





XML技术(DOM、SAX解析XML)
1 掌握XML基本语法,命名规则
2 掌握什么是Schema,什么是DTD
3 掌握DOM解析XML
4 掌握SAX解析XML
5 掌握JDOM解析XML
6 掌握DOM4J解析XML
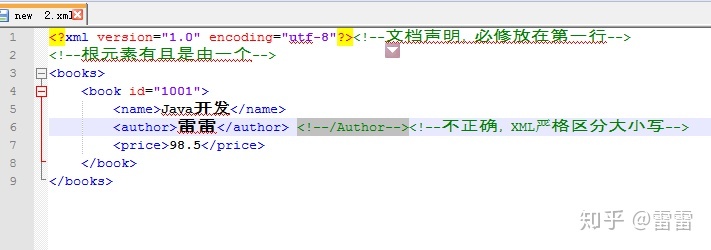
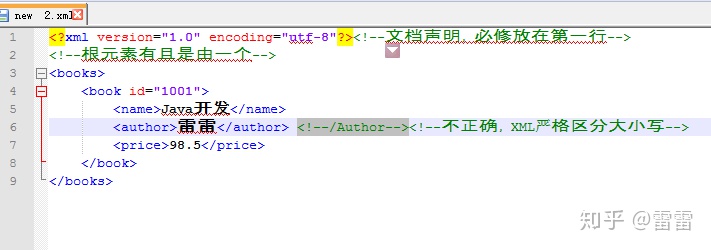
首先来写第一个简单的XML文档
以XML保存,打开浏览器,把文档拉到地址栏。如果出现这种情况证明你的XML书写是正确的。

1. XML(EXtensible Markup Language)概念和体系
(1) XML的特点:
XML的作用:数据存储和数据传输。XML的特点:数据以纯文本格式存储、实现不同应用程序之间的数据通信、实现不同平台间的数据通信、实现不同平台间的数据共享、使用XML将不同的程序不同的平台之间联系起来。
(2) 一个标准的XML文档由什么组成?
必须要有文档的声明,根元素(一个文档只能有一个根元素),根元素的子元素,文本(在xml中文本都是字符型)。
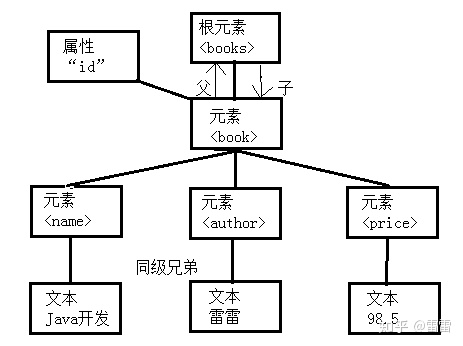
就刚刚写的book文档而言,books是book的父元素,book是books的子元素,XML的结构如下,这是一颗倒挂着的树:
2. XML基本语法:
① 有且只有一个根元素
② XML文档声明必须放在文档的第一行
③ XML的标签必须成对出现
④ XML的标签严格区分小写
⑤ XML必须正确嵌套
⑥ XML中属性值必须加引号
⑦ XML中,一些特殊字符需要使用“实体”
⑧ XML中可以应用适当的注释
XML的命名规则:
名称可以包含字母,数字以及其他字符。
名称不能以数字或标点符号开始,名称不能包含空格。
3. Schema技术:
(1) 什么是DTD验证及DTD验证的局限性?
DTD文档类型定义,验证是否是“有效”的XML。
使用DTD的局限性:DTD不遵守XML语法、DTD数据类型有限、DTD不可扩展、不支持命名空间。
(2) 什么Schema技术?
Schema是DTD的代替者,名称为 XML Schema ,用于描述XML文档结构,比DTD强大,最主要的特征之一就是XML Schema 支持数据类型。
① Schema是用XML验证XML遵循XML的语法。
② Schema可以用作处理XML文档的工具处理。
③ Schema大大扩充了数据类型,而且还可以自定义数据类型。
④ Schema支持元素的继承
4. DOM方式解析XML数据
(1) 解析XML文件的方式有哪些:
① DOM解析(官方提供)
② SAX解析(官方提供)
③ JDOM解析(第三方提供)
④ DOM4J解析(第三方提供)
(2) DOM解析XML的步骤:
① 创建一个DocumentBuilderFactory的对象
② 创建一个DocumentBuilder对象
③ 通过该DocumentBuilder的parse方法的都Document对象
④ 通过getElementsByTagName(...)方法获取到节点的列表
⑤ 通过for循环遍历每一个节点
⑥ 得到每个节点的属性与属性值
⑦ 得到每个节点的节点名与节点值
>>>使用DOM解析XML文档(把XML中的数据读取到Java程序中)

