






点击上方 蓝字 关注我们


在整个数据的传输的过程中,流动的是event,它是Flume内部数据传输的最基本单元。event将传输的数据进行封装。如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去
一个完整的event包括:event headers、event body、event信息,其中event信息就是flume收集到的日记记录。
tar -zxf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C ../servers/
【3】配置环境变量(可选操作)
1.vim /etc/profile.d/flume.sh
2.根据自己安装的位置添加如下配置文件:
export FLUME_HOME=/export/servers/apache-flume-1.8.0-bin
export PATH=$PATH:$FLUME_HOME/bin
【4】配置JAVA_HOME
1.cd $FLUME_HOME/conf
2.cp flume-env.sh.template flume-env.sh
3.vim flume-env.sh
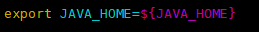
【5】配置日志目录(可选操作)
vim log4j.properties

【1】Flume监听端口号实现数据采集并打印在控制台
整体步骤:
1.在Flume根目录下创建文件夹 job 用来存放 Flume 配置文件
2.进入job目录下进行编写 Flume配置文件
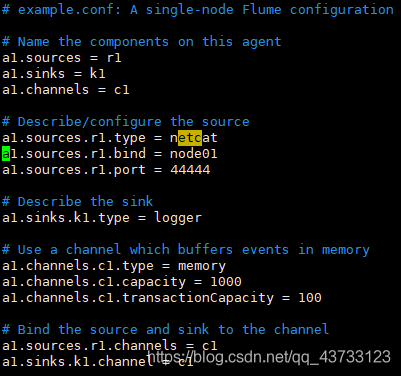
上述代码?
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = node01
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3.安装nc或telnet
yum -y install nc
yum -y install telnet
4.启动 flume 监听端口 44444
flume-ng agent -c conf/ -f job/netcat-flume-logger.conf -n a1 -Dflume.root.logger=INFO,console
参数说明:
-c 指定 flume 的 conf 配置文件
-f 后面指定此次 flume 配置文件路径
-n 后面指定 flume 配置文件中的别名
-Dflume.root.logger=INFO,console 将采集到的数据打印在控制台
5.启动nc/telnet 向 44444 端口 进行发送数据
nc node01 44444
telnet node01 44444
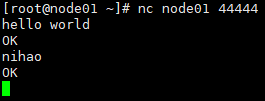
6.查看效果

【2】Flume监控文件夹并将数据上传到HDFS
整体步骤:
1.根据环境编写 flume配置文件
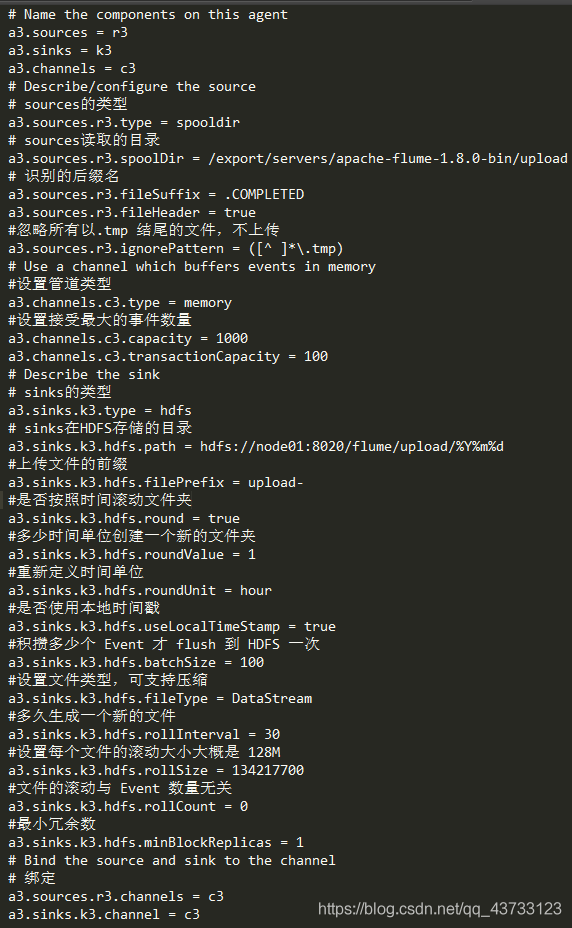
上述代码 ?
