






思来想去一段时间,各种查资料,这篇文章应该分享些什么好。想了想,还是从hadoop的几大模块开始讲起吧。
hadoop的四大模块
- Hadoop Common:为其他hadoop模块提供基础设施。
- Hadoop DFS:一个高可靠、高吞吐量的分布式文件系统
- Hadoop MapReduce:一个分布式的离线并进行计算框架 ——分布式计算框架
- Hadoop YARN:一个新的MapReduce框架,任务调度与资源管理 ——分布式资源管理框架
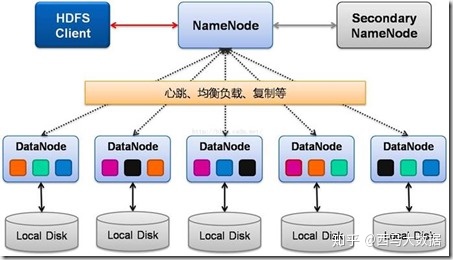
hdfs是一个分布式文件系统,采用的是master/slave架构,一个简单的HDFS集群主要是由NameNode和一定数量的DataNode构成。
NameNode是一个中心服务器,主要管理数据的节点,负责管理文件系统的namespace和客户端对文件的访问。
DataNode是一个大的数据分块存储的节点,负责数据的存储。
在文件存储过程中,一个文件其实会分成一个或多个block,这些block存储在Datanode集合里。Namenode执行文件系统的namespace操作,例如打开、关闭、重命名文件和目录,同时决定block到具体Datanode节点的映射。Datanode在Namenode的指挥下进行block的创建、删除和复制。
HDFS读过程:
- 1、打开分布式文件系统
- 2、向NameNode请求下载数据,并返回目标文件的元数据信息
- 3、去相应的DataNode节点下载数据
- 4、关闭数据流
public 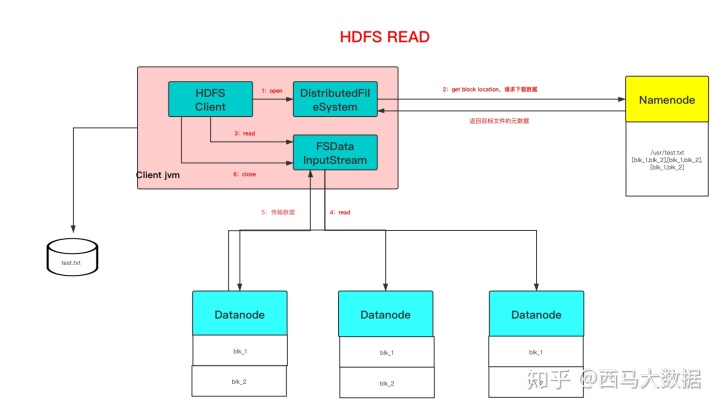
HDFS 写过程
- 1、创建分布式文件系统
- 2、向NameNode请求上传文件,并向client响应可以上传。
- 3、client端根据文件大小(默认是128M进行切分)上传第一个128M文件,并返回DataNode的节点信息
- 4、向DataNode节点写数据
- 5、关闭数据流
public 
Hadoop MapReduce 过程
MapReduce1
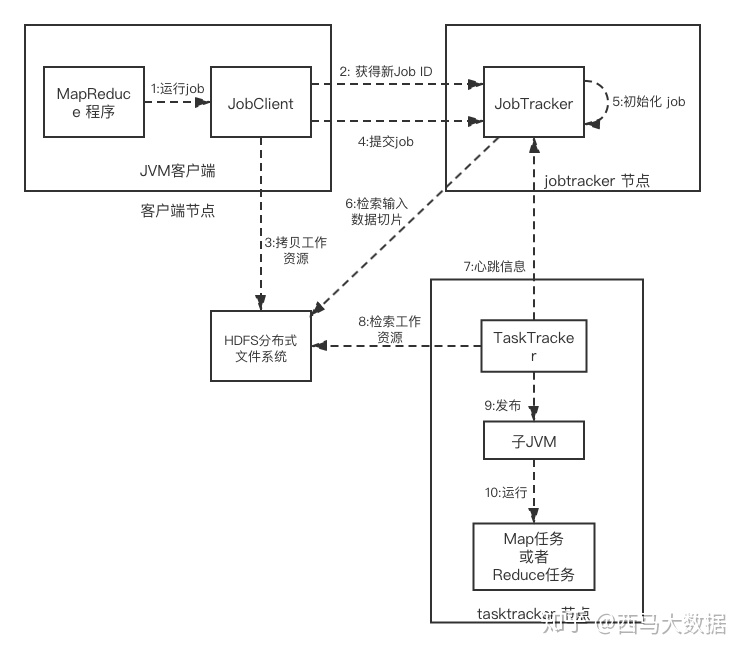
1.在客户端启动作业
通过submit或者waitForCompletion提交作业,waitForCompletion()方法通过每秒循环轮转作业进度
