





概述
Text file input(文本文件输入)步骤从各种文本文件类型读取数据,包括由电子表格和固定宽度的平面文件生成的格式。该步骤的特性允许您从文件或目录列表中读取,使用正则表达式形式的通配符,并接受前面步骤中生成的文件名。
选项
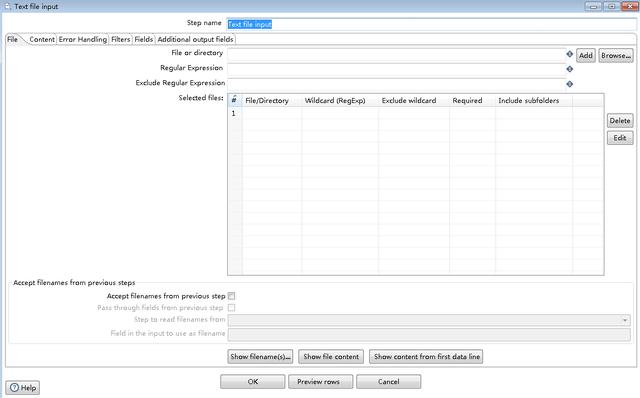
文本文件输入
Text file input(文本文件输入)步骤有以下选项:
Step name(步骤名称):在画布上指定Text file input(文本文件输入)步骤的唯一名称。您可以自定义名称或将其保留为默认名称。
- 文件选项卡包含如下选项
File or directory(文件或目录):如果未在字段中定义源,请指定源位置。单击浏览(B)...以显示打开的文件窗口并导航到文件或文件夹。有关支持的文件类型,请参阅连接到虚拟文件系统(https://help.pentaho.com/Documentation/9.1/Products/Connecting_to_Virtual_File_Systems)。点击增加以将源包含在选中的文件列表中。如果源位置是在字段中定义的,请使用从以前的步骤接受文件名来指定文件名。
Regular expression(正则表达式):指定一个正则表达式来匹配指定目录中的文件名。
Exclude Regular Expression(正则表达式(排除)):指定一个正则表达式以排除指定目录中的文件名。
正则表达式
使用文件选项卡中的通配符(正则表达式)字段以通配符的形式搜索正则表达式中的文件。正则表达式比使用*和?通配符更复杂。下面描述了几个正则表达式示例。
1.示例一
文件或目录:/dirA/
正则表达式:.userdata..txt
选中的文件:在/dirA/中查找名称包含userdata并以.txt结尾的所有文件。
2.示例二
文件或目录:/dirB/
正则表达式:AAA.*
选中的文件:在/dirB/中查找名称以AAA开头的所有文件。
3.示例三
文件或目录:/dirC/
正则表达式:[ENG:A-Z][ENG:0-9].*
选中的文件:在/dirC/中查找名称以大写开头后跟数字(A0-Z9)的所有文件。
Selected Files(选中的文件)列表中列信息介绍
所选中的文件列表显示用作输入源位置的文件或目录。在指定文件或目录后,单击增加填充此表。当单击增加将指定的文件或目录添加到列表中时,输入步骤尝试连接到该文件或目录。
File/Directory(文件/目录):在文件或目录中指定源文件后单击增加所指示的源位置。
Wildcard (RegExp)(通配符号):指定一个正则表达式来匹配指定目录中的文件名。
Exclude wildcard(通配符号(排除)):指定一个正则表达式以排除指定目录中的文件名。
Required(要求):输入所需的源位置。
Include subfolders(包含子目录):源位置中是否包含子文件夹。
单击删除从表中删除源。单击编辑从表中删除一个源,并将其返回到文件或目录选项。
从上一步获取文件名包含的选项信息
您可以指定文件名并将其传递给输入步骤,该步骤允许文件名来自任何源,比如文本文件或数据库表。
Accept filenames from previous step(从以前的步骤接受文件名):选择此选项可从前面的步骤中获取文件名。
Pass through fields from previous step(从以前的步骤接受字段名):选择从前面的步骤中获取字段信息。