# Name the components on this agent
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
# sources的类型
##注意:不能往监控目中重复丢同名文件
a3.sources.r3.type = spooldir
# sources读取的目录
a3.sources.r3.spoolDir = /export/servers/apache-flume-1.8.0-bin/upload
# 识别的后缀名
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp 结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
# Use a channel which buffers events in memory
#设置管道类型
a3.channels.c3.type = memory
#设置接受最大的事件数量
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Describe the sink
# sinks的类型
a3.sinks.k3.type = hdfs
# sinks在HDFS存储的目录
a3.sinks.k3.hdfs.path = hdfs://node01:8020/flume/upload/%Y%m%d
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 30
#设置每个文件的滚动大小大概是 128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a3.sinks.k3.hdfs.rollCount = 0
#最小冗余数
a3.sinks.k3.hdfs.minBlockReplicas = 1
# Bind the source and sink to the channel
# 绑定
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
2.启动
flume-ng agent -c conf -f job/dir-flume-hdfs.conf -n a3
3.往指定的目录里写入数据

可以发现,我们指定的被监控文件夹里的文件追加了一个后缀名 COMPLETED
表示文件以及被Flume采集并上传到了HDFS指定的目录下
4.查看HDFS上的文件

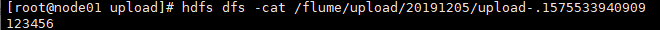
1.在使用Spooling Directory Source时,不要在监控目录中创建并持续修改文件
2.上传完成的文件会以.COMPLETED结尾
3.被监控文件夹每500毫秒扫描一次文件变动
4.如果在被监控文件夹内创建重名文件Flume进程就挂了,需要重新启动,切记不能重名
【3】Flume监控Hive日志并将数据上传到HDFS
整体步骤:
1.根据环境编写 flume配置文件
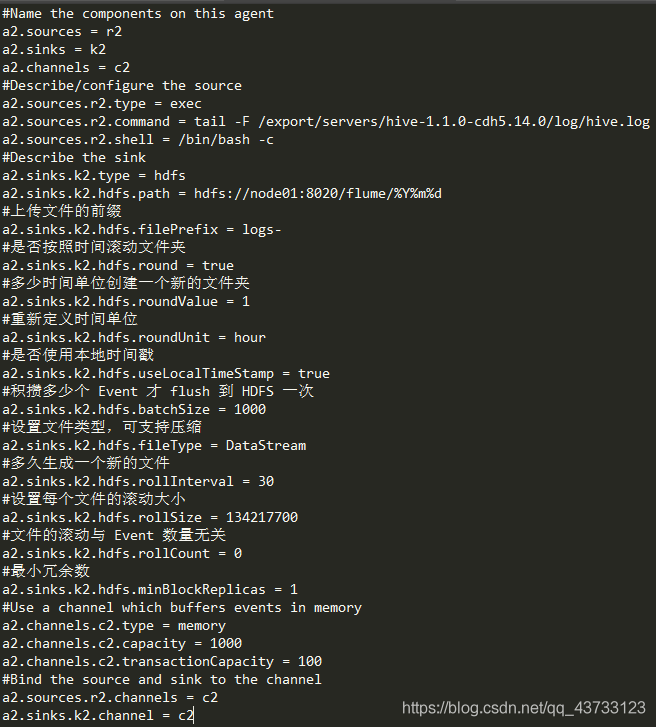
#Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
#Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /export/servers/hive-1.1.0-cdh5.14.0/log/hive.log
a2.sources.r2.shell = /bin/bash -c
#Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://node01:8020/flume/%Y%m%d
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a2.sinks.k2.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 30
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a2.sinks.k2.hdfs.rollCount = 0
#最小冗余数
a2.sinks.k2.hdfs.minBlockReplicas = 1
#Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
#Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
2.启动
flume-ng agent -c conf/ -f job/file-flume-hdfs.conf -n a2
【4】Flume监控Hive日志并将数据上传到HDFS(两个agent级联)
需求:在第一个节点采集数据,将数据发送至第二个节点,第二个节点将数据写入HDFS
整体步骤:
1.根据环境编写 flume配置文件
节点1如下配置?
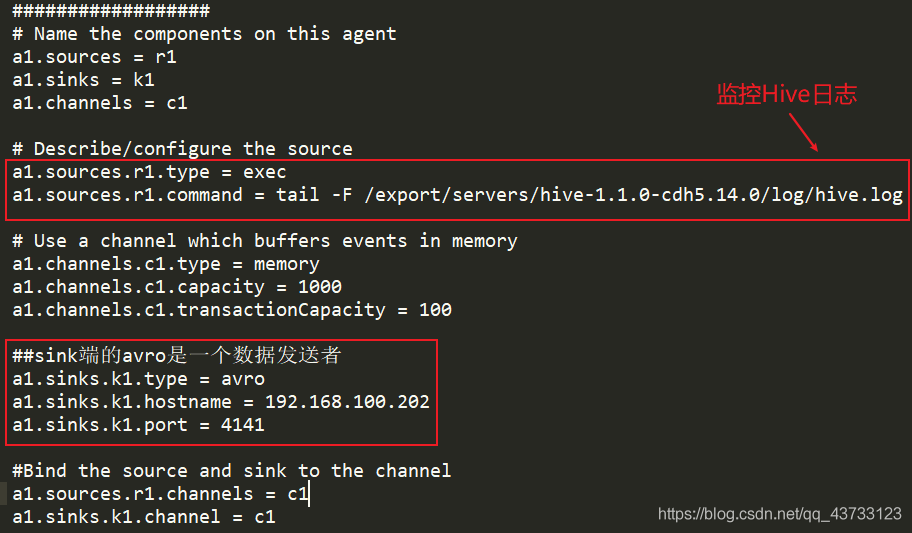
上述代码 ?
##################
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /export/servers/hive-1.1.0-cdh5.14.0/log/hive.log
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
##sink端的avro是一个数据发送者
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.100.202
a1.sinks.k1.port = 4141
#Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
节点2如下配置?
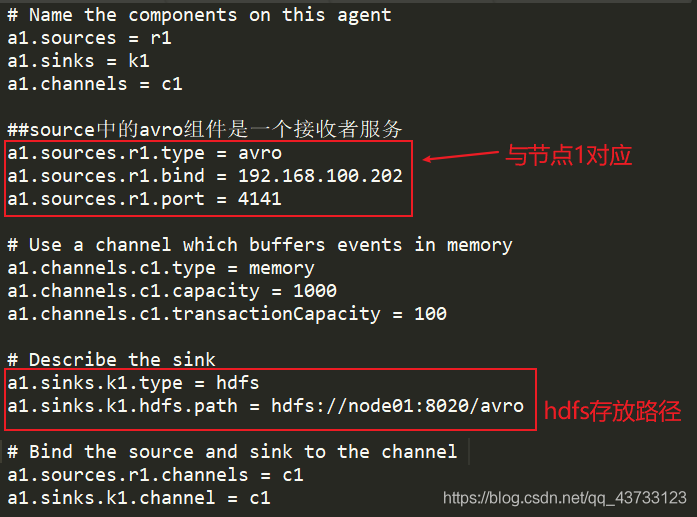
上述代码 ?