如果发现与上次报告有改变,则将进度报告发送到控制台。
其实waitForComplection()方法中还是调用submit()方法
2.向JobTracker申请Job ID
submit()方法中创建一个JobSubmitter实例,然后向JobTracker申请一个JobID
确定输出目录是否存在,如果存在那么JobTracker会抛出错误给客户端
检查输入目录是否存在,如果不存在同样抛出错误
根据输入计算输入分片(Input Split),如果分片计算不出来也会抛出错误
3.复制作业的资源文件
将运行作业所需要的资源复制到HDFS上,存放到JobTracker为该作业创建的一个以Job ID命名的文件夹中
包括MapReduce程序打包的JAR文件,配置文件和客户端计算所得的输入分片信息。
4.客户端提交作业,JobTracker接收到作业请求
5.作业初始化,创建作业对象
当jobTracker接收到Client提交的submitJob()方法之后,会将这个调用放到一个内部序列中
等待作业调度器进行调度,并对其初始化
初始化包括一个表示正在运行的作业的对象,用来封装任务和记录信息,以便跟踪任务的转台和进程。
6.获取输入分片数
为了创建任务列表,JobTracker需要从HDFS文件系统中获取已经计算好的输入分片
当作业调度器根据自己的调度算法调度到该作业时,会根据输入分片信息为每个分片创建一个map任务
并将map任务分配给TaskTracker执行(reduce的个数是通过mapred.reduce.tasks属性决定)
7.心跳HeartBeat
TaskTracker通过运行一个简单的循环来定期向JobTracker发送心跳信息(心跳间隔是5秒)
告知JobTracker节点是否存活,并且通过心跳机制,来充当二者之间的信息通道
8. 获取作业资源文件
TaskTracker开始运行作业任务,首先从HDFS中将Jar包复制到本地文件系统来进行计算,从而达到本地化
在本地为这个任务创建一个工作目录并把jar解压在此处,然后创建一个TaskRunner来运行该任务
对于map和reduce任务,TaskTracker根据CPU内核的数量和内存的大小有固定数量的map槽和reduce槽
数据本地化:
将map任务分配给含有该map处理的数据块的TaskTracker上,同时将程序JAR包复制到该TaskTracker上来运行
而分配reduce任务时并不考虑数据本地化。
