



 LinkedHashMap是HashMap的子类,提供有序迭代。它通过维护一个双向链表,保证了插入顺序或访问顺序的排序。文章详细介绍了其继承结构、基本属性、构造方法、Entry定义、put()和get()方法,以及两种遍历顺序。适用于需要有序迭代的场景,如LRU缓存。
LinkedHashMap是HashMap的子类,提供有序迭代。它通过维护一个双向链表,保证了插入顺序或访问顺序的排序。文章详细介绍了其继承结构、基本属性、构造方法、Entry定义、put()和get()方法,以及两种遍历顺序。适用于需要有序迭代的场景,如LRU缓存。
- 阿里架构师总结Spring核心系列:Spring,Cloud,Spring5,MVC等
- 三次阿里凉凉后,15天封闭式复习,终于赶上了“腾讯”末班车
概述
LinkedHashMap是HashMap的子类,它的大部分实现与HashMap相同,两者最大的区别在于,HashMap的对哈希表进行迭代时是无序的,而 LinkedHashMap对哈希表迭代是有序的,LinkedHashMap默认的规则是,迭代输出的结果保持和插入key-value pair的顺序一致(当然具体迭代规则可以修改)。LinkedHashMap除了像HashMap一样用数组、单链表和红黑树来组织数据外,还额外维护了一个 双向链表,每次向linkedHashMap插入键值对,除了将其插入到哈希表的对应位置之外,还要将其插入到双向循环链表的尾部。
下面是它的数据结构:

