





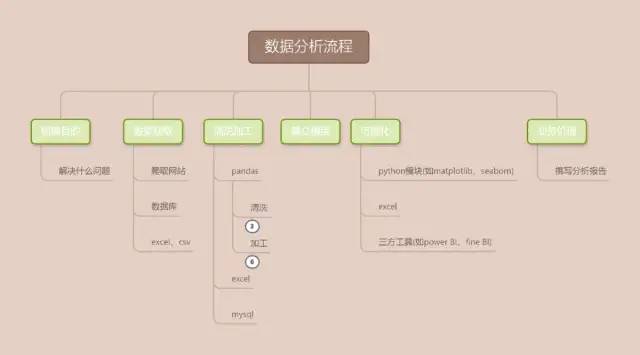
做数据分析相关工作,无论是做周报,月报还是专题分析,我们都要遵循数据分析流程,如下六个步骤:
一、观察数据
下载demo数据集
链接:https://pan.baidu.com/s/1-E-JBMslMqsDm6r2LZVT6w
提取码:r9bf
1、引入 pandas 和 numpy 包,从给出的路径读数据集
import pandas as pd
import numpy as np
data = pd.read_csv('C:/Users/cherich/Desktop/datas/foods.csv',encoding='gbk')
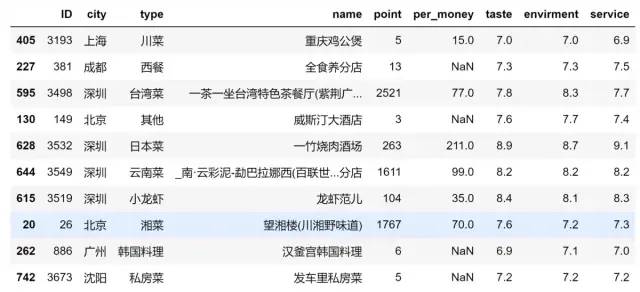
2、查看数据,主要有以下方法,大家可以自己试下效果
① 随机打印出数据集的十行
data.sample(10)
② 查看几行几列
data.shape
③ 查看数据情况,比如均值,标准差,最大值等
data.describe()
④打印出数据集的前五行
data.head()
⑤打印数据集的后五行
data.tail()
⑥查看数据缺失值(也就是空值)情况
data.info()

我们看到per_money字段是存在缺失值的,那我们如何处理呢。
二、处理缺失值
现在我们知道了数据集中存在缺失值,处理缺失值有两种方法
1、删除
2、填充
首先过滤下有多少缺失值
# 方法一
data[data['per_money'].isnull()==False]
# 方法二
data[data['per_money'].notnull()==True]
# 方法三
total_missing = data.isnull().sum()
total_cells = len(data)
# 缺失值的百分比
print((total_missing/total_cells) * 100)