9、TaskRunner启动一个JVM来运行每个任务(图中10步骤)
以便map任务和reduce任务出现任何问题,都不会影响到tasktracker,但是可以重用JVM。
10.当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成“成功”
当JobClient查询状态时,它将得知任务已完成,便显示一条消息给用户yarn的引入
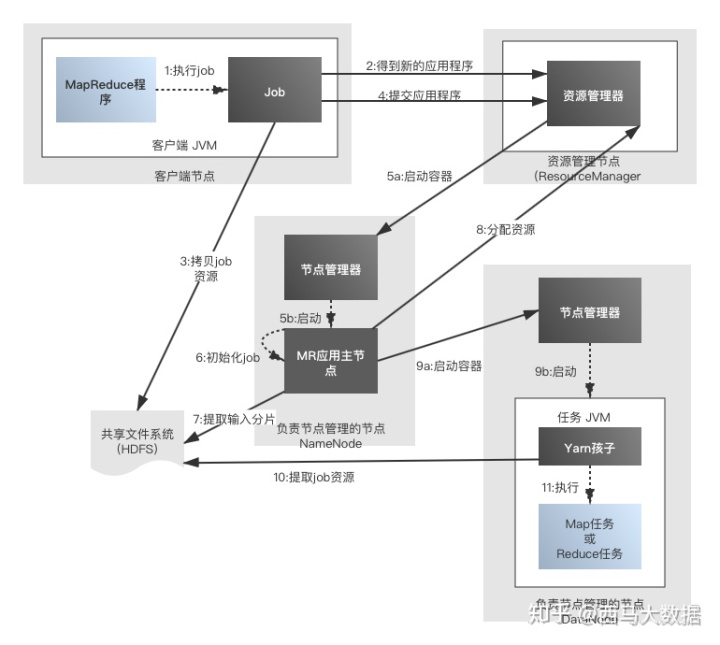
- 1.通过submit或者waitForCompletion提交作业,waitForCompletion()方法通过每秒循环轮转作业进度 如果发现与上次报告有改变,则将进度报告发送到控制台
- 2.向ResourceManager申请Application ID,RM检查输入输出说明、计算输入分片
- 3.复制作业的资源文件,将作业信息(jar、配置文件、分片信息)复制到HDFS上用户的应用缓存目录中
- 4.通过submitApplication()方法提交作业到资源管理器
- 5.资源管理器在收到submitApplication()消息后,将请求传递给调度器(Scheduler) 调度器为其分配一个容器Container,然后RM在NM的管理下在container中启动程序的ApplicationMaster进程
- 6.ApplicationMaster对作业进行初始化,创建过个薄记对象以跟踪作业进度 是一个java应用程序,他的主类是MRAppmaster
- 7.ApplicationMaster接受来自HDFS在客户端计算的输入分片 对每一个分片创建一个map任务,任务对象,由mapreduce.job.reduces属性设置reduce个数
- (uber模式):当任务小的时候就会启动一个JVM运行MapReduce作业,这在MapReduce1中是不允许的
- 这样的作业在YARN中成为uber作业,通过设置mapreduce.job.ubertask.enable设置为false使用
- 那什么是小任务呢?当小于10个mapper且只有1个reducer且输入大小小于一个HDFS块的任务
- 8.如果作业不适合uber任务运行,ApplicationMaster就会为所有的map任务和reduce任务向资源管理器申请容器 请求为任务指定内存需求,map任务和reduce任务的默认都会申请1024MB的内存
