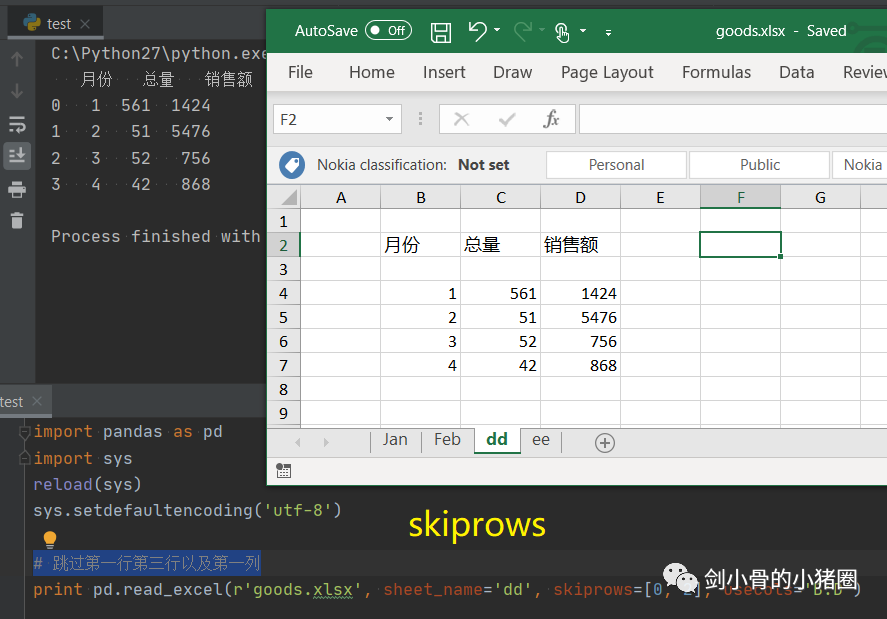
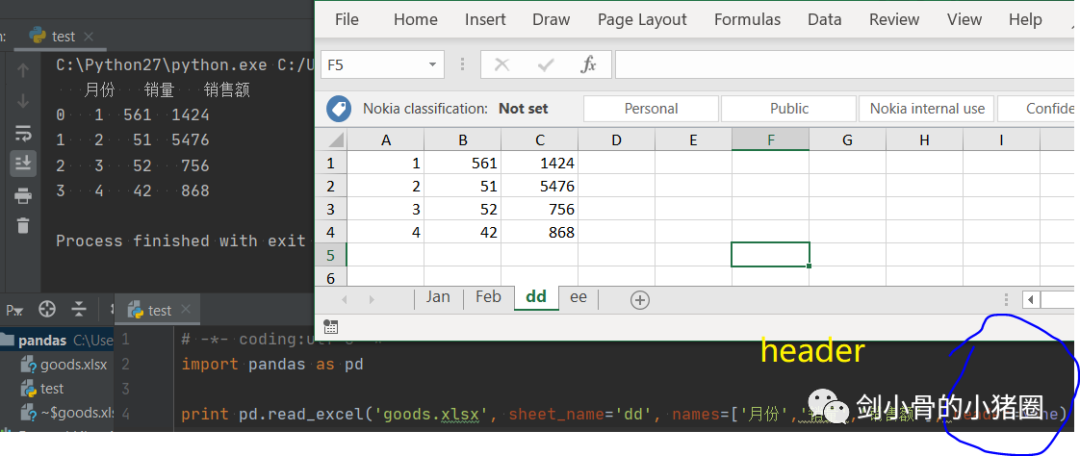
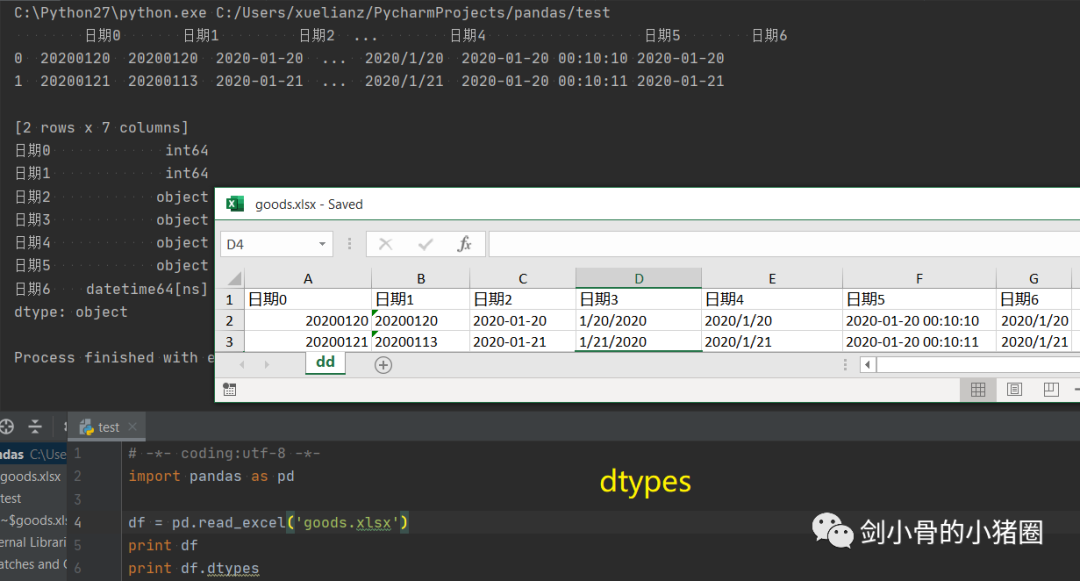
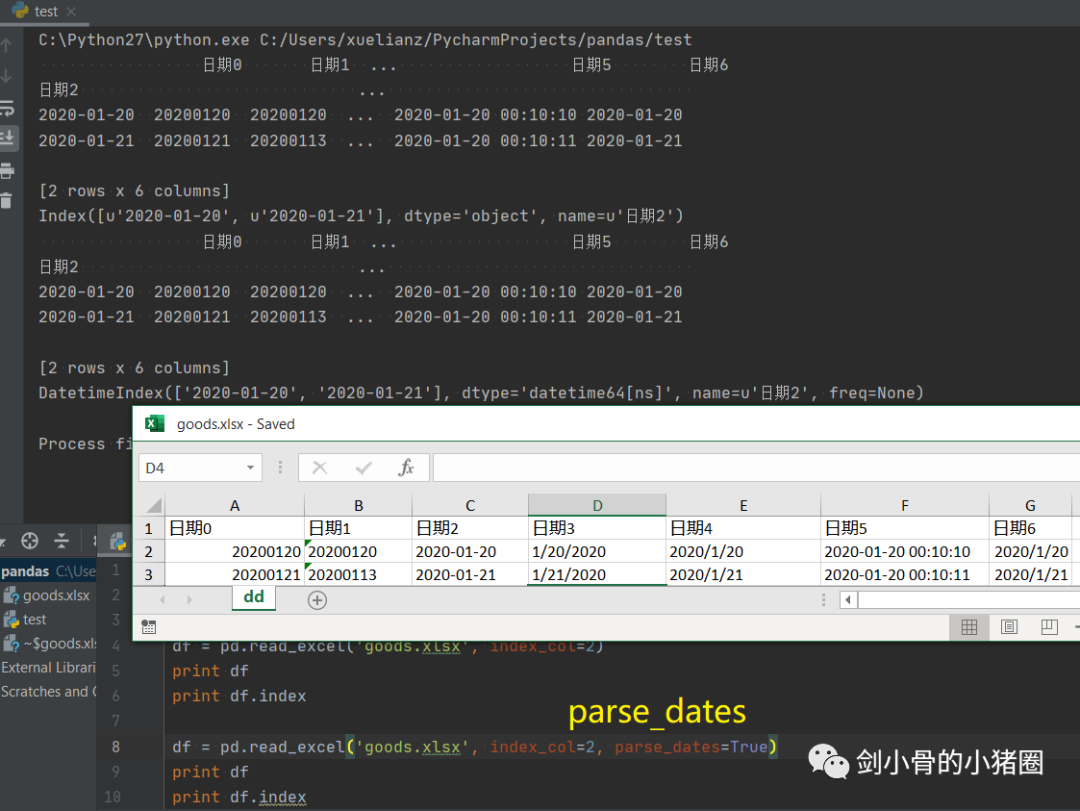
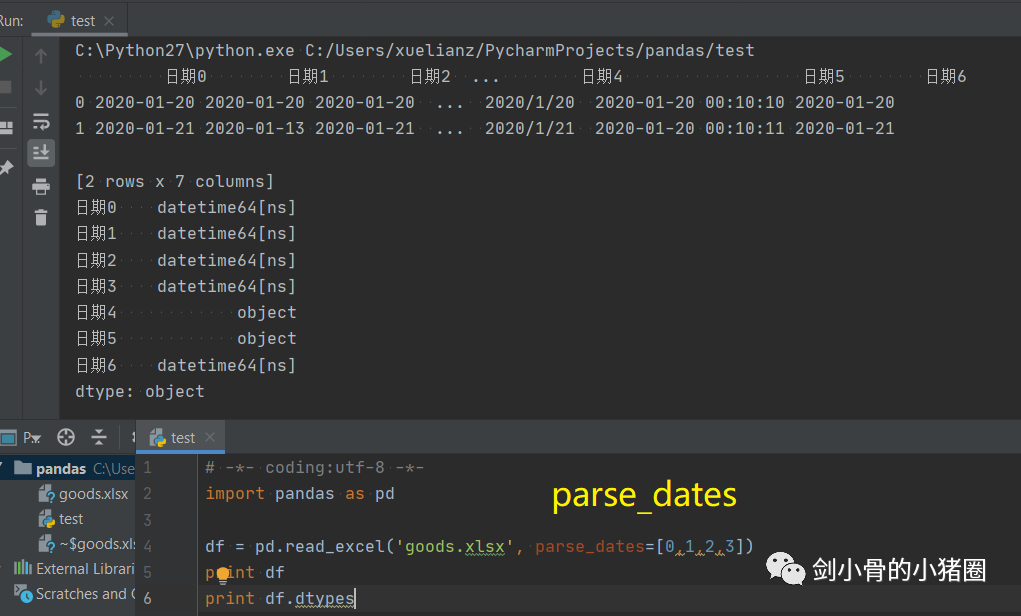
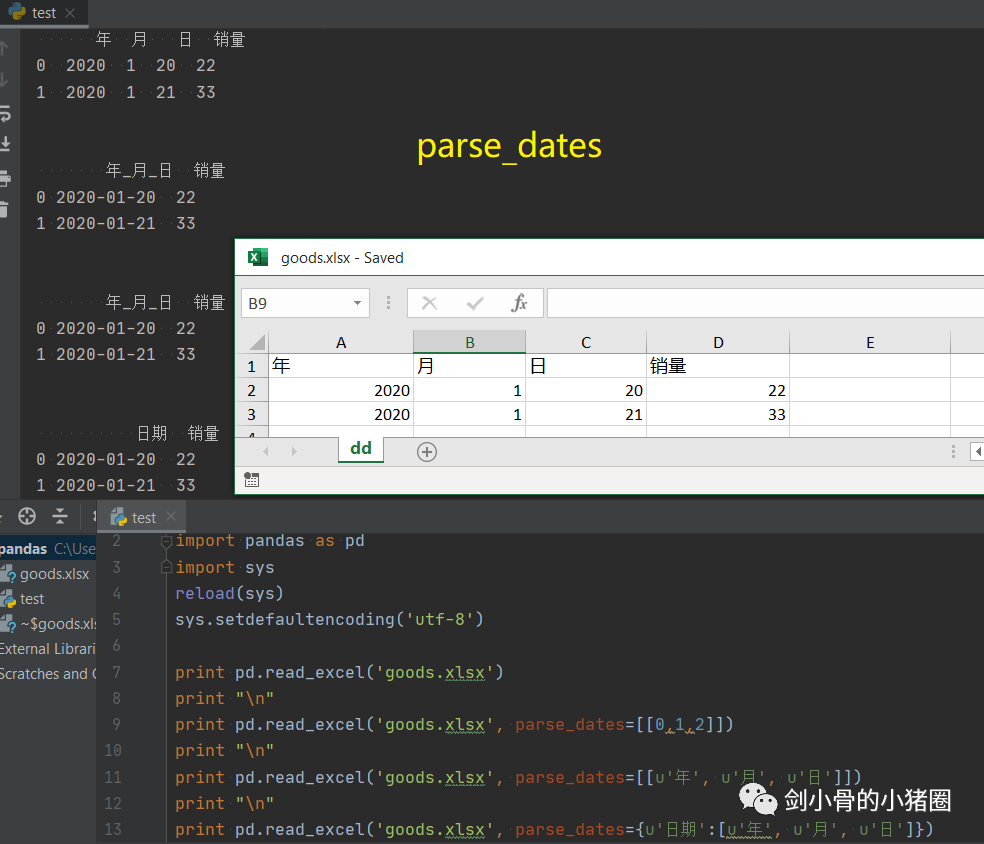
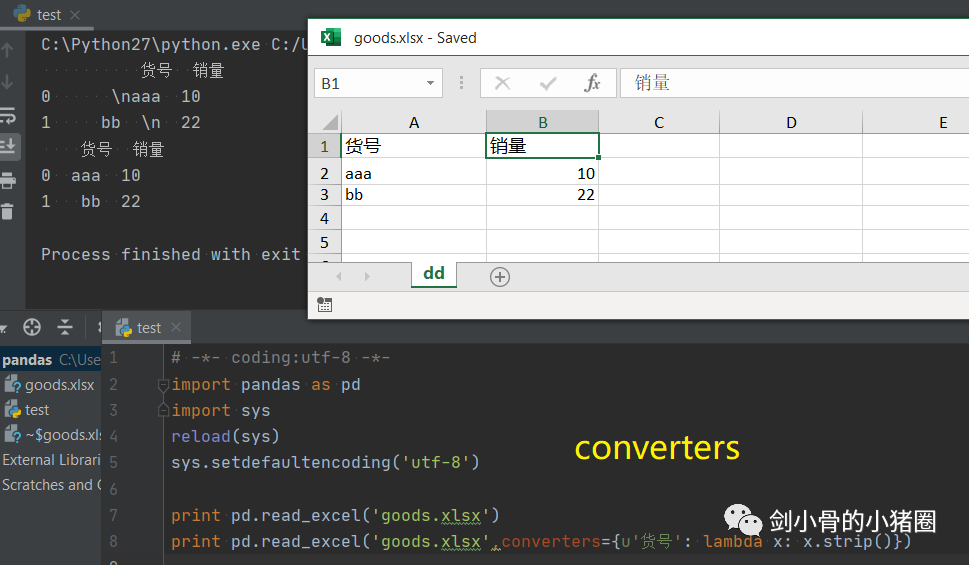
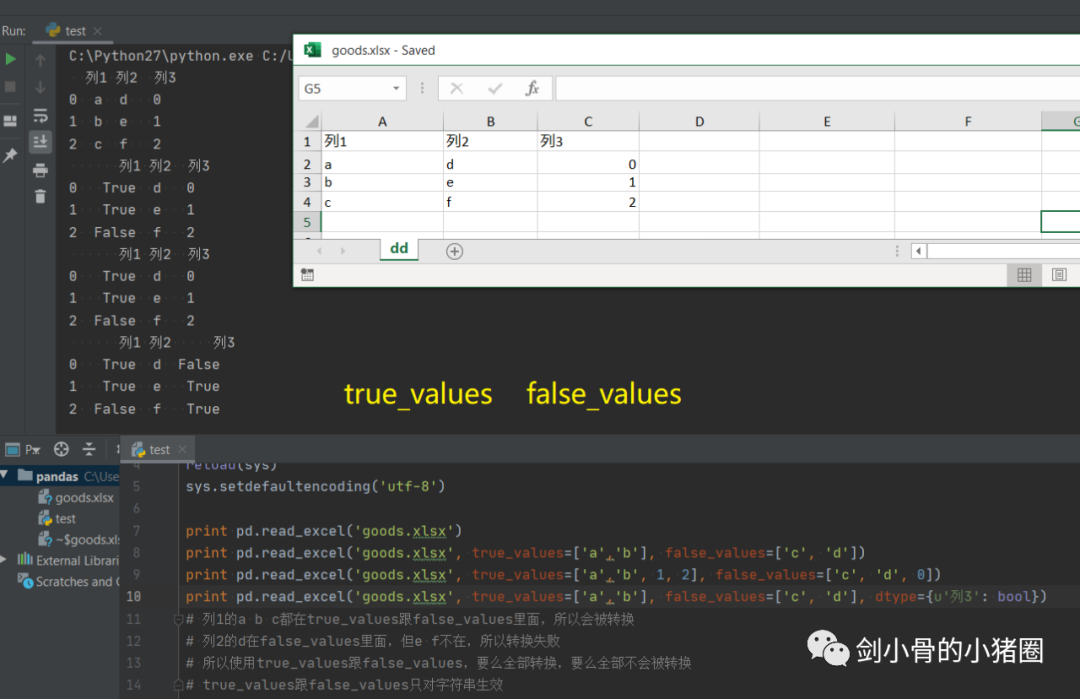
实际情况中,这3种方式我们都不用,我们一般是直接读取一个excel表格,这就是一个DataFrame,我们都是通过这种方式来得到一个Series的。 