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
##source中的avro组件是一个接收者服务
a1.sources.r1.type = avro
a1.sources.r1.bind = 192.168.100.202
a1.sources.r1.port = 4141
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://node01:8020/avro
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2.启动
先在节点2根目录下启动:
flume-ng agent -c conf/ -f job/avro-flume-hdfs.conf -n a1
再先在节点1根目录下启动:
flume-ng agent -c conf/ -f job/file-flume-avro-avro-hdfs.conf -n a1
3.启动Hive产生日志文件

4.查看HDFS上产生的文件
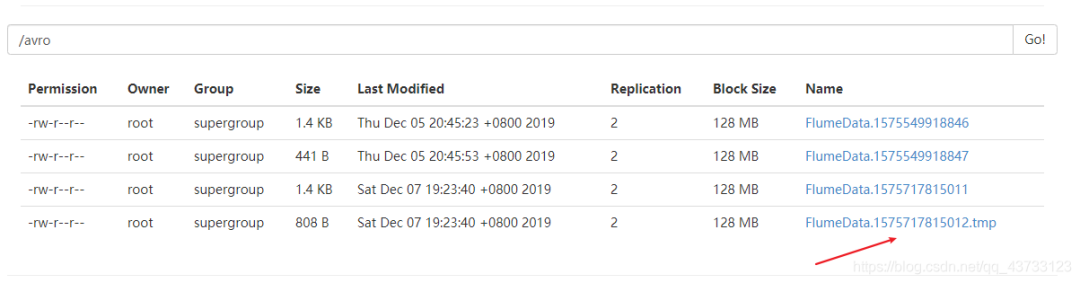
说明:
【1】Source
1)Taildir Source 和 Exec Source 如何选择?
Taildir Source 相比Exec Sgurce、Spooling Directory Source的优势TailDir Source:断点续传、多目录。Flumel.6以前需要自己自定义Source 记录每次读取文件位置,实现断点续传
Exec Source 可以实时搜集数据,但是在Flume不运行或者Shell命令出错的情况下,数据将会丢失
Spooling Directory Source监控目录,不支持断点续传
2)batchSize 大小如何设置?
Event1K左右时,500-1000合适(默认为100)
【2】Channel
采用Kafka Channel,省去了Sink,提高了效率
注意在Flume1.7以前,Kafka Channel很少有人使用,因为发现parseAsFlumeEvent这个配置起不了作用。也就是无论parseAsFlumeEvent 配置为true还是false,都会转为FlumeEvent。这样的话,造成的结果是,会始终都把Flume的headers中的信息混合着内容一起写入Kafka的消息中,这显然不是我所需要的,我只是需要把内容写入即可
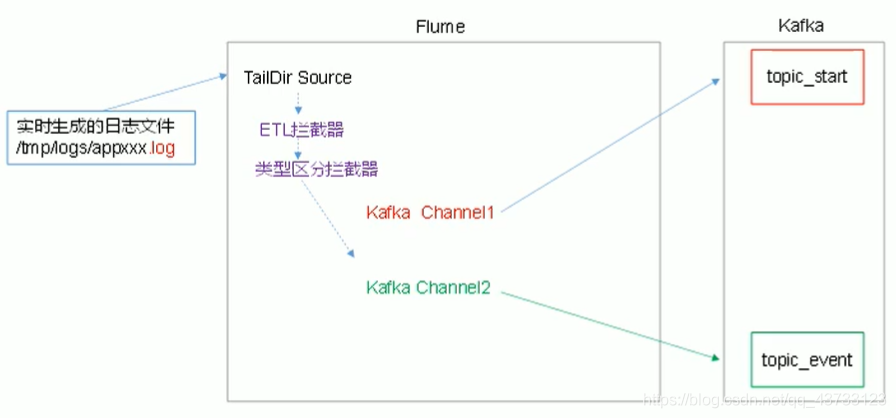
【3】架构图
【4】编辑Flume采集日志数据发送到Kafka配置文件(记得同步配置)
# 说明1:我们使用 TAILDIR Source 监控多目录,自动实现断点续传,版本需要在1.7+
# 说明2:我们使用 Kafka Channel,不使用Kafka Sink,提高效率
a1.sources=r1
a1.channels=c1 c2
# configure source
a1.sources.r1.type = TAILDIR
# 断点续传持久化目录
a1.sources.r1.positionFile = /opt/modules/flume/log_position/log_position.json
# 设置需要监控的多个目录,我们只需要一个,所以只添加一个 f1
a1.sources.r1.filegroups = f1
# 设置 f1 对应的监控目录
a1.sources.r1.filegroups.f1 = /opt/tmp/logs/app.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1 c2
# interceptor 添加拦截器
a1.sources.r1.interceptors = i1 i2
# 自定义拦截器
a1.sources.r1.interceptors.i1.type = com.zsy.flume.interceptor.LogETLInterceptor$Builder # ETL拦截器
a1.sources.r1.interceptors.i2.type = com.zsy.flume.interceptor.LogTypeInterceptor$Builder #日志类型拦截器
# 根据header头信息,将source数据发送到不同的 Channel
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = topic
a1.sources.r1.selector.mapping.topic_start = c1
a1.sources.r1.selector.mapping.topic_event = c2
# configure channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = node01:9092,node02:9092,node03:9092
a1.channels.c1.kafka.topic = topic_start # 日志类型是start,数据发往 channel1
a1.channels.c1.parseAsFlumeEvent = false
a1.channels.c1.kafka.consumer.group.id = flume-consumer
a1.channels.c2.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c2.kafka.bootstrap.servers = node01:9092,node02:9092,node03:9092
a1.channels.c2.kafka.topic = topic_event # 日志类型是event,数据发往 channel2
a1.channels.c2.parseAsFlumeEvent = false
a1.channels.c2.kafka.consumer.group.id = flume-consumer
【5】自定义拦截器
创建Maven项目,添加如下依赖:
org.apache.flume
flume-ng-core
1.7.0
maven-compiler-plugin
2.3.2
1.8
1.8
maven-assembly-plugin
jar-with-dependencies
make-assembly
package
single
自定义拦截器步骤:
