





风控模型中监督学习的任务最多,监督学习少不了变量x和目标y,前面的章节中说过准备的变量要尽量的多,就是因为这里有衡量变量预测力的数学指标,可以自动筛选变量。变量预测力的指标非常的多,有信息增益、信息增益率、gini、iv、卡方检验等, 这些指标有些和算法绑定在一起,也可以单独拿出来使用。本章重点介绍iv,它在本系列文章中的评分卡制作中会使用到。
iv又称信息值,即information value,它的原理很简单。为了说明它的定义,先把数据摆出来,以下为变量age和目标变量y{0, 1},如果要计算age的iv值,需要以下几步:
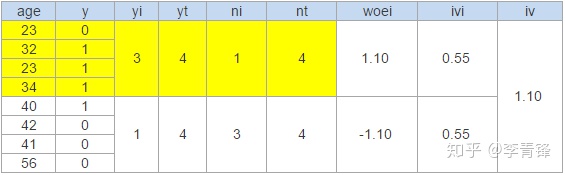
1. 进行分组,如果变量是分类型的就可以直接进行下一步,关于分组在实际项目中最好用最优分组方法,基于决策树的分组方法,十分高效,这里先人工将age分成两组,标黄的为一组,其余的为一组。
2. 计算woe,#yi代表分组中1的数量,#yt代表整体中1的数量,#ni代表分组中0的数量,#nt代表整体中0的数量,#yi/#yt表示分组中的1在总体1中的占比,#ni/#nt代表分组中的0在总体0中的占比,二者的比值反应了分组中的区分度,注意这个比值是重点,后面的操作都是在此基础上的延伸,将比值取对数得到当前分组的woei。即
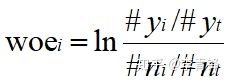
3. 计算分组的iv,将分组的woe乘以正负样本在总体占比之差即得到分组的iv,需知乘以这个因子一是可以将iv值调整为正数,二是可以增加分组样本量的权重影响。即
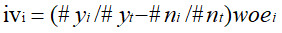
4. 将各个分组的iv相加,即得到变量的iv,即
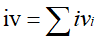
观察可以发现这个iv的定义和psi的定义很相似,没错,它们的技术思路是一样的,不过代表的含义却相去千里。在第一步中提到如果变量是连续型的话,需要进行分组,那么要发成几组呢?具体怎么分呢?本质上iv的计算是为了衡量变量的预测能力,也就是对因变量的区分能力,所以能使区分能力最大化的划分方法就是最好的划分方法,当然还要考虑各组样本的数量,如果过少,则不能划为一组,因为该组的区分能力不具有统计意义,分组要尽量小于10组,过多的分组在建模过程中将会导致过拟和。
常见的分组方法有等距划分和最优划分,等距划分思路很简单,即将所有数据划分为等宽度的区间,虽实现简单,理解容易,但对目标的区分能力却不是最好的,实际中最好采用最优分组。最优分组有很多种方法,我们介绍一种基于决策树的划分方法,现在暂时将最优分组搁置一旁,来了解一下决策树算法的原理。我们依旧拿iris数据集作为参考:
1. 从所有的属性中找到一个最有区分能力的属性,作为根节点,最有区分能力的属性即是信息增益值最大的那个。
2. 如果选中的节点为分类型,则直接按枚举值进行划分为多个孩子节点,如果为数值型,则按最优分裂点将分成数据划分为两个孩子节点。
3. 针对孩子节点继续执行1和2步,直到满足停止条件。
停止条件有:树深度达到最大值,节点样本量达到最小值,叶节点数量达到最大值,属性信息增益小于最小值,节点全部为某一类。
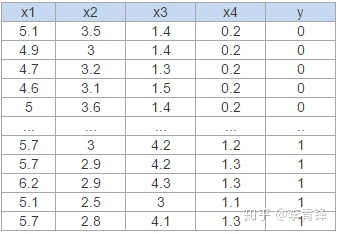
下面以iris数据集为例打印出决策树图形,其代码和结果分别如下面展示,首先选中的是x2,它的信息增益为1.585,分裂点为2.45,samples代表总样数,value代表各个类别的数量,这里是三个类别各占50个,当x2 <= 2.45时,它的数据子集全部都是一类的[50, 0, 0],所以停止生长,从x > 2.45的子节点继续划分,直到达到最大树深度3。
from sklearn.datasets import load_iris
from sklearn import tree
import graphviz
def decision_tree_graph():
x, y = load_iris(return_X_y=True)
clf = tree.DecisionTreeClassifier(criterion='entropy', max_depth=3, min_samples_leaf=0.05)
clf = clf.fit(x, y)
dot_data = tree.export_graphviz(clf, out_file=None)
graph = graphviz.Source(dot_data)
graph.view()
if __name__ == '__main__':
decision_tree_graph()
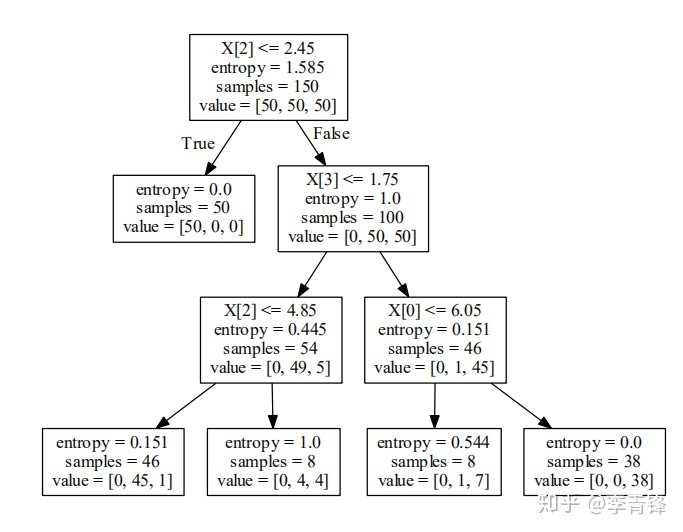