创建DataFrame >>>import pandas as pd >>>list_2d = [[1,2],[3,4]] >>> df= pd.DataFrame(list_2d, columns=['A','B'], index=['x','y']) # 创建DataFrame方法一,通过2维的list-like创建 >>> df A B x 1 2 y 3 4 >>> d ={'a':[1,3], 'b':[2,4]} # 创建DataFrame方法二,通过字典创建,字典的key作为列索引 >>> df= pd.DataFrame(d) >>> df a b 0 1 2 1 3 4 >>> df= pd.DataFrame(d, index=['x','y']) >>> df a b x 1 2 y 3 4 >>> df= pd.read_excel('goods.xlsx') # 创建DataFrame方法三,通过读取Excel表 >>> df 货号 商品代码 颜色代码 商品名称 品牌 成本 季节 商品年份 0 QTVW434 QTVW 5600 羽绒服 A 122 四季 2019 1 ACDA5352 ACDA 4322 棉服 B 55 冬季 2018 2 QTVW331 QTVW 2133 羽绒服 A 122 四季 2019 >>> read_excel()常用参数 pandas.read_excel( io, # 路径,StringIO,URL parse_dates=False, # 指定解析成日期格式的列 # True 尝试解析index # [0,1]或[‘a’,’b’] 尝试解析指定列作为一个单独的日期列 # [[0,1,2]] 结合多列解析为单个日期列 # {‘日期’:[0,1,2]} 结合多列解析为单个日期列,结果的列名改为‘日期’ date_parser=None, # function,解析日期格式的函数 sheet_name=0, # 选择子表(sheet),默认0选第0个 # int 选择第几个sheet,从0开始 # str sheet名字 # list: [0,‘2月’],返回字典,字典里面会保存多个DataFrame对象 # None全部sheet,返回字典 nrows # init, 默认None,要解析的行数 header=0, # 指定作为‘列索引’的行 index_col=None, # 指定作为‘行索引’列 usecols=None, # None默认全部 # str ‘A,C’(A列和C列) ‘A,C:E’(A列,C列至E列) # int-list [0,2](第0列和第2列) # str-list [‘AAA’,‘CCC’](AAA列和CCC列),建议用这种方法,代码可读性比较好,而且有时候可能会增加删减列,这样的话index就会变,代码就需要重写,而列名通常不改。 # 函数 lambda x:x=’CCC’ skiprows=None, # 跳过行 names 要使用的列名列表。如果文件不包含标题行,则应显式传递header=None dtype 字典,{‘列名’:‘类型’},设置列的类型,每一个列都是一个Series,通过dtype可以设置这个Series的类型,便于我们后期数据处理 # int8/int16/int32/int64(默认) 整型 #float16/float32/float64(默认) 浮点型 # str/string 字符串 # bool 布尔型 # category 分类 # datatime64[ns] 时间戳(纳秒) # period[Y/M/D] 时间周期(年/月/日) # object python对象混合类型 converters # dict,默认None,值转换函数 true_values # list,默认None 传入的list元素列为视为True的值 false_values # list,默认None 传入的list元素列为视为False的值 ) 示例: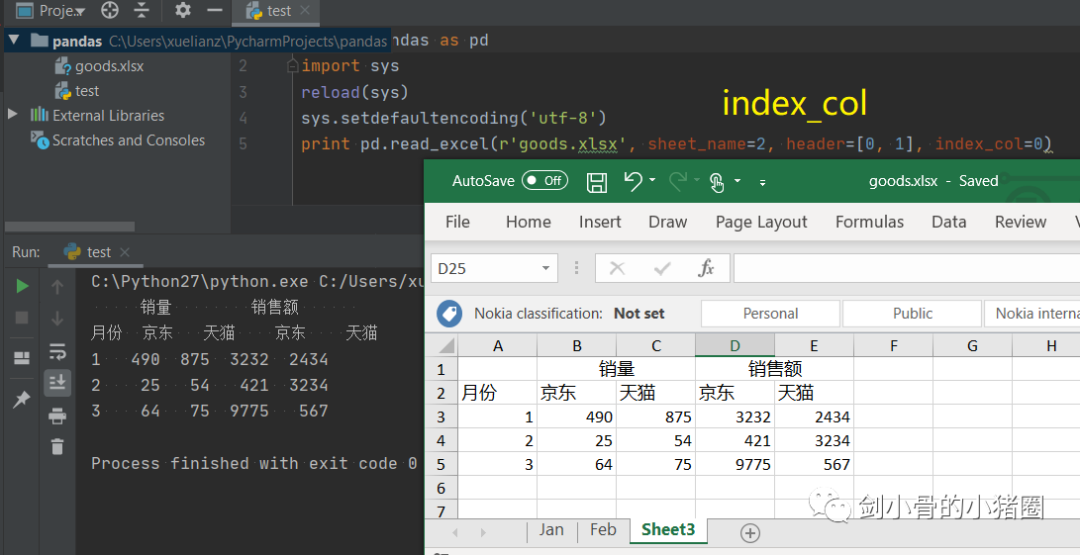















 782
782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