① 定义一个类,实现Flume的Interceptor接口
② 重写4个方法
初始化
单Event处理
多Event处理
关闭资源
③ 创建静态内部类,返回当前类对象
④ 打包上传
代码如下
1)com.zsy.flume.interceptor.LogETLInterceptor
package com.zsy.flume.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
public class LogETLInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
// 清洗数据 ETL
// 1.获取日志
byte[] body = event.getBody();
String log = new String(body, Charset.forName("UTF-8"));
// 2.区分类型处理
if (log.contains("start")) {
// 验证启动日志逻辑
if (LogUtils.validateStart(log)) {
return event;
}
} else {
// 验证事件日志逻辑
if (LogUtils.validateEvent(log)) {
return event;
}
}
return null;
}
@Override
public List intercept(List events) {
ArrayList interceptors = new ArrayList<>();
// 多event处理
for (Event event : events) {
Event intercept = intercept(event);
if (intercept != null) {
interceptors.add(intercept);
}
}
return interceptors;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new LogETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
2)com.zsy.flume.interceptor.LogTypeInterceptor
package com.zsy.flume.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class LogTypeInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
// 区分类型 start event
// header body
byte[] body = event.getBody();
String log = new String(body, Charset.forName("UTF-8"));
// 获取头信息
Map headers = event.getHeaders();
// 业务逻辑判断
if(log.contains("start")){
headers.put("topic","topic_start");
}else{
headers.put("topic","topic_event");
}
return event;
}
@Override
public List intercept(List events) {
ArrayList interceptors = new ArrayList<>();
for (Event event : events) {
Event intercept = intercept(event);
interceptors.add(intercept);
}
return interceptors;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new LogTypeInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
3)工具类
package com.zsy.flume.interceptor;
import org.apache.commons.lang.math.NumberUtils;
public class LogUtils {
// 验证启动日志逻辑
public static boolean validateStart(String log) {
if (log == null) {
return false;
}
// 判断数据是否是 { 开头 ,是否是 } 结尾
if (!log.trim().startsWith("{") || !log.trim().endsWith("}")) {
return false;
}
return true;
}
// 验证事件日志逻辑
public static boolean validateEvent(String log) {
// 判断数据是否是 { 开头 ,是否是 } 结尾
// 服务器事件 | 日志内容
if (log == null) {
return false;
}
// 切割
String[] logContents = log.split("\\|");
if(logContents.length != 2){
return false;
}
// 校验服务器时间(长度必须是13位,必须全部是数字)
if(logContents[0].length() != 13 || !logContents[0].matches("[0-9]{13}")){
// if(logContents[0].length() != 13 || !NumberUtils.isDigits(logContents[0])){
return false;
}
// 校验日志格式
if (!logContents[1].trim().startsWith("{") || !logContents[1].trim().endsWith("}")) {
return false;
}
return true;
}
}
4)打包将不带依赖的jar包上传到 Flume的 lib 目录下即可,flume启动会自动加载 lib下的所有jar包
【6】Flume启动/停止脚本
#! /bin/bash
case $1 in
"start"){
for i in node01 node02
do
echo " --------启动 $i 采集 flume-------"