再看上面的决策树原理的第一步,里面提到的信息增益是什么呢?它既是树的属性筛选标准,也是属性的分裂标准。我们继续抛出另外一个概念,熵。
熵是衡量数据的不确定性的,不管它的定义有深奥,接地气的说法就是目标变量中0和1的比例大小的程度,比例越大则越确定,越小越不确定,确定就意味着区分能力强。当不考虑x,只看y的时候得到整个数据集的熵如下公式所示,s代表数据集,pi代表某个类别样本占比,这个值越小则越确定,区分力越强,举例如果只有两个类{0,1},p0=0.1, p1=0.9,则e(s)=0.47,如果p0=0.5,p1=0.5,则e(s)=1,这个结论印证了前面的定义。

当考虑某个自变量A对目标变量的影响时,A的影响下整体数据集的熵为下面这个公式,实际上它是属性A的各个分组的加权熵,也是各组的区分能力的综合体现,这个值一般要小于等于e(S)。
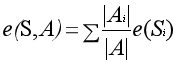
基于前两个熵,将二者相减,则得到属性A的信息增益,它可以衡量对目标变量的区分能力,相信到这里可以理解了其中的原因。
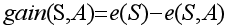
现在回过头来再详细解释一下连续型变量的决策树属性选择规则,首先针对某个变量和相应的y两列数据(x, y)计算在变量各个取值的信息增益,如果某个点的信息增益最大,则将此时的点作为最优分裂点,此时的信息增益作为该属性的信息增益,然后再去计算其它属性的最优分裂点和信息增益,计算所有的属性之后,选信息增益最大的属性作为树的节点,同时也确定了属性的最优分裂点。
如果前面的都掌握了之后,前面所说的变量最优分组决策树方法也就很简单了,它就是将(x,y)输入决策树算法,最终得到的各个叶节点就是最优分组。最大叶节点数可以作为参数调整分组的数量,叶节点最大样本量可以作为分组的最小样本数。
最后我们用一个代码来实战化本章的所学理论,用的是iris数据集中的类别为0和1的行,总共100行,最大分组数为5,最小样本数为总样本的百分五。
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from tqdm import tqdm
# 调用决策生成最优分裂点
def get_decision_tree_cut_point(data, col):
data_notnull = data[[col, 'y']][data[col].notnull()] # 删除空值
cut_point = []
if len(np.unique(data_notnull[col])) > 1:
x = data_notnull[col].values.reshape(-1, 1)
y = data_notnull['y'].values
clf = DecisionTreeClassifier(criterion='entropy', # “信息熵”最小化准则划分
max_depth=3, # 树的深度
max_leaf_nodes=5, # 最大叶子节点数
min_samples_leaf=0.05) # 叶子节点样本数量最小占比
clf.fit(x, y) # 训练决策树
threshold = np.unique(clf.tree_.threshold)
x_num = np.unique(x)
for i in threshold:
if i != -2:
point = np.round(max(x_num[x_num < i]), 4) # 取切分点左边的数
cut_point.extend([point])
cut_point = [float(str(i)) for i in list(np.unique(cut_point))]
cut_point = [-np.inf] + cut_point + [np.inf]
return cut_point
# 依据最优分裂点将变量分组
def get_cut_result(data, col_continuous_cut_points):
cols = [i for i in data.columns if i not in [i[0] for i in col_continuous_cut_points]]
data_cut_result = data[cols].copy()
for col, cut_points in tqdm(col_continuous_cut_points):
data_cut_result[col] = pd.cut(data[col], cut_points).astype("str")
data_cut_result = data_cut_result.fillna('null')
