





什么是爬虫,爬虫能用来做什么?文章中给你答案。*_*
爬虫爬取斗鱼颜值池塘的主播美照..
今天我们就开发一个简单的项目,来爬取一下itcast.cn中c/c++ 教师的职位以及名称等信息。网站链接:http://www.itcast.cn/channel/teacher.shtml#ac

要爬取的网页链接
本教程将指导您完成以下任务:
- pycharm以及scrapy的安装
- scrapy的架构流程讲解
- 创建一个新的scrapy项目
- 编写蜘蛛以爬网站点并提取导出数据
一、pycharm以及scrapy的安装
pycharm是Python的解释器,为什么不用Python自带的ipython而用pycharm的IDE呢,是因为pycharm是可视化的IDE,窗口交互习惯比较好,并且有大量的方便功能。
安装的时候没有什么特殊的,下一步就好。
pycharm
scrapy的安装比较方便:如图一所示:在pycharm中FIle->settings->Project+项目名称->选择“+”->输入Scrapy->左下角的install package。等待一会就会自动安装并显示安装成功(如果有安装失败的,可以私信我解决)。
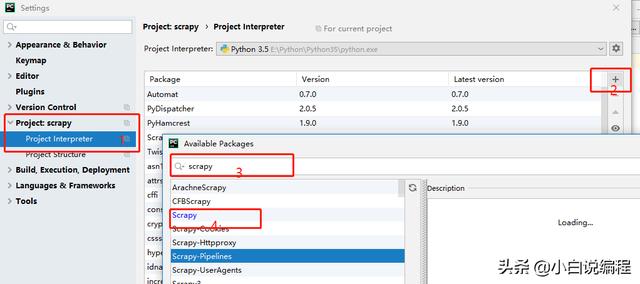
图一
二、Scrapy架构流程讲解。
如图二所示:
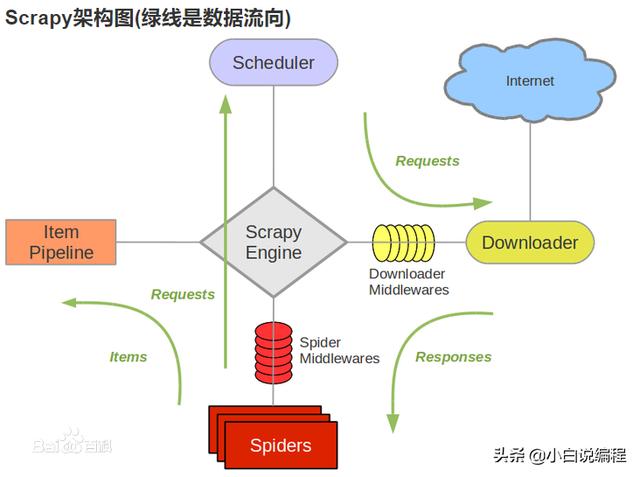
图二-scrapy 架构流程图
1、首先Spiders(爬虫)将需要发送请求的url(requests)经ScrapyEngine(引擎)交给Scheduler(调度器),这个是需要我们手动敲代码必要部分。
2、Scheduler(排序,入队)处理后,经ScrapyEngine,DownloaderMiddlewares(可选,主要有User_Agent, Proxy代理)交给Downloader。
3、Downloader向互联网发送请求,并接收下载响应(response)。将响应(response)经ScrapyEngine,SpiderMiddlewares(可选)交给Spiders。
4、Spiders处理response,提取数据并将数据经ScrapyEngine交给ItemPipeline保存(可以是本地,可以是数据库)。提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无Url请求程序停止结束。
5、DownloaderMiddlewares(下载中间件)以及SpiderMiddlewares(爬虫中间件)不是必要的可以省略(如果你要爬取的网页有反爬虫机制,则需要用到)。
三、创建一个新的scrapy项目
创建scrapy项目的时候用cmd环境,命令行方式创建,scrapy会自动给我增加一些文件和选项。省去爬虫开发者大量的时间。
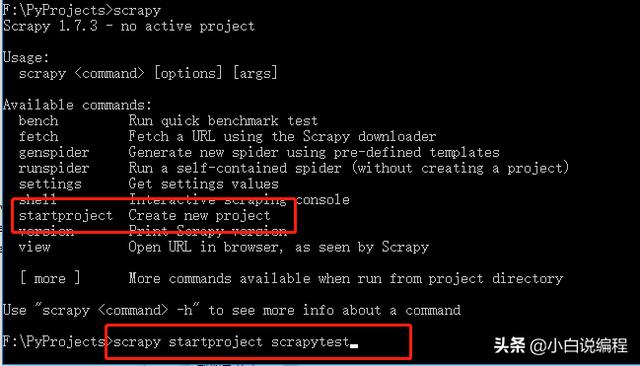
图三-创建scrapy项目
然后我们打开工程可以看一下,scrapy会自动生成这个几个文件:
spiders目录:我们的爬虫文件的所在目录也是我们要开发爬虫的文件位置;
items.py:要爬取的数据字段
middlewares.py:中间件(下载中间件和爬虫中间件)都在这个位置
piplines.py:管道文件存放我们筛选过的数据
settings.py:scrapy的配置文件,所有的设置都可以写在配置文件中
接下来就是创建我们的爬虫文件了 有两种方法:
a.用scrapy命令行:scrapy genspider myspider -t "itcast.cn"
解释一下 genspider 是生成爬虫
myspider 是我们的爬虫名字,后续启动爬虫也是需要这个名字
itcast.cn 是我们本次爬虫要爬取的网站域名
b.在pycharm中的spiders目录下新建一个文件也可以。
我们一般用第一种,因为scrapy可以帮我们写部分代码。*_*
到此为止我们的爬虫项目就建立完毕。接下来就是利用scrapy框架写代码获取数据。
四、编写蜘蛛以爬网站点并提取数据
1.items.py
再此处我们写上自己要回去的网站的一些内容。会映射到相应的变量上。
class ScrapytestItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
2.写我们的爬虫文件
import scrapy
from ScrapyTest.items import ScrapytestItem
class MyspiderSpider(scrapy.Spider):
name = 'myspider' # 爬虫名
allowed_domains = ['www.itcast.cn'] # 要爬取网站的域名,不在此域内的网站不爬取。
# 要爬取的网站
start_urls = ['http://www.itcast.cn/channel/teacher.shtml#ac']
# 下载器返回的网页请求连接
def parse(self, response):
# //div[@class='li_txt']/p xpath方法获取相应的字段
print("*" * 100)
items_xpath_list = response.xpath("//div[@class='li_txt']")
# print(items_xpath_list)
# 存放教师信息列表
items = []
for item_xpath in items_xpath_list:
# 创建一个item 并赋值会返回pipelines中
item = ScrapytestItem()
name = item_xpath.xpath("./h3/text()").extract()
title = item_xpath.xpath("./h4/text()").extract()
info = item_xpath.xpath("./p/text()").extract()
item['name'] = name
item['title'] = title
item['info'] = info
#items.append(item)
yield item
return item
3.pipelines.py
import json
class ScrapytestPipeline(object):
def __init__(self):
self.f = open("myspider.json















 1063
1063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