ssh $i "nohup /opt/modules/flume/bin/flume-ng agent --conf-file /opt/modules/flume/conf/file-flume-kafka.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/dev/null 2>&1 &"
done
};;
"stop"){
for i in node01 node02
do
echo " --------停止 $i 采集 flume-------"
ssh $i "ps -ef | grep file-flume-kafka | grep -v grep |awk '{print \$2}' | xargs kill"
done
};;
esac
说明1:nohub该命令表示在退出账户/关闭终端后继续运行相应的进程,意味不挂起,不挂断地运行命令
说明2:awk默认分隔符为空格
说明3:xargs 表示取出前面命令运行地结果,作为后面命令地输入参数
6)Kafka安装
【1】Kafka简介
Kafka是一个多分区、多副本,发布-订阅模式的,基于zookeeper协调的分布式流式处理平台
【2】消息队列
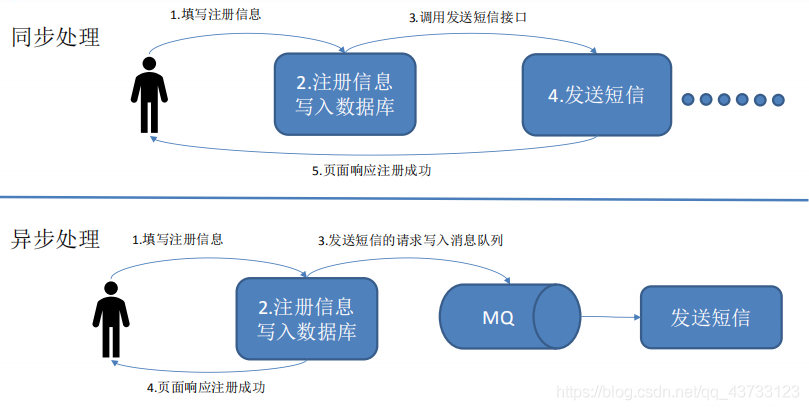
1)消息队列应用场景
2)消息队列模式
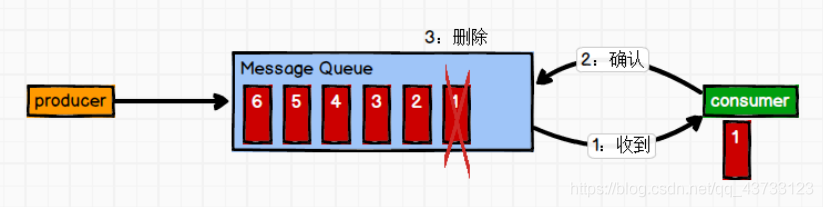
1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
消息生产者生产消息发送到Queue中,然后消息消费者从Queue中取出并且消费消息。消息被消费以后,queue 中不再有存储,所以消息消费者不可能消费到已经被消费的消息。Queue 支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费
2)发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
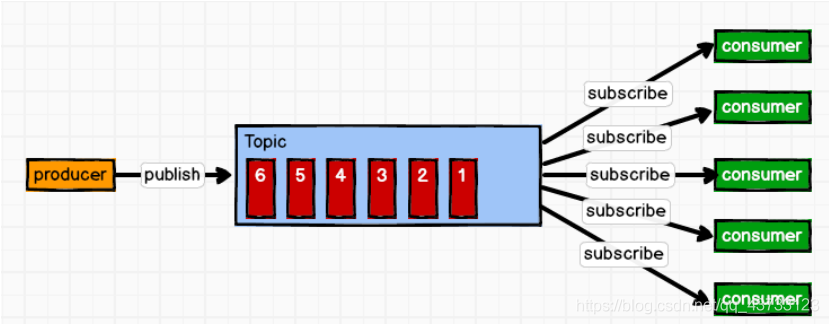
消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消
息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费
3)消息队列作用
1)解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束
2)可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所
以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理
3)缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致
的情况
4)灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。
如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃
5)异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户
把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们
【3】Kafka架构
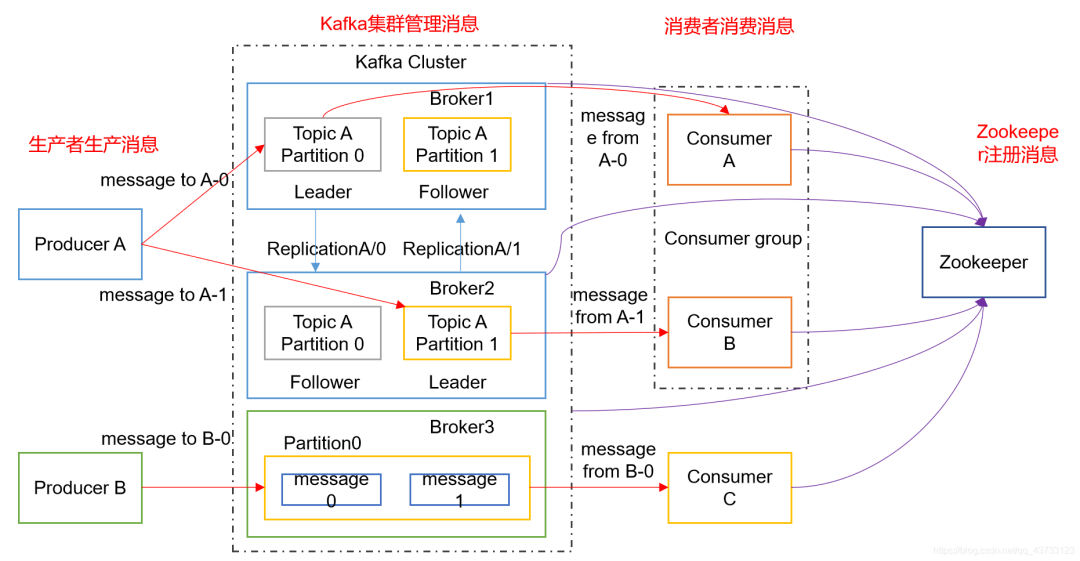
1)Producer :消息生产者,向 kafka broker 发送消息的客户端
2)Consumer :消息消费者,从 kafka broker 获取消息的客户端
3)Consumer Group (CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者
4)Broker :一个kafka服务器就是一个 broker,一个Kafka集群由多个 broker 组成,一个 broker可以有多个 topic
5)Topic :逻辑上存放消息的集合,生产者和消费者面向的都是一个 topic
6)Partition:一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列,一个topic的所有partition分布在不同的broker上
7)Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower
8)Leader:每个分区的主副本,生产者和消费者都只和Leader交互
9)Follower:每个分区的从副本,实时从 Leader中同步数据,保持和 Leader数据的同步。Leader发生故障时,选举ISR里的某个 Follower会成为新的 Follower
【1】 jar包下载
http://kafka.apache.org/downloads.html
【2】 解压安装包
tar -zxf kafka_2.11-0.11.0.0.tgz -C /opt/modules/
mv kafka_2.11-0.11.0.0/ kafka
【3】 创建logs、data目录
mkdir /opt/modules/kafka/data
mkdir /opt/modules/kafka/logs
【4】修改配置文件
vim /opt/modules/kafka/config/server.properties
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志存放的路径
log.dirs=/opt/modules/kafka/data
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接Zookeeper集群地址
zookeeper.connect=node01:2181,node01:2181,node01:2181
host.name=主机名
【5】分发配置文件
scp -r /opt/modules/kafka 用户名@主机名:/opt/modules
【6】Kafka重装
我们知道Kafka通过Zookeeper保存元数据,所以,当我们的Kafka出现故障,需要重装时,需要把Zookeeper中的元数据删除了,所以我大致总结了如下需要在Zookeeper中删除的元数据?
