





回到目录
视图和表
表中保存的是实际数据(通过INSERT语句),而视图中保存的是SELECT语句。
因此,从表中读取数据时,实际是从存储设备(硬盘)中读取数据;从视图中读取数据时,实际上是视图在内部执行所保存的select语句并创建出一张临时表。
使用视图的优点:
- 节省存储空间。视图保存的是从表中读取数据的select语句,无需保存实际数据。
- 节省书写时间。将频繁使用的复杂select语句保存成视图,每次使用时,调用视图即可。
- 视图中的数据会随着原表的变化自动更新。因为视图就是select语句,原表更新了,select语句取出来的数据自然也是最新的。
创建视图
创建视图使用CREATE VIEW语句。
CREATE VIEW 视图名(视图列名1, 视图列名2,... )
AS
语句;-- 保存在视图中的select语句
-- 例如
CREATE VIEW ProductSum(type, cnt)
AS
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type;虽然视图保存的是select语句,但是使用视图就和使用表是一样的。
-- 使用视图
SELECT 视图列名1, 视图列名2, ...
FROM 视图名;
-- 例如
SELECT type, cnt
FROM ProductSUM;将复杂庞大的select语句保存在视图中后,就可以通过简单的select语句得到相同的结果。若不是用视图,则可能需要频繁地输入复杂select语句,费时费力。
上述的视图叫单一视图,还有多重视图,即在视图的基础上再创建的视图。但是对大多数DBMS来说,多重视图会降低性能。
使用视图的注意事项
- 定义视图时不能使用order by语句。
- 视图不能被更新语句(insert、update、delete)随意更新。
视图归根结底还是要从表中读取数据,能在原表中反映出来的更新,才能用于视图的更新。
例如通过分组汇总(group by)得到的视图就无法更新,因为这样的更新无法反映到原表,原表要和视图同时更新。为什么无法反映到原表?考虑下面例子:
一个视图通过商品表按种类分组得到,如下所示。
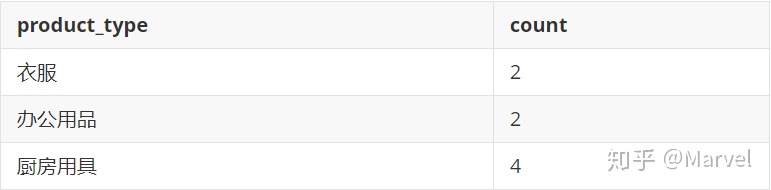
现在要通过语句INSERT INTO ProductSum VALUES ('电器制品', 5);对此视图进行更新,显然,这是无法反映到原表的更新。视图中电器制品多了5个,那原表怎么表示这多出来的5个电器呢,它们的编号、名称、售价又是多少呢?无从得知。
此外,PostgreSQL的视图会被初始设定为只读,若要更新需要执行额外的指令。
删除视图
使用DROP VIEW语句,语法如下:
DROP VIEW 视图名;子查询和视图
子查询就像一次性视图。
上文提过,视图保存的不是实际数据,而是可以读取数据的select语句,子查询就是将这些select语句直接拿来使用,省去了创建视图这一步。
-- 例如
SELECT product_type, cnt_product
FROM (SELECT product_type, COUNT(*) AS cnt_product
FROM Product
GROUP BY product_type) AS ProductSum;-- ProductSum为子查询名称
-- 括号内的select语句就是原本定义视图的语句,此处直接将其使用在from子句当中。就像上面说的,子查询是一次性的,执行后不会被存储。可以发现,这也是一种select嵌套的结构。
from子句中的内层select查询(子查询)会先执行,然后再执行外层select查询。
自然,可以增加这种嵌套的层数,但这样会降低性能和代码可读性。
-- 子查询的多层嵌套
-- 例如
SELECT product_type, cnt_product
FROM (SELECT *
FROM (SELECT product_type, COUNT(*) AS cnt_product
FROM Product
GROUP BY product_type) AS ProductSum1-- 子查询1
WHERE cnt_product = 4) AS ProductSum2;-- 子查询2
-- 从子查询1里选取cnt_product = 4的记录的所有列作为子查询2,再从子查询2里选出product_type和cnt_product这两列。标量子查询
标量子查询就是返回单一值的子查询,即只能返回一行一列的结果。
因此,所有使用到单一值(常数、列名等)的地方,都可以用标量子查询代替。
例如,在where中使用:
SELECT product_id, product_name, sale_price
FROM Product
WHERE sale_price > (SELECT AVG(sale_price) FROM Product);
-- 选取出售价大于平均售价的记录的编号、名称、售价三列可能有人会问,为什么不能直接用AVG(sale_price)代替代码中括号部分的内容。因为where中不能使用聚合函数!
再比如,在having中使用:
SELECT product_type, AVG(sale_price)
FROM Product
GROUP BY product_type
HAVING AVG(sale_price) > (SELECT AVG(sale_price) FROM Product);
-- 此处的标量子查询相当于一个常数
-- 按商品种类分组后,选取出组内商品售价的平均值高于全部商品的售价平均值的记录。关联子查询
对表中某一部分记录的集合,例如group by分好的组内,进行比较时,需要使用关联子查询。
光看文字描述可能太抽象,考虑如下例子:选取出商品种类中,高于该种类的平均售价的商品,读取它们的编号、名字和售价。
SELECT product_id, product_name, sale_price
FROM Product AS P1
WHERE sale_price > (SELECT AVG(sale_price)
FROM Product AS P2
WHERE P1.product_type = P2.product_type);按照语句的执行顺序,先执行第一个from子句,即先在表Product中选取一条记录,然后将该记录的售价和某个常数作比较,即执行下一行的where子句,若大于那个常数,这条记录将被选取,并提取出编号、名称和售价列。这就是第一个select子句要完成的操作。接下来就是怎么理解那个常数,也就是括号中的select子句。
这里用到的是关联子查询,对于刚刚要用于比较的P1中的记录,继续在Product表中从头往后搜索(此处用了别名P1、P2以示区分两次选取的表),在P2中选出所有商品种类和P1的那条记录的商品种类相同的行,计算这些行的平均值,这就相当于按种类分组,只计算同一种类的行的售价平均值。所以关联子查询得到的这个结果就是同种类的平均售价。















 5156
5156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