Step to read file names from(步骤读取的文件名来自):输入要从中读取文件名的步骤的名称。
Field in the input to use as filename(在输入里的字段被当作文件名):输入要从中读取文件名的步骤的名称。
操作按钮
在文件选项卡字段中输入信息后,如果想查看源文件名或数据内容,请选择一个操作按钮。
Show filename(s)(显示文件名...):选择此选项以显示连接到该步骤的源的文件名。
Show file content(显示文件内容):选择显示所选文件的原始内容。
Show content from first data line(显示来自第一条数据行的内容):选择以显示所选文件的第一个数据行中的内容。
- 内容选项卡包含如下选项
在内容选项卡中,可以使用以下选项指定源文件的格式。
Filetype(文件类型):选择CSV或固定长度。根据所选择的文件类型,在字段选项卡中单击获取字段时将出现相应的界面。
Separator(分隔符):指定用于在一行文本中分隔字段的字符,通常是分号或制表符。单击Insert Tab将制表符放置在分隔符字段中。默认值是分号(;)。
Enclosure(文本限定符):指定一个可选字符,用于括起字段(如果字段包含分隔符)。默认值是双引号(")。
Escape(逃逸字符):指定一个或多个字符,以指示另一个字符是否为常规文本的一部分。例如,如果反斜杠()是转义字符,单引号(')是分隔符,那么文本Not the nine o’clock news将被解析为Not the nine o’clock news。
Header(头部):选择文本文件是否有标题行(文件中的第一行)。您可以使用头部行数量来指定标题行出现的次数。
Footer(尾部):选择文本文件是否有页脚行(文件中的最后一行)。可以使用尾部行数量来指定页脚行出现的次数。
Wrapped lines(包装行):选择是否处理已超出特定页限制的数据行。可以使用以时间包装的行数来指定换行的次数。
Paged layout (printout)(分页布局):在设计输出到行式打印机的文本文件上的其他文本处理选项(上面)失败时选择。您可以使用文档头部行来跳过介绍性文本,并使用每页记录行数来定位数据行。
Compression(压缩):选择您的文本文件是ZIP或GZip归档文件。只读取存档中的第一个文件。
No empty rows(没有空行):选择是否不想将空行发送到后续步骤。
Include filename in output(在输出包含字段名):选择是否希望文件名作为输出的一部分,并使用包含文件名的字段名称输入包含文件名的字段的名称。
Rownum in output?(输出包含行数?):选择是否希望行号作为输出的一部分。可以使用行数字段名称输入包含行号的字段的名称。如果希望允许每个文件重置行号,请选择按文件取行号。
Format(格式):选择文件格式,可以是DOS、UNIX或mixed。UNIX文件有以换行符结束的行。DOS文件用回车符和换行符分隔行。如果指定mixed,则不执行验证。
Encoding(编码格式):选择要使用的文本文件编码。如果留空以使用系统上的默认编码。要使用Unicode,请指定UTF-8或UTF-16。第一次使用时,PDI客户端会在系统中搜索可用的编码。
