





一、索引是如何加速查询的
1.磁盘预读
由于磁盘的存取速度比主存慢很多,所以为了提高效率,要尽量减少磁盘IO,为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。

空间局部性原理:如果一个存储器的某个位置被访问,那么它附近的位置也会被访问。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页的大小通常为4k),主存和磁盘以页为单位交换数据。
2.索引如何加速查询
假设有10000条数据,每条数据1KB,每页存4条,共2500页,如果要查找一条数据。即使数据页按序存储,用二分查找最差也需要log2(2500)=12次。忽略页内数据比较时间,假设每页寻址时间10ms,一共需要0.12s。 使用索引后(假设索引列为int类型),记录每页开始数据的索引值和页的物理地址,int类型占用4个字节,物理地址假设用6个字节,那么1页就可以存4096/10=409个数据页的索引值,2500/409=6.11,log2(7)=3,即最多3次就可以找到数据,一共需要0.03s,查找次数大大减少,从而降低查询时间。MySQL中,InnoDB存储引擎每次读取的页大小为16K,可以通过命令 :
show global status like ‘Innodb_page_size’查看MySQL的页大小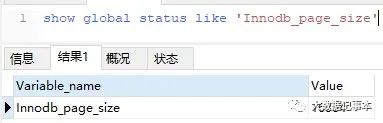
索引:排好序的用于加速查询的数据结构。可以用来保存索引的数据结构包括:
1.Hash表:对索引列的值计算hashcode,然后以hash值为key,数据地址指针为value保存在哈希表中,MySQL中的Memory引擎就是用hash这种结构保存索引。
缺点:
需要将索引一次性加载到内存,对内存压力大;
只能等值查询,不适合范围查询;
不支持部分索引列匹配,因为需要根据所有索引列的值计算hashcode;
- 优化器无法使用Hsah来加速Order by查询。
2.平衡二叉树/红黑树:通过树左子结点的值小于等于父节点,右子节点的值大于等于父节点的特性,对索引列的值进行排序。
缺点:数据量非常大时,内存不够用,大部分数据只能存放在磁盘上,只有需要的数据才加载到内存中。而由于每个父结点只能有两个子结点,n层树只能存放2^n-1条数据,树的高度会很高,这样就导致了查找数据需要很多次的磁盘IO。
3.B树/B-树:B树是一棵自平衡的搜索树,它类似普通的平衡二叉树,不同的一点是B-树允许每个结点有更多的子结点。B-树是专门为外部存储器设计的,如磁盘,它对于读取和写入大块数据有良好的性能,所以一般被用在文件系统及数据库中。
特性:
所有键值分布在整棵树所有结点中;
搜索有可能在非叶子结点结束,在关键字全集内做一次查找,性能逼近二分查找;
任何一个索引值出现且只出现在一个结点中;
每个结点最多拥有m个子树(m为阶或叫度),即拥有m个指针指向子结点
所有叶子结点都在同一层,每个结点最多可以有m-1个key,且以升序排列。
根节点至少有2个子树
分支结点至少拥有m/2棵子树(除根结点和叶子结点外都是分支结点)