Java程序:
package 运行之后得到的结果是酱紫的:这时候已经将XML文档中的数据读取出来了

5. SAX方式解析XML数据
(1) SAX解析方式:
SAX(Simple API for XML),是一种以事件驱动的XML API,SAX与DOM不同的是它边扫描边解析,
自顶向下依次解析,由于边扫描边解析,所以它解析XML具有速度快,占用内存少的优点。
(2) SAX解析XML的步骤:
① 创建SAXParserFactory的对象
② 创建SAXParser对象(解析器)
③ 创建一个DefaultHandler的子类
④ 调用parse方法
老规矩,实操一下。创建一个子类BookDeaultHandler继承DefaultHandler(org.xml.sax.helpers.DefaultHandler;)是这个包下的DefaultHandler
package XML;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class BookDeaultHandler extends DefaultHandler {
//重写第一个方法
/*解析xml文档开始时调用*/
@Override
public void startDocument() throws SAXException {
super.startDocument();
System.out.println("------解析xml文档开始--------");
}
/*解析xml文档结束时调用*/
@Override
public void endDocument() throws SAXException {
super.endDocument();
System.out.println("------解析xml文档结束--------");
}
/**解析xml文档中的节点时调用*/
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
super.startElement(uri, localName, qName, attributes);
/**判断如果是book节点,获取节点的属性与属性值*/
if("book".equals(qName)) {
//获取所有的属性
int count = attributes.getLength();//属性的个数
//循环获取每个属性
for(int i=0; i<count;i++) {
String attName = attributes.getQName(i);//属性名称
String attValue = attributes.getValue(i);
System.out.println("属性名称:"+attName+"t属性值:"+attValue);
}
}else if(!"books".equals(qName)&&!"book".equals(qName)) {
System.out.print("节点的名称:t "+qName+"t");
}
}
/**解析xml文档中的节点结束调用*/
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
super.endElement(uri, localName, qName);
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
super.characters(ch, start, length);
String value = new String(ch,start,length);
if(!"".equals(value.trim())) {
System.out.println(value);
}
}
}主程序:
package XML;
import java.io.IOException;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.SAXException;
public class TestSAXParse {
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
//创建SAXParserFactory的对象
SAXParserFactory spf = SAXParserFactory.newInstance();
//创建SAXParser对象(解析器)
SAXParser parser = spf.newSAXParser();
//创建一个DefaultHandler的子类
BookDeaultHandler bdh = new BookDeaultHandler();
//调用parse方法
parser.parse("book.xml",bdh);
}
}运行结果是这样子的:

6. JDOM解析XML数据
(1) 简述什么是JDOM?
是一种解析xml的Java工具包,它基于树型结构,利用纯Java的技术对xml文档实现解析。
(2) JDOM解析XML的步骤?
① 创建一个SAXBuilder对象
② 调用build方法,得到Document对象(通过IO流)
③ 获取根节点
④ 获取根节点节点的直接子节点的集合
⑤ 遍历集合
7. DOM4J解析XML数据
(1) 简述DOM4J技术 ?
是一个Java的XML API,是JDOM的升级品,用来读写XML文件。
(2) 四种解析XML技术的特点:
① DOM解析:形成了树结构,有助于更好的理解、掌握,且代码容易编写,解析过程中,树结构保存在内存中,方便修改。
② SAX解析:采用事件驱动模式,对内存消耗比较小适用于只处理XML文件中的数据。
③ JDOM解析:仅使用具体类,而不使用接口,API大量使用了Collection类。
④ DOM4J解析:是JDOM的一种智能分支,他合并了许多超出基本XML文档表示的功能。它使用接口和抽象基本类方法。具有性能优异、灵活性好、功能强大和极端易用的特点。是一个开放源码的文件。















 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