需要使用 bin/zkCli.sh 命令进入zookeeper,然后使用 rmr 命令删除以下内容即可
cluster:kafka集群信息
config:配置信息
consumer:消费者信息
producer:生产者信息
brokers :集群几点信息,topic信息
admin:删除的topic
controller:控制节点的broker.id
controller_epoch:集群经过了多少次controller选取
isr_change_notification : ISR集合改变的消息
latest_producer_id_block
【7】Kafka 压力测试
1)Kafka 压测
用 Kafka 官方自带的脚本,对 Kafka 进行压测。Kafka 压测时,可以查看到哪个地方出
现了瓶颈(CPU,内存,网络 IO),一般都是网络 IO 达到瓶颈
kafka-consumer-perf-test.sh
kafka-producer-perf-test.sh
1
2
2)Kafka Producer 压力测试
(1)在/opt/module/kafka/bin 目录下面有这两个文件,我们来测试一下
bin/kafka-producer-perf-test.sh --topic test
--record-size 100
--num-records 100000
--throughput -1
--producer-props
bootstrap.servers=node01:9092,node01:9092,node01:9092
参数说明:
record-size 是一条信息有多大,单位是字节
num-records 是总共发送多少条信息
throughput 是每秒多少条信息,设成 -1,表示不限流,可测出生产者最大吞吐量
(2)Kafka 会打印下面的信息
100000 records sent, 95877.277085 records/sec (9.14 MB/sec),
187.68 ms avg latency, 424.00 ms max latency, 155 ms 50th, 411 ms
95th, 423 ms 99th, 424 ms 99.9th.
参数解析:本例中一共写入 10w 条消息,吞吐量为 9.14 MB/sec,每次写入的平均延迟
为 187.68 毫秒,最大的延迟为 424.00 毫秒
3)Kafka Consumer 压力测试
Consumer 的测试,如果这四个指标(IO,CPU,内存,网络)都不能改变,考虑增加分区数来提升性能
bin/kafka-consumer-perf-test.sh --zookeeper hadoop102:2181
--topic test --fetch-size 10000 --messages 10000000 --threads 1
参数说明:
--zookeeper 指定 zookeeper 的连接信息
--topic 指定 topic 的名称
--fetch-size 指定每次 fetch 的数据的大小
--messages 总共要消费的消息个数
测试结果说明:
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec
2019-02-19 20:29:07:566, 2019-02-19 20:29:12:170, 9.5368, 2.0714, 100010, 21722.4153
开始测试时间,测试结束数据,共消费数据 9.5368MB,吞吐量 2.0714MB/s,共消费
100010 条,平均每秒消费 21722.4153 条
【8】Kafka 机器数量计算
Kafka 机器数量(经验公式)=2*(峰值生产速度*副本数/100)+1
1
先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署 Kafka 的数量
比如我们的峰值生产速度是 50M/s,副本数为 2
Kafka 机器数量=2*(50*2/100)+ 1=3 台
1)查看当前服务器中的所有topic
bin/kafka-topics.sh --zookeeper 主机名:2181 --list
2)创建topic
bin/kafka-topics.sh --zookeeper 主机名:2181 --create --replication-factor 3 --partitions 1 --topic 主题名
选项说明:
--topic 定义topic名
--replication-factor 定义副本数
--partitions 定义分区数
3)删除topic
bin/kafka-topics.sh --zookeeper 主机名:2181 --delete --topic 主题名
注:需要server.properties中设置delete.topic.enable=true否则只是标记删除或者直接重启
4)发送消息
bin/kafka-console-producer.sh --broker-list 主机名:9092 --topic 主题名
5)消费消息
bin/kafka-console-consumer.sh --bootstrap-server 主机名:9092 --from-beginning --主题名first
选项说明:
--from-beginning:会把first主题中以往所有的数据都读取出来。根据业务场景选择是否增加该配置
6)查看某个Topic的详情
bin/kafka-topics.sh --zookeeper 主机名:2181 --describe --topic 主题名
7)日志生成
前提:将我们之前写好的日志数据生成代码打包放到服务器上
日志启动
【1】代码参数说明
// 参数一:控制发送每条的延时时间,默认是 0
Long delay = args.length > 0 ? Long.parseLong(args[0]) : 0L;
// 参数二:循环遍历次数
int loop_len = args.length > 1 ? Integer.parseInt(args[1]) : 1000;
【2】 将 生 成 的 jar 包 log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar 拷 贝 到
node01 服务器 /opt 目录下,并同步到 node02
【3】在 node01 上执行 jar 程序
方式1:
java -classpath log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar com.zsy.appclient.AppMain > /dev/null 2>&1
说明:
如果打包时没有指定主函数,则使用 -classpath,并在 jar 包后面指定主函数全类名
方式2:
java -jar log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar > /dev/null 2>&1
说明:
如果打包时指定了主函数,则可以使用 -jar ,此时不用指定主函数的全类名
说明:/dev/null 代表 linux 的空设备文件,所有往这个文件里面写入的内容都会丢失,俗称“黑洞”
标准输入 0:从键盘获得输入 /proc/self/fd/0
标准输出 1:输出到屏幕(即控制台) /proc/self/fd/1
错误输出 2:输出到屏幕(即控制台) /proc/self/fd/2
【4】查看日志数据,在我们指定好的目录/opt/tmp/logs目录下查看数据
【5】脚本
我们为了方便使用,就通过脚本来实现数据的生成!