- 9.资源管理器为任务分配了容器,ApplicationMaster就通过节点管理器启动容器。
- 该任务由主类YarnChild的java应用程序执行。
- 10.运行任务之前,首先将资源本地化,包括作业配置、jar文件和所有来自分布式缓存的文件
- 11.最后执行map任务和reduce任务
MapReduceJob 分为map端和reduce端。
下面通过一段简单的MapReduce代码来分析
Map端
import Reduce 端
import App端
import 这其中发生了什么奇妙的过程呢,看如下两种图:
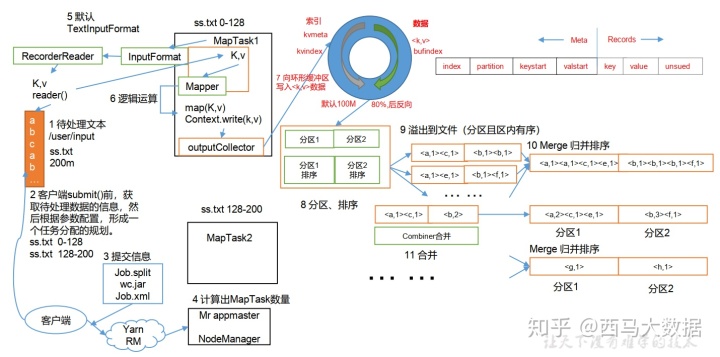
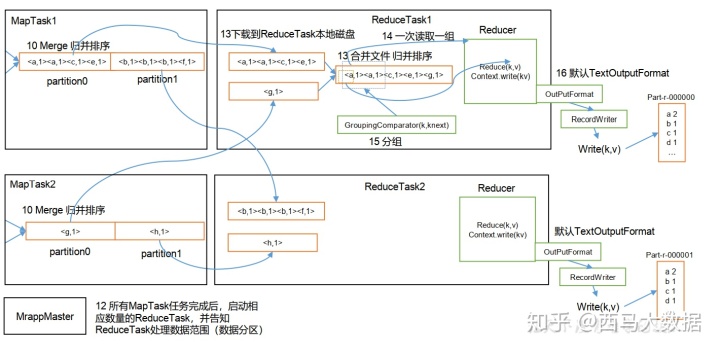
首先这其中发生了几次排序呢
总共可能发生 4 次排序过程:
1) Map 阶段:
- 环形缓冲区:对 key 按照字典排序。排序手段:快速排序
- 溢写到磁盘中:对多个溢写的文件进行排序。 排序手段:分区归并排序
2) Reduce 阶段:
- 按指定分区读取到 reduce 缓存中(不够落盘): 归并排序
- Reduce task 前分组排序: 自定义
shuffle过程
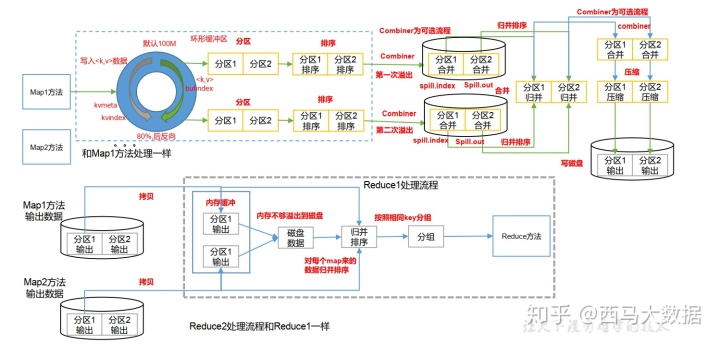
1) 环形缓冲区:
排序方式:快排+字典序
默认溢写阈值: 80%
默认大小: 100M
提示:合理的调节环形缓冲区大小以及溢写阈值是一种常见的 MR 优化手段哦
2) 切片机制:
a) 简单地按照文件的内容长度进行切片
b) 切片大小,默认等于 Block 大小
c) 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
提示:切片大小公式: max(0,min(Long_max,blockSize))
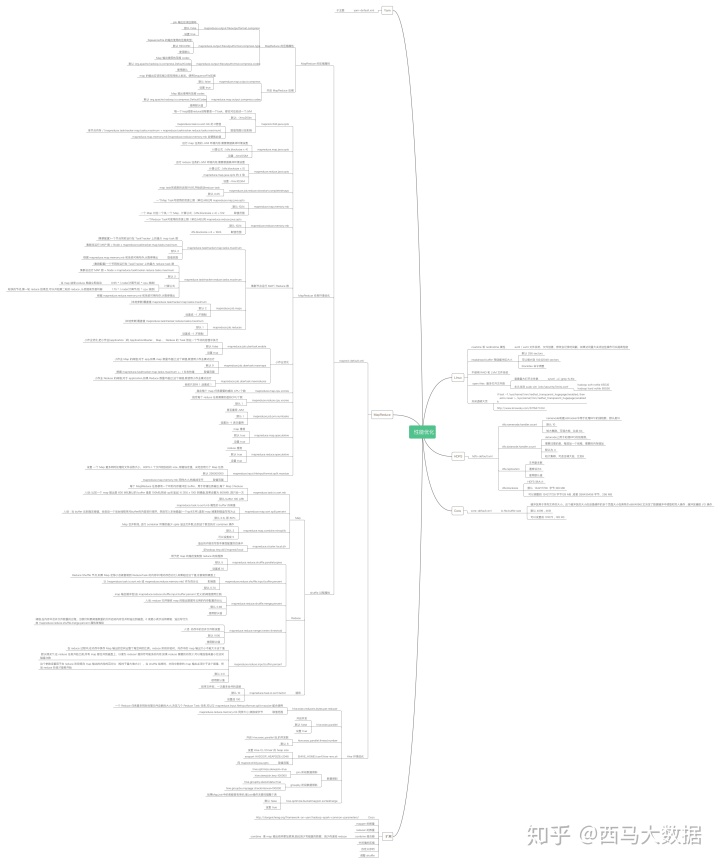
最后分享一个hadoop组件性能优化导向图
(有意向私聊给原件)
参考文章:https://blog.csdn.net/lb812913059/article/details/79897863
共勉。。。。。。














 2515
2515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