Length(长度):根据字段类型选择字段的长度。可以选择的值:Characters或Bytes。
Limit(记录数量限制):指定此步骤生成的记录数量的限制。不限制数量的记录指定为0。
Be lenient when parsing dates?(解析日期的时候是否严格要求?):如果需要对数据字段进行严格解析,请清除该复选框。如果被选中,像1月32日这样的日期就变成了2月1日。
The date format Locale(本地日期格式):指定要用于解析完整编写的日期的语言环境,例如2006年2月2日。例如,在设置为French (fr_FR)的系统上解析2006年2月2日将无法工作,因为February在该语言环境中称为Février。
Add filenames to result(添加文件名):选择将文件名添加到生成的文件名列表中。
- 错误处理选项卡包含如下选项
在错误处理选项卡中,您可以指定步骤在发生错误时的反应,例如格式错误的记录、错误的附件字符串、错误的字段数量和过早的行结束。
Ignore errors?(忽略错误?):选择是否希望在解析期间忽略错误。
Skip error files?(忽略错误文件?):选择是否要跳过包含错误的文件。您可以生成一个文件,其中包含发生错误的文件列表。否则,不跳过有错误的文件,并且解析错误的文件为空(null)。
Error file field name(错误文件字段名):如果要添加发生错误的字段名,请指定错误文件名。
File error message field name(文件错误信息字段名):如果要在错误文件中发生错误的地方添加字段名,请指定错误消息字段名。
Skip error lines?(跳过错误行?):选择是否要跳过包含错误的行。您可以生成一个额外的文件,其中包含发生错误的行号。否则,不会跳过有错误的行,并且解析错误的字段为空(null)。
Error count fieldname(错误计数字段):如果要将包含该行错误数量的字段添加到输出行,请指定字段名称。
Error fields fieldname(错误字段文件名):如果要添加一个字段,其中包含在输出行中发生错误的字段的名称,请指定字段名称。
Error text fieldname(错误文本字段):如果要向输出行添加包含解析错误发生描述的字段,请指定字段名称。
Warning files directory(警告文件目录):指定生成警告时放置警告的目录位置。结果文件的名称为/filename..。
Error files directory(错误文件目录):指定发生错误时放置错误的目录位置。结果文件的名称为/filename..。
Failing line numbers files directory(失败行数文件目录):指定在出现解析错误时所在的目录位置。结果文件的名称为/filename..。
- 过滤选项卡包含如下选项
过滤选项卡包含一个带有列的列表,您可以在其中指定要在文本文件中跳过的行。
Filter string(过滤字符串):您想要搜索的字符串。
Filter position(过滤器位置):在该行中必须放置过滤器字符串的位置。
Stop on filter(停止在过滤器):如果您想在遇到过滤器字符串时停止处理当前文本文件,请输入Y。在遇到字符串后,输入N继续处理。
Positive match(积极匹配):如果您想处理与筛选器字符串匹配的行,请输入Y。输入N来忽略匹配的行。
- 字段选项卡包含如下选项