日志数据生成脚本如下
#! /bin/bash
for i in node01 node02
do
echo "========== $i 生成日志数据中... =========="
ssh $i "java -jar /opt/log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar $1 $2 >/dev/null 2>&1 &"
done
时间同步脚本(临时脚本,只是后续为了时间同步而需要的)如下
#!/bin/bash
for i in node01 node02 node03
do
echo "========== $i =========="
ssh -t $i "sudo date -s $1"
done
参数说明:
我们可以发现上面的参数中我们使用了 -t ,是因为我们使用了 sudo ,所以需要使用 -t 参数来形成虚拟终端,不需要深究,只要使用 sudo,在ssh后面添加 -t 接口
8)Flume消费Kafka数据存储在HDFS
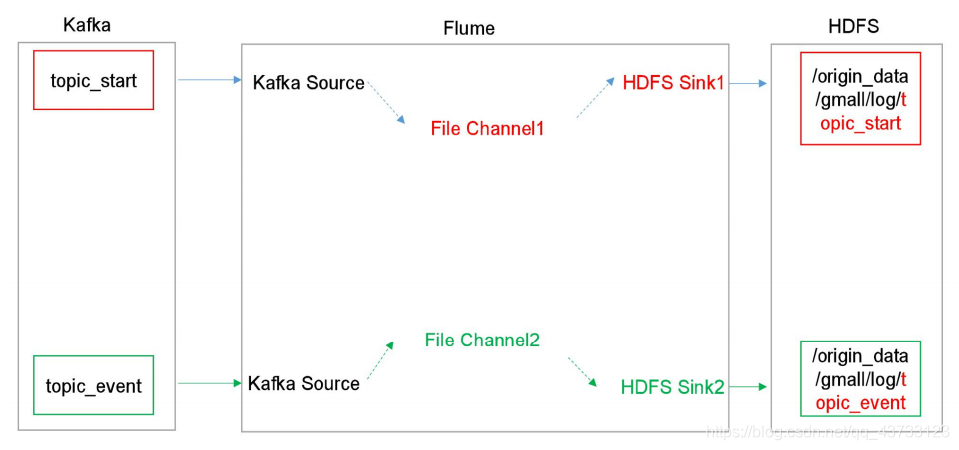
【1】我们在前面配置了node01、node02采集日志数据传输到Kafka,现在我们需要在node03消费Kafka数据存储到HDFS上
架构图如下
Flume配置如下
## 组件
a1.sources=r1 r2
a1.channels=c1 c2
a1.sinks=k1 k2
## source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = node01:9092,node02:9092,node03:9092
a1.sources.r1.kafka.topics = topic_start
## source2
a1.sources.r2.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r2.batchSize = 5000
a1.sources.r2.batchDurationMillis = 2000
a1.sources.r2.kafka.bootstrap.servers = node01:9092,node02:9092,node03:9092
a1.sources.r2.kafka.topics = topic_event
## channel1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/modules/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/modules/flume/data/behavior1/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
## channel2
a1.channels.c2.type = file
a1.channels.c2.checkpointDir = /opt/modules/flume/checkpoint/behavior2
a1.channels.c2.dataDirs = /opt/modules/flume/data/behavior2/
a1.channels.c2.maxFileSize = 2146435071
a1.channels.c2.capacity = 1000000
a1.channels.c2.keep-alive = 6
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_start/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = logstart-
##sink2
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = /origin_data/gmall/log/topic_event/%Y-%m-%d
a1.sinks.k2.hdfs.filePrefix = logevent-
## 不要产生大量小文件
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k2.hdfs.rollInterval = 10
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k2.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
a1.sinks.k2.hdfs.codeC = lzop
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
a1.sources.r2.channels = c2
a1.sinks.k2.channel= c2
【2】FileChannel 和 MemoryChannel 区别
MemoryChannel 传输数据速度更快,但因为数据保存在 JVM 的堆内存中,Agent 进程挂掉会导致数据丢失,适用于对数据质量要求不高的需求
FileChannel 传输速度相对于 Memory 慢,但数据安全保障高,Agent 进程挂掉也可以从失败中恢复数据
【3】FileChannel 优化
通过配置 dataDirs 指向多个路径,每个路径对应不同的硬盘,增大 Flume 吞吐量
官方说明如下:
Comma separated list of directories for storing log files. Using
multiple directories on separate disks can improve file channel
peformance
checkpointDir 和 backupCheckpointDir 也尽量配置在不同硬盘对应的目录中,保证
checkpoint 坏掉后,可以快速使用 backupCheckpointDir 恢复数据
【4】Sink:HDFS Sink
(1)HDFS 存入大量小文件,有什么影响?