data_cut_result.replace('nan', 'null', inplace=True)
return data_cut_result
# 最优分组主方法
def best_group(data):
col_continuous_cut_points = []
for col in tqdm(item for item in data.columns if item != 'y'):
point = get_decision_tree_cut_point(data[[col, 'y']], col)
if point:
col_continuous_cut_points.append([col, point])
col_continuous_cut_points = col_continuous_cut_points # 连续变量的切分点,按小于等于,大于切分,空值单独归位一类,例如:['scorecashon', [-inf, 654.0, 733.0, 754.0, inf]]
data_discrete = get_cut_result(data, col_continuous_cut_points) # 按切分点划分数据,得到全部的离散数据
return data_discrete
# 某个属性的iv计算方法
def get_woe_iv(data_discrete, col):
result = data_discrete.groupby(col)['y'].agg([('1_num', lambda y: (y == 1).sum()),
('0_num', lambda y: (y == 0).sum()),
('total_num', 'count')]).reset_index()
result['1_pct'] = result['1_num'] / result['1_num'].sum()
result['0_pct'] = result['0_num'] / result['0_num'].sum()
result['total_pct'] = result['total_num'] / result['total_num'].sum()
result['1_rate'] = result['1_num'] / result['total_num']
result['woe'] = np.log(result['1_pct'] / result['0_pct']) # WOE
result['iv'] = (result['1_pct'] - result['0_pct']) * result['woe'] # IV
result.replace([-np.inf, np.inf], [0, 0], inplace=True)
result['total_iv'] = result['iv'].sum()
result = result.rename(columns={col: "cut_points"})
return result
# 计算每个属性的iv
def get_iv(data):
col_iv = []
for col in tqdm([i for i in data.columns if i != 'y']):
col_woe_iv = get_woe_iv(data, col)
col_iv.append([col, col_woe_iv['iv'].sum()])
return col_iv
def run():
x, y = load_iris(return_X_y=True)
x_df = pd.DataFrame(data=x, columns=['x1', 'x2', 'x3', 'x4'])
y_ser = pd.Series(data=y, name='y')
data = pd.concat([x_df, y_ser], axis=1)
data = data[(data.y != 2)]
data_discrete = best_group(data)
col_iv = get_iv(data_discrete) # iv值计算
print(col_iv)
if __name__ == '__main__':
run()
得到的结果:[['x1', 1.0803397172395013], ['x2', 2.2124785653672894], ['x3', 0.0], ['x4', 0.0]],需要注意的是x3和x4都为0,无需理会,这是因为分组里面全为0或1,代码不够健壮导致,这种情况在实际项目中几乎不会存在。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









