






前言:
整理了一些常见的SQL的函数用法(HIVE中),主要包括如下:
- regexpextract函数
- get_object_json函数
- rownumber() over函数
- date_sub函数、date_add、datediff函数

一、get_object_json 函数
应用场景:提取以json字符串的方式存储的数据
非结构化数据种类很多,日常的图片,视频都算是非结构化数据,而在数据库中,我们经常用到的以json字符串的方式存储的数据长这样↓:
{刚开始看到它的时候,心想着这和python中的字典有点像呀。后来发现,逻辑是一样的。。。非结构化数据可以将我们很多的想要提取的字段都浓缩到一个单元格中,取数起来就十分方便。举个例子:我们在利用SQL取数时候,数据库里的数据是下面这样的↓(其中json这一列便是非结构化的数据)(表名为 ailisidun_class)

我想统计所有班级中有多少人喜欢看名侦探柯南漫画,于是可以写:
select 二、regexp_extract函数
应用场景:我想提取链接里的一些值?
regexp_extract函数在hive中应用很广泛,主要和正则表达式相关(正则表达式知识可以看这里)他就像一个cool guy,可以精炼提炼出需求,比如
阿明是链接,阿黄是regexp_extract函数
某天,阿明说到,”%$JC*KDNCKSNCM,ASNC,DSV我家着火了!!*ASdafnksajnv...“
阿黄马上get到,哦,”你家着火了“
regexp_extract函数一般包括三个部分,如下,
regexp_extract(A,'B',C)A表示需要提取的字段,B表示提取类型,C有自定义数字,通常为0,(表示把对应的结果全部返回),1表示返回正则表达式中第一个() 返回。这里的B,有很多种写法,比如我们可以写成只提取英文的,提取中文的,全部都提取的,具体可以看这张图:

再举个例子
比如某多多给了小明,小黄,小兰,小邹四个专属链接,让他们分享出去,只要别人点进链接,就给他们相应报酬,他们的专属链接如下:(主要不同的是其中的那个name,name后为各自的特别标识)
- www.qiqi..../haha/name=xiaoming/....com
- www.qiqi..../haha/name=xiaohuang/....com
- www.qiqi..../haha/name=xiaolan/....com
- www.qiqi..../haha/name=xiaozou/....com
现在想统计他们每天各自链接带来了多少的点击量,(表名为moneyduoduo,链接的字段名为we_url;日期为dt;)脚本可以写成如下:
select dt,name1,count(distinct pin) as renshu
from
(
select dt,regexp_extract(we_url,'name=([a-zA-Z0-9]+)',1) as name1,pin
from moneyduoduo
where we_url like '%qiqi..../haha%'
) t
group by dt,name1
;三、row_number() over函数
这个是我最喜欢的函数了,超级好用!主要是用来找最近一次,或者最后一次,或者最早一次的某些数据。举个例子,现在表里面有每天用户登录情况,而一个用户可能一天登录很多次,这就导致表里面,同一天数据里可能会出现多条相同用户的记录。
那么如何找当天用户首次登录的记录呢?基本思路是,我们可以新建一列,然后,用户根据时间进行12345排序(这里表字段为dt(日期)、pin(设备号)、optime(登录时间,精确到分秒那种))则找到当天用户首次登录情况,我们可以写出如下:
select dt,pin,row_number() over(partition by dt,pin order by optime) as miao
from yigebiao
;找当天用户最后一次登录的明细数据,用desc倒序一下,最后再取miao=1即可
select dt,pin,row_number() over(partition by dt,pin order by optime desc) as miao
from yigebiao
;补充一下,这里的partition by就是分组的意思,paritition by dt,pin,即我想根据日期分组下的每个pin分组,这样pin的次数(再order by排序)就一目了然啦。
四、date_sub函数、date_add及datediff函数
这三个函数是时间函数,datesub是月光宝盒,可以时光倒流(?),date_add则指向未来,datediff则算时间差的。
简单来说,比如今天是5月29日,如果我们想看过去近8天的数据,我们并不需要从现在盯着日历倒数8天,而是用date_sub一行代码解决了
select dt from hahahha
where dt between date_sub('2020-05-29',7) and '2020-05-29'如果是让系统自己自动识别,可写成如下:
select dt from hahahha
where dt between date_sub(default.sysdate(-1),7) and default.sysdate(-1)date_add用法和date_sub类似,只是因为是未来的日期,所以位置需要对换一下。
而date_diff,作为一个时间函数中的靓仔,可以很快算出时间差,比如小王是1997年5月16生,则在hive sql输入如下
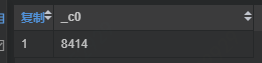
select datediff('2020-05-29','1997-05-16');于是我们可以知道小王已经存在于地球有8414天了O(∩_∩)O
date_diff还有一个很常见的应用常见,就是算留存,什么次日留存,三日留存,七日留存都可以算出来,下次写写关于留存的一些小想法。(挖坑预警!)
------------------------------------------------
以上是对于SQL中一些常用函数的一些浅显理解,如有错误,欢迎指正。
完结撒花~














 4811
4811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