在字段选项卡中,可以指定从文本文件中读取的字段的名称和格式。
Name(名称):字段的名称。
Type(类型):字段的类型可以是字符串、日期或数字。
Format(格式):有关格式符号的完整描述,请参阅数字格式(https://help.pentaho.com/Documentation/9.1/Products/Using_the_Hadoop_File_Input_step_on_the_Pentaho_engine#r_pentaho_number_formats_pdi_step_reuse)。
Position(位置):处理固定文件类型时需要的位置。它是从零开始的,所以第一个字符从0开始。
Length(长度):这个字段的值取决于格式:Number:一个数字中有效数字的总数;String:字符串的总长度;Date:字符串打印输出的总长度。例如,4只返回年份。
Precision(精度):用于数字类型字段的浮点数。
Currency(货币类型):货币符号(例如$或€)。
Decimal(小数):小数点可以是.(例如5,000.00)或,(例如5.000,00)。
Group(分组):分组可以是,(例如10,000.00)或.(例如5.000,00)。
Null if:将此值视为空值。
Default(默认):未指定文本文件中的字段时的默认值(空)。
Trim type(去除空字符串方式):应用于字符串的修剪方法。
Repeat(重复):如果该行中对应的值为空,则重复上次非空时的值(Y或N)。
数字格式
- 符号:0 位置:数字类型 本地化:Yes 意义:数字。
- 符号:# 位置:数字类型 本地化:Yes 意义:数字,零表示不存在。
- 符号:. 位置:数字类型 本地化:Yes 意义:十进制分隔符或货币十进制分隔符。
- 符号:- 位置:数字类型 本地化:Yes 意义:负号。
- 符号:, 位置:数字类型 本地化:Yes 意义:分组分隔符。
- 符号:E 位置:数字类型 本地化:Yes 意义:在科学记数法中分离尾数和指数。无需在前缀或后缀中引用。
- 符号:; 位置:子模式边界 本地化:Yes 意义:区分积极和消极模式。
- 符号:% 位置:前缀或后缀 本地化:Yes 意义:乘以100并显示为百分比。
- 符号:‰(/u2030) 位置:前缀或后缀 本地化:Yes 意义:乘以1000,表示为每千分之一。
- 符号:¤(/u00A4) 位置:前缀或后缀 本地化:No 意义:货币符号,由货币符号代替。如果加倍,就会被国际货币符号取代。如果在模式中出现,则使用货币小数分隔符而不是小数分隔符。
- 符号:‘ 位置:前缀或后缀 本地化:No 意义:用于在前缀或后缀中引用特殊字符,例如,'#'#格式为123到#123。为了创建单引号本身,请连续使用两个:# o”clock。
科学记数法
在模式中,紧跟着一个或多个数字字符的指数字符表示科学符号,例如0.###E0将数字1234格式化为1.234E3。
日期格式
- 字母:G 日期或时间元素:纪元标志符 表示:文本 示例:公元后
- 字母:y 日期或时间元素:年 表示:年份 示例:1996或96
- 字母:M 日期或时间元素:年中的月份 表示:月份 示例:July, Jul或07
- 字母:w 日期或时间元素:年中的周数 表示:数字类型 示例:27
- 字母:W 日期或时间元素:月份中的周数 表示:数字类型 示例:2
- 字母:D 日期或时间元素:年中的天数 表示:数字类型 示例:189