元数据层面:每个小文件都有一份元数据,其中包括文件路径,文件名,所有者,所属组,权限,创建时间等,这些信息都保存在 Namenode 内存中。所以小文件过多,会占用Namenode 服务器大量内存,影响 Namenode 性能和使用寿命
计算层面:默认情况下 MR 会对每个小文件启用一个 Map 任务计算,非常影响计算性能。同时也影响磁盘寻址时间
(2)HDFS 小文件处理
官方默认的这三个参数配置写入 HDFS 后会产生小文件,hdfs.rollInterval、hdfs.rollSize、
hdfs.rollCount
基于以上 hdfs.rollInterval=3600,hdfs.rollSize=134217728,hdfs.rollCount =0 几个参数综
合作用,效果如下:
(1)文件在达到 128M 时会滚动生成新文件
(2)文件创建超 3600 秒时会滚动生成新文件
9)数据生产!!!
终于,在前面铺垫了那么多之后,我们终于可以生产数据,并把数据存储到HDFS上了,现在我们来整理整体流程!!!
流程如下
1)启动Zookeeper
2)启动Hadoop集群
3)启动Kafka
4)启动Flume
5)生产数据
此时我们可以去HDFS上查看数据了
Flume 内存优化
1)问题描述:如果启动消费 Flume 抛出如下异常
ERROR hdfs.HDFSEventSink: process failed
java.lang.OutOfMemoryError: GC overhead limit exceeded
(1)在 node01 服务器的/opt/modules/flume/conf/flume-env.sh文件中增加如下配置
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
(2)同步配置到其他服务器
JVM heap 一般设置为 4G 或更高,部署在单独的服务器上(4 核 8 线程 16G 内存)
-Xmx 与-Xms 最好设置一致,减少内存抖动带来的性能影响,如果设置不一致容易导致频繁 fullgc
-Xms 表示 JVM Heap(堆内存)最小尺寸,初始分配;-Xmx 表示 JVM Heap(堆内存)最大允许的尺寸,按需分配。如果不设置一致,容易在初始化时,由于内存不够,频繁触发 fullgc
数据采集通道启动/停止脚本
1)vim cluster.sh
#!/bin/bash
case $1 in
"start"){
echo " -------- 启动 集群 -------"
#启动 Zookeeper 集群
zk.sh start
sleep 1s;
echo " -------- 启动 hadoop 集群 -------"
/opt/modules/hadoop/sbin/start-dfs.sh
ssh node02 "/opt/modules/hadoop/sbin/start-yarn.sh"
sleep 7s;
#启动 Flume 采集集群
f1.sh start1
#启动 Kafka 采集集群
kk.sh start
sleep 7s;
#启动 Flume 消费集群
f2.sh start
};;
"stop"){
echo " -------- 停止 集群 -------"
#停止 Flume 消费集群
f2.sh stop
#停止 Kafka 采集集群
kk.sh stop
sleep 7s;
#停止 Flume 采集集群
f1.sh stop
echo " -------- 停止 hadoop 集群 -------"
ssh node02 "/opt/modules/hadoop/sbin/stop-yarn.sh"
/opt/modules/hadoop/sbin/stop-dfs.sh
sleep 7s;
#停止 Zookeeper 集群
zk.sh stop
};;
esac
结束语
至此,我们数据生产并清洗传输到HDFS结束了
后续,我们需要开始搭建Hive,进行建模了,敬请期待下一篇博客!
# 说明1:我们使用 TAILDIR Source 监控多目录,自动实现断点续传,版本需要在1.7+# 说明2:我们使用 Kafka Channel,不使用Kafka Sink,提高效率
a1.sources=r1a1.channels=c1 c2
# configure sourcea1.sources.r1.type = TAILDIR# 断点续传持久化目录a1.sources.r1.positionFile = /opt/modules/flume/log_position/log_position.json# 设置需要监控的多个目录,我们只需要一个,所以只添加一个 f1a1.sources.r1.filegroups = f1# 设置 f1 对应的监控目录a1.sources.r1.filegroups.f1 = /opt/tmp/logs/app.+a1.sources.r1.fileHeader = truea1.sources.r1.channels = c1 c2# interceptor 添加拦截器a1.sources.r1.interceptors = i1 i2# 自定义拦截器a1.sources.r1.interceptors.i1.type = com.zsy.flume.interceptor.LogETLInterceptorBuilder # ETL拦截器a1.sources.r1.interceptors.i2.type = com.zsy.flume.interceptor.LogTypeInterceptorBuilder # ETL拦截器a1.sources.r1.interceptors.i2.type = com.zsy.flume.interceptor.LogTypeInterceptorBuilder #日志类型拦截器# 根据header头信息,将source数据发送到不同的 Channela1.sources.r1.selector.type = multiplexinga1.sources.r1.selector.header = topica1.sources.r1.selector.mapping.topic_start = c1a1.sources.r1.selector.mapping.topic_event = c2
# configure channela1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannela1.channels.c1.kafka.bootstrap.servers = node01:9092,node02:9092,node03:9092a1.channels.c1.kafka.topic = topic_start # 日志类型是start,数据发往 channel1a1.channels.c1.parseAsFlumeEvent = falsea1.channels.c1.kafka.consumer.group.id = flume-consumera1.channels.c2.type = org.apache.flume.channel.kafka.KafkaChannela1.channels.c2.kafka.bootstrap.servers = node01:9092,node02:9092,node03:9092a1.channels.c2.kafka.topic = topic_event # 日志类型是event,数据发往 channel2a1.channels.c2.parseAsFlumeEvent = falsea1.channels.c2.kafka.consumer.group.id = flume-consumer

















 1511
1511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