可以进一步看看数据集中缺失值的数目占总数的百分比,结果约为 29%,四分之一的数据都缺失了!
接下来,我们要分析出现缺失值的原因,如果一个数据值缺失是因为它根本不存在,那么我们就没有必要去猜它可能的值,我们需要做的就是让它继续为 NaN;如果一个数据值缺失是因为没有被记录,我们就应该基于与它同行同列的其他值,来猜想它的可能值。像我们本数据集中的情况,明显是因为没有被记录,需要对它删除。
1、删除
①drop():单纯的删除数据
语法格式:df.drop(labels=None,axis=0, index=None, columns=None, inplace=False)
① labels :是要删除的⾏列的名字,⽤列表给定。
② axis :axis=1表示列,axis=0表示⾏
③ index:直接指定要删除的⾏。
⑥ columns:直接指定要删除的列。
⑦ inplace=False:默认该删除操作不改变原数据,⽽是返回⼀个执⾏删除操作 后的新 dataframe。
⑧ inplace=True:则会直接在原数据上进⾏删除操作,删除后⽆法返回。
删除⾏列有两种⽅式
data.head()
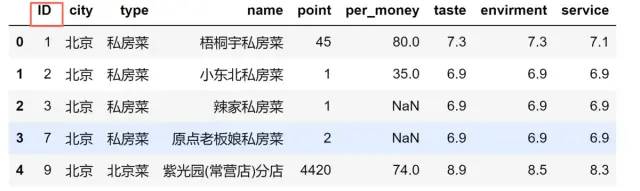
我们想要删除ID列
方法一 :labels='列名',axis=1的组合
data.drop(labels='ID',axis=1,inplace=True)
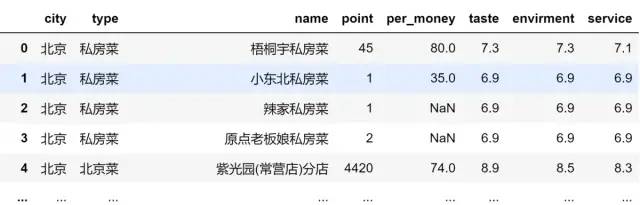
方法二:index或columns直接指定要删除的⾏或列
data.drop(columns='ID',inplace=True)
②dropna():默认将只要含有NaN的整⾏数据删掉
语法格式:df.dropna(axis=0, how='any', thresh=None, inplace=False)
对列做删除操作,需要添加axis参数,axis=1表示列,axis=0表示⾏
删除整⾏都是空值的数据需要添加how='all'参数 ,举栗子如下:
df = pd.DataFrame([[1,2,np.nan],[np.nan,np.nan,np.nan],[np.nan,np.nan,4]],columns=['a','b','c'])
df
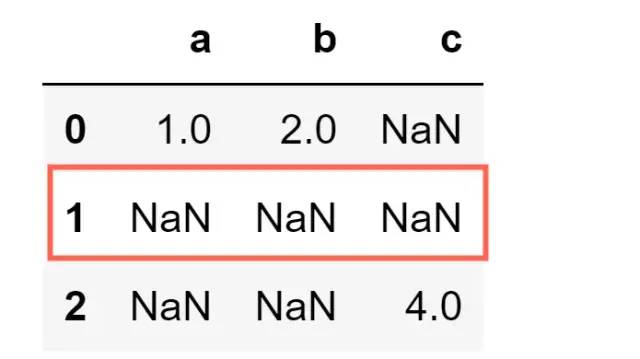
df.dropna(how='all')
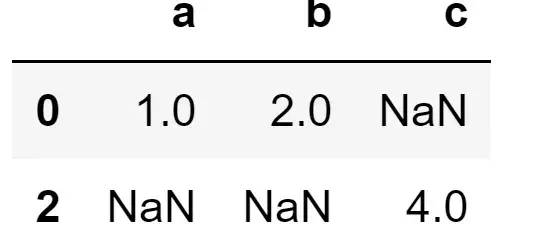
thresh参数筛选想要删除的数据,thresh=n保留⾄少有n个⾮NaN数据的⾏,举个栗子:
df = pd.DataFrame([[1,2,np.nan],[np.nan,np.nan,np.nan],[np.nan,np.nan,4]],columns=['a','b','c'])
df.dropna(thresh=2)
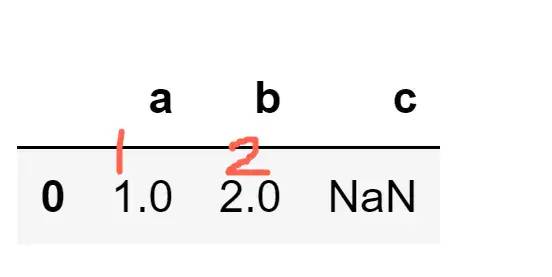
像我们本文的数据集,我们只需要把空值删掉就好,我们看到含有Nan的行就删除了
data.dropna(inplace=True)
data
2、填充
fillna()
语法格式:df.fillna(value=None, method=None, axis=None, inplace=False, limit=None)
method=‘ffill’表示用前面行/列的值,填充当前行/列的空值;bfill,则相反,举个栗子:
data.head()
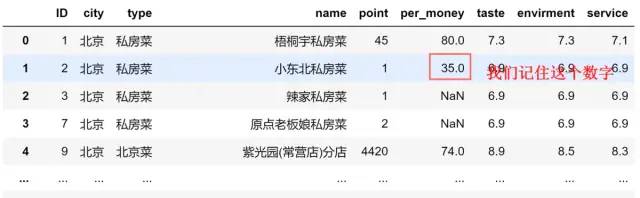
data.fillna(method='ffill')
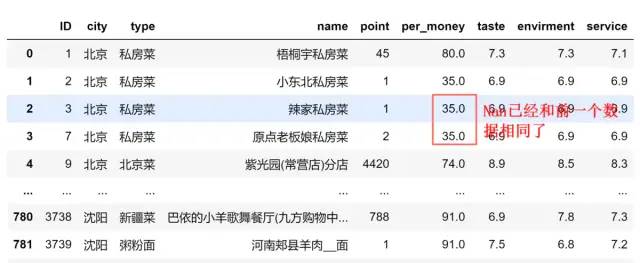
limit=n 表示最多填补n个,举个栗子:
data.fillna(method='ffill',limit=1)
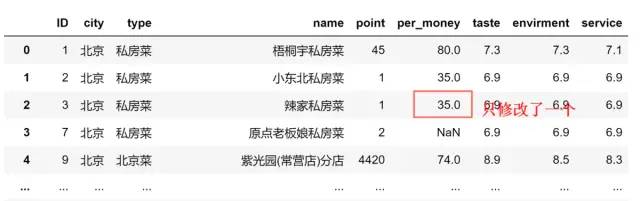
注意:method参数不能与value参数同时出现
三、删除重复值
1、duplicated() 函数可以判断是否重复
# 查看重复值
print(len(da[da.duplicated()==True]))
2、drop_duplicates()将重复的数据⾏进⾏删除
# 删除重复值
da.drop_duplicates(inplace=True)
希望本文的内容对大家的学习或者工作能带来一定的帮助,每天进步一点点,加油














 5344
5344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