- 字母:d 日期或时间元素:月份中的天数 表示:数字类型 示例:10
- 字母:F 日期或时间元素:月份中的星期 表示:数字类型 示例:2
- 字母:E 日期或时间元素:星期中的天数 表示:数字类型 示例:Tuesday 或 Tue
- 字母:a 日期或时间元素:Am/pm 标记 表示:文本 示例:PM
- 字母:H 日期或时间元素:一天中的小时数(0-23) 表示:数字类型 示例:0
- 字母:k 日期或时间元素: 一天中的小时数(1-24) 表示:数字类型 示例:24
- 字母:K 日期或时间元素:am/pm 中的小时数(0-11) 表示:数字类型 示例:0
- 字母:h 日期或时间元素: am/pm 中的小时数(1-12) 表示:数字类型 示例:12
- 字母:m 日期或时间元素: 小时中的分钟数 表示:数字类型 示例:30
- 字母:s 日期或时间元素:分钟中的秒数 表示:数字类型 示例:55
- 字母:S 日期或时间元素: 毫秒数 表示:数字类型 示例:978
- 字母:z 日期或时间元素:时区 表示:通用时区 示例:Pacific Standard Time, PST 或者 GMT-08:00
- 字母:Z 日期或时间元素:时区 表示:RFC 822时区 示例:-0800
- 其他输出字段选项卡包含如下选项
Short filename field(文件名字段):指定包含不带路径信息但带扩展名的文件名的字段。
Extension field(扩展名字段):指定包含文件名扩展名的字段。
Path field(路径字段):以操作系统格式指定包含路径的字段。
Size field(文件大小字段):指定包含数据大小的字段。
Is hidden field(是否为隐藏文件字段):指定文件是否隐藏的字段(布尔值)。
Last modification field(最后修改时间字段):指定表示文件最后一次修改日期的字段。
Uri field(Uri字段):指定包含URI的字段。
Root uri field(Root uri字段):指定只包含URI根部分的字段。
元数据注入支持
此步骤的所有字段都支持元数据注入。您可以将此步骤与ETL元数据注入一起使用,以便在运行时将元数据传递给您的转换。
示例
双击输入中的文件输入,添加一个文件输入。
文件输入
然后双击添加的步骤进行编辑。
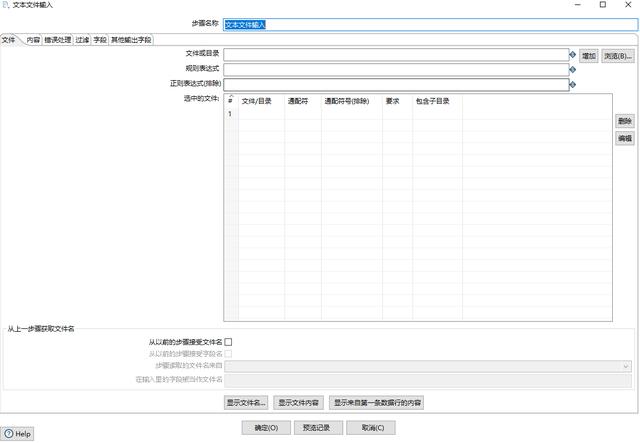
点击浏览(B),选择一个文件/data-integration/samples/transformations/files/sales_data.csv。然后点击增加。
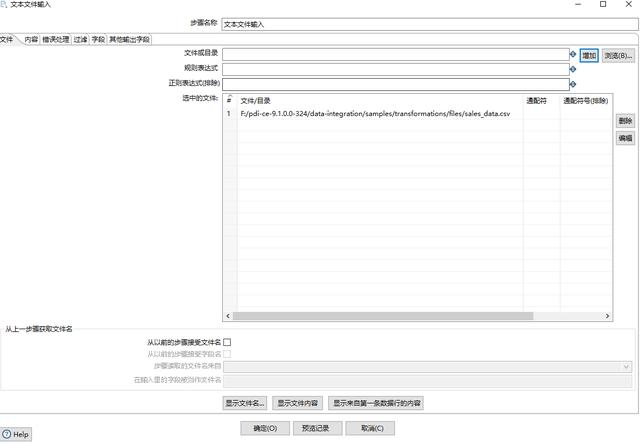
添加文件
切换内容选项卡,设置分隔符为,,格式为Unix。
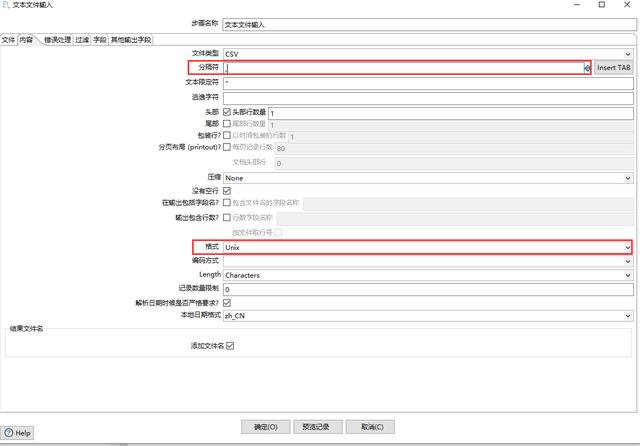
设置内容
然后切换至字段选项卡,点击获取字段。
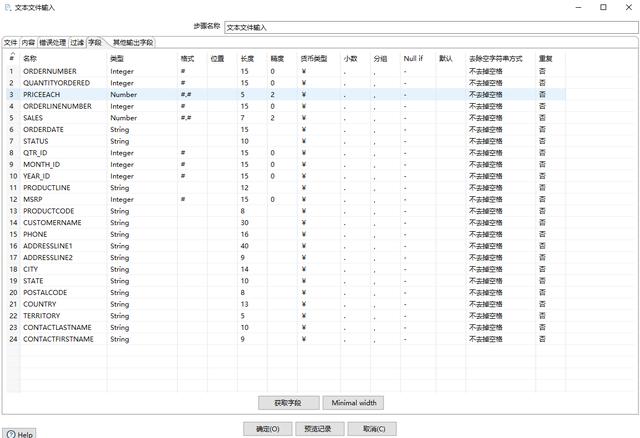
获取字段
然后点击预览记录,预览选择表的数据列表。
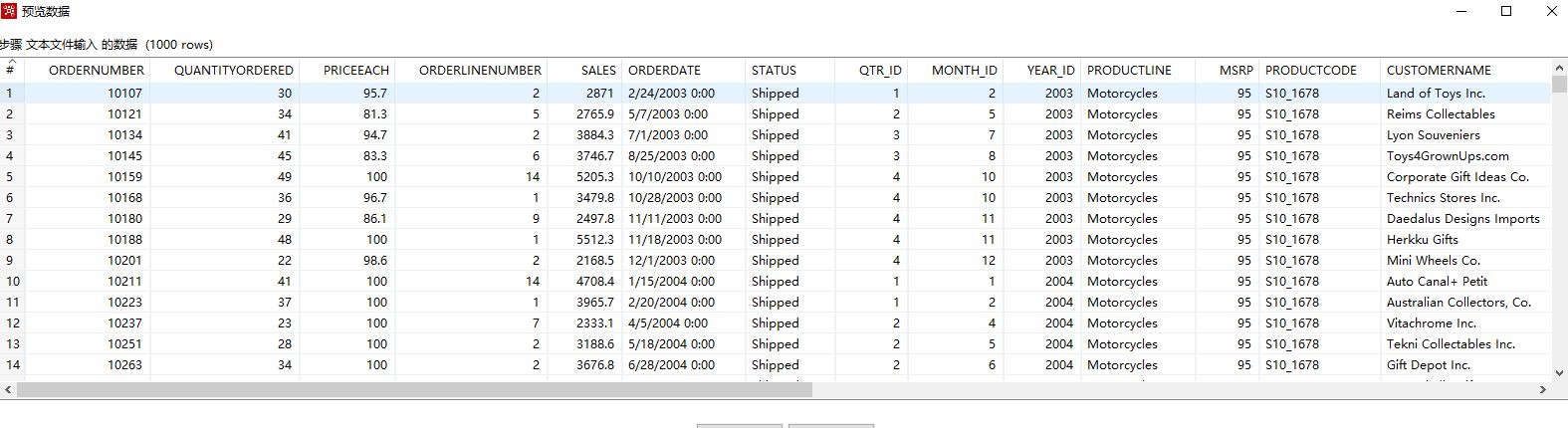















 5023
5023











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