B树的每个结点,都是存多个值的。把每个结点分成了多个范围区间,区间更多的情况下,搜索也就更快了,比如:有1-100个数,二叉树一次只能分两个范围,0-50和51-100,而B树(假设为3阶),分成4个范围 1-25, 25-50,51-75,76-100一次就能过滤掉四分之三的数据。故B树的查找更快。
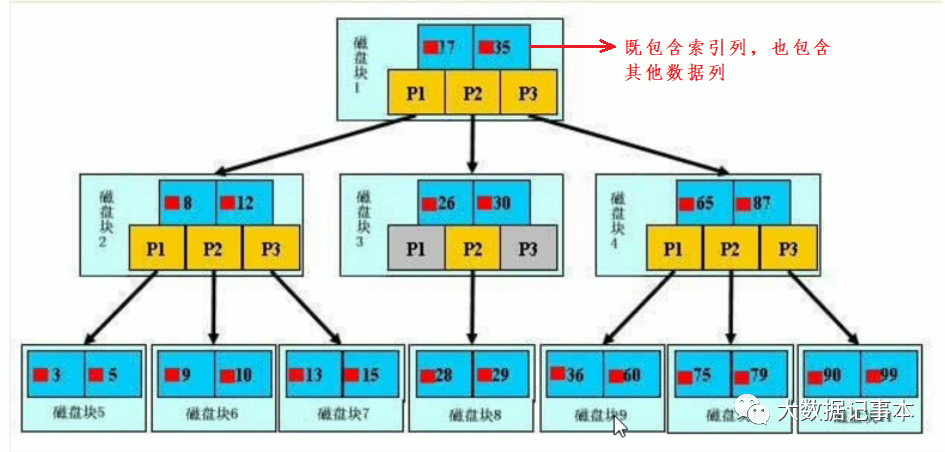
假设每个结点有n个key值,结点被分为n+1个区间,n个key值和对应的数据都在该结点。一般根结点是缓存在内存中的,一个结点为一次磁盘IO。上图中,如果要查找28,首先在根结点进行二分查找,判断17<28<35,定位到中间P2所指的节点,然后进行一次磁盘IO,读入磁盘块3;再次进行二分查找,判断26<28<30,读入磁盘块8,进行一次磁盘IO,然后在磁盘块8中找到数据。
4.B+树:B+树是B-树的变体,也是一种多路搜索树, 它的非叶子结点不存数据,只存索引值,而且为所有叶子结点增加了一个链指针(即通过链表将所有叶子结点连接起来),从而实现顺序查找。
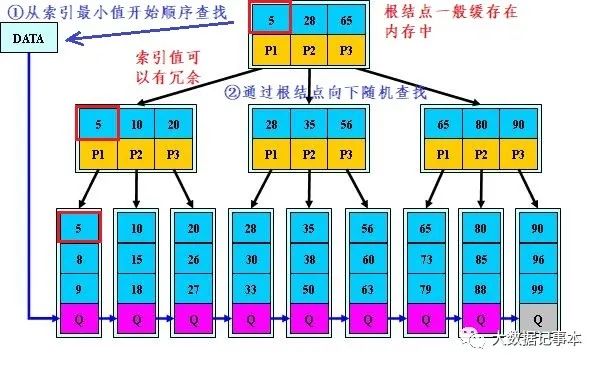
B树和B+树的区别
B+树非叶子结点不存储数据,所有 data 存储在叶结点导致查询时间复杂度固定为 log n。而B-树查询时间复杂度不固定,与 key 在树中的位置有关,最好为O(1)。
B+树每次查询访问的结点数一样,查询更加稳定。
B+树每个结点的索引列值数量和子结点数相同,而B树每个结点的索引列值数量比子结点少1个。
B+树中的索引列值允许有冗余,即多个结点保存相同的索引值,而B树的索引值出现且只出现在一个结点中。
- B+树叶节点两两相连可大大增加区间访问性,可使用在范围查询等,而B树每个节点 key 和 data 在一起,区间查找困难。
举例对比B树和B+树的存储
假设索引列为int类型,占用4个字节,指向子结点的指针大概占6个字节,一条数据1K,那么B树每个磁盘页(16K)可以存储的数据大概为:16*1024-6 /(1024+10)≈ 16条,三层存满可以存16^3=4096条;而B+树非叶子结点每个磁盘块可以存16*1024/10≈1638,叶子结点每个磁盘块可以存:16*1024-6/(1024+4)≈16条(叶子结点没有指向下一层的指针但有指向下一个叶子结点的指针),三层B+树可以存储的数据为:1638*1638*16=42,928,704,是B树的10000多倍。
综上:MySQL的索引选择了B+树这种数据结构,仅用少量的层数就可以存储大量的数据,大量减少磁盘IO来加速查询,同时叶子结点之间通过指针相连,更适合做范围查询。















 1081
1081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