我们可以看出它是由 数组 + 一个单项链表+一个双向链表组成。在原HashMap的数据结构基础上加一个双向链表
LinkedHashMap
继承结构

LinkedHashMap也就是继承HashMap,所以HashMap大都方法,它是可以直接使用的。

顶部的注释总结一下:
- 底层是散列表和双向链表
- 允许为null,不同步
- 插入的顺序是有序的(底层链表致使有序)
- 装载因子和初始容量对LinkedHashMap影响是很大的~
基本属性
//双向链表的头节点 transient LinkedHashMap.Entry head; //双向链表的尾节点 transient LinkedHashMap.Entry tail; //排序的规则,false按插入顺序排序,true访问顺序排序 final boolean accessOrder; //所以说accessOrder的作用就是控制访问顺序,设置为true后每次访问一个元素,就将该元素所在的Node变成最后一个节点, 改变该元素在LinkedHashMap中的存储顺序。构造方法
//LinkedHashMap的构造方法,都是通过调用父类的构造方法来实现,大部分accessOrder默认为falsepublic LinkedHashMap(int initialCapacity, float loadFactor) { super(initialCapacity, loadFactor); accessOrder = false;}public LinkedHashMap(int initialCapacity) { super(initialCapacity); accessOrder = false;}public LinkedHashMap() { super(); accessOrder = false;}public LinkedHashMap(Map extends K, ? extends V> m) { super(m); accessOrder = false;}public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder;}上面是LinkedHashMap的构造方法,通过传入初始化参数和代码看出,LinkedHashMap的构造方法和父类的构造方法,是一一对应的。也是通过super()关键字来调用父类的构造方法来进行初始化,唯一的不同是最后一个构造方法,提供了AccessOrder参数,用来指定LinkedHashMap的排序方式,accessOrder =false -> 插入顺序进行排序 , accessOrder = true -> 访问顺序进行排序。
Entry定义
这个比较重要
private static class Entry extends HashMap.Entry { //定义Entry类型的两个变量,或者称之为前后的两个指针 Entry before, after; //构造方法与HashMap的没有区别,也是调用父类的Entry构造方法 Entry(int hash, K key, V value, HashMap.Entry next) { super(hash, key, value, next); } //删除 private void remove() { before.after = after; after.before = before; } //插入节点到指定的节点之前 private void addBefore(Entry existingEntry) { after = existingEntry; before = existingEntry.before; before.after = this; after.before = this; } //方法重写,HashMap中为空 void recordAccess(HashMap m) { LinkedHashMap lm = (LinkedHashMap)m; if (lm.accessOrder) { lm.modCount++; remove(); addBefore(lm.header); } } //方法重写 ,HashMap中方法为空 void recordRemoval(HashMap m) { remove(); }}到这里已经可以知道,相对比HashMap,LinkedHashMap内部不光是使用HashMap中的哈希表来存储Entry对象,还另外维护了一个LinkedHashMapEntry,这些LinkedHashMapEntry内部又保存了前驱跟后继的引用,可以确定这是个双向链表。而这个LinkedHashMapEntry提供了对象的增加删除方法都是去更改节点的前驱后继指向。
put()方法
LinkedHashMap并没有重写父类的put()方法,说明调用put方法时实际上调用的是父类的put方法。HashMap的put这里就不多说了中有这样一个方法
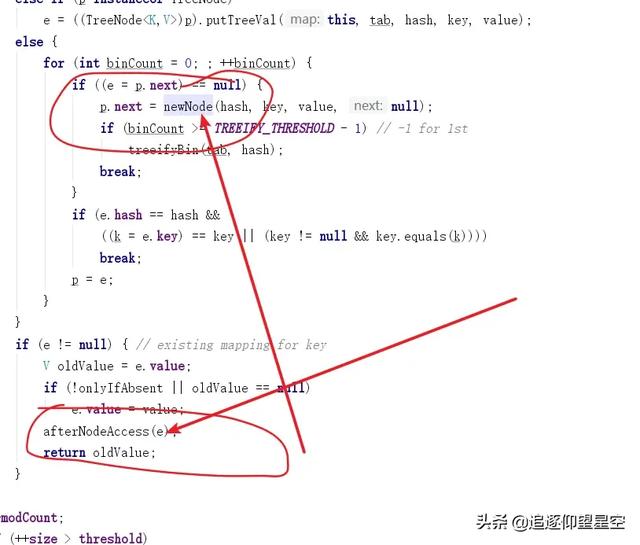
LinkedHashMap 重写了2个方法
ode newNode(int hash, K key, V value, Node e) { LinkedHashMap.Entry p = new LinkedHashMap.Entry(hash, key, value, e); linkNodeLast(p); return p; } private void linkNodeLast(LinkedHashMap.Entry p) { //用临时变量last记录尾节点tail LinkedHashMap.Entry last = tail; //将尾节点设为当前插入的节点p tail = p; //如果原先尾节点为null,表示当前链表为空 if (last == null) //头结点也为当前插入节点 head = p; else { //原始链表不为空,那么将当前节点的上节点指向原始尾节点 p.before = last; //原始尾节点的下一个节点指向当前插入节点 last.after = p; } } //把当前节点放到双向链表的尾部 2 void afterNodeAccess(HashMap.Node e) { // move node to last 3 LinkedHashMap.Entry last; 4 //当 accessOrder = true 并且当前节点不等于尾节点tail。这里将last节点赋值为tail节点 5 if (accessOrder && (last = tail) != e) { 6 //记录当前节点的上一个节点b和下一个节点a 7 LinkedHashMap.Entry p = 8 (LinkedHashMap.Entry)e, b = p.before, a = p.after; 9 //释放当前节点和后一个节点的关系10 p.after = null;11 //如果当前节点的前一个节点为null12 if (b == null)13 //头节点=当前节点的下一个节点14 head = a;15 else16 //否则b的后节点指向a17 b.after = a;18 //如果a != null19 if (a != null)20 //a的前一个节点指向b21 a.before = b;22 else23 //b设为尾节点24 last = b;25 //如果尾节点为null26 if (last == null)27 //头节点设为p28 head = p;29 else {30 //否则将p放到双向链表的最后31 p.before = last;32 last.after = p;33 }34 //将尾节点设为p5 tail = p; //LinkedHashMap对象操作次数+1,用于快速失败校验 ++modCount; } }通过重写put方法,来维护一个双向链表,使得存取有序。。
get()方法
public V get(Object key) { Entry e = (Entry)getEntry(key); //调用父类的getEntry()方法 if (e == null) return null; e.recordAccess(this); //判断排序方式,如果accessOrder = true , 删除当前e节点 return e.value;}相比于 HashMap 的 get 方法,这里多出了第 5,6行代码,当 accessOrder = true 时,即表示按照最近访问的迭代顺序,会将访问过的元素放在链表后面。
总结
LinkedHashMap比HashMap多了一个双向链表的维护,在数据结构而言它要复杂一些,阅读源码起来比较轻松一些,因为大多都由HashMap实现了..
阅读源码的时候我们会发现多态是无处不在的~子类用父类的方法,子类重写了父类的部分方法即可达到不一样的效果!
比如:LinkedHashMap并没有重写put方法,而put方法内部的newNode()方法重写了。LinkedHashMap调用父类的put方法,里面回调的是重写后的newNode(),从而达到目的!
LinkedHashMap可以设置两种遍历顺序:
- 访问顺序(access-ordered)
- 插入顺序(insertion-ordered)
- 默认是插入顺序的
对于访问顺序,它是LRU(最近最少使用)算法的实现,要使用它要么重写LinkedListMap的几个方法(removeEldestEntry(Map.Entry eldest)和afterNodeInsertion(boolean evict)),要么是扩展成LRUMap来使用,不然设置为访问顺序(access-ordered)的用处不大,对于LinkedHashMap的LRU这边没有深入了,因为确实用的不多,但是大家有兴趣的可以深入研究。
LinkedHashMap遍历的是内部维护的双向链表,所以说初始容量对LinkedHashMap遍历是不受影响的
一句话。LinkedHashMap就是继承HashMap的加上双向链表的HashMap,所以讲的也不多
版本说明
- 这里的源码是JDK8版本,不同版本可能会有所差异,但是基本原理都是一样的。
- Map家族讲完,整个集合体系,还差一个Set。明天开始Set
作者:六脉神剑
原文链接:https://juejin.im/post/5def59a36fb9a0162712765e


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









