





江湖上流传着这么一句话——分析不识潘大师(PANDAS),纵是老手也枉然。在长期的数据分析实战中我将pandas总结为”两类基本数据结构, 四类基础操作,四类难搞数据类型“。用三篇文章来介绍这三大模块,这是系列文章中的第一篇。

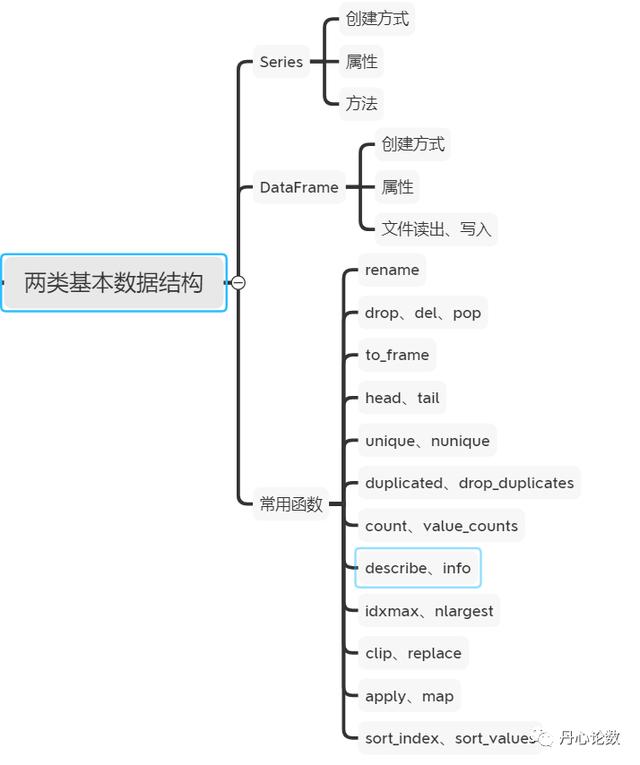
两类数据结构
1、Series
可看作是带有索引的一维数组。
(1)创建方式:pd.Series(可迭代对象)

(2)属性:值(value)、索引(index)、名字(name)、类型(dtype)用(.)调用
(3)索引与切片:s["a"],s["a":"c"],s[1],s[1:4]
(4)方法调用:s.mean()/std()/sum()....
2、Dataframe
可看作表格型数据结构,每一列为一个Series格式
(1)创建方法:
a、pd.DataFrame()可传入如下数据结构进行创建:

b、文件读入与写出
读取:
pd.read_csv(文件路径,参数):将csv文件读为dataframe
pd.read_excel(文件路径,参数):将.xlsx文件读为dataframe
pd.read_table(文件路径,参数):将txt文件读为dataframe
pd.read_sql(sql语句,参数):将数据库表读为dataframe
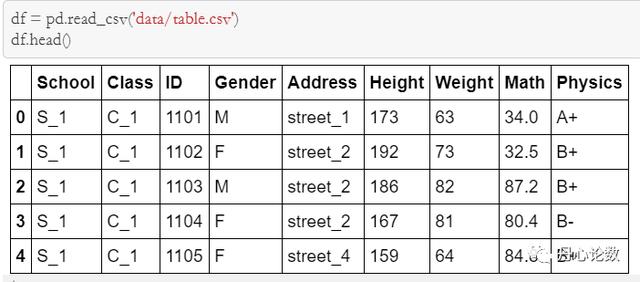
写入:
dataframe.to_csv(文件路径,参数):将dataframe存为csv文件
dataframe.to_excel(文件路径,参数):将dataframe存为excel文件
(2)属性:值(values)、索引(index)、列(columns)、索引名字(index_name)、列名(columns_name)、形状(shape)类型(dtypes)用(.)引用;

dataframe具有索引对齐性,在运算中自动取索引相同的数据进行运算,这是dataframe的一个很重要的特性。

3、常用函数
(1)rename:修改索引名和列名,参数为字典格式,调用实例:
df.rename(index={"a":"b"},columns={"old_col":"new_col"})

(2)drop、del、pop:删除列的函数
将df的列“col1”删除:
del df["列名"]
df.drop("col1",axis=1) or df.drop(columns="col1")
df.pop("col1")删除col1并返回该列的值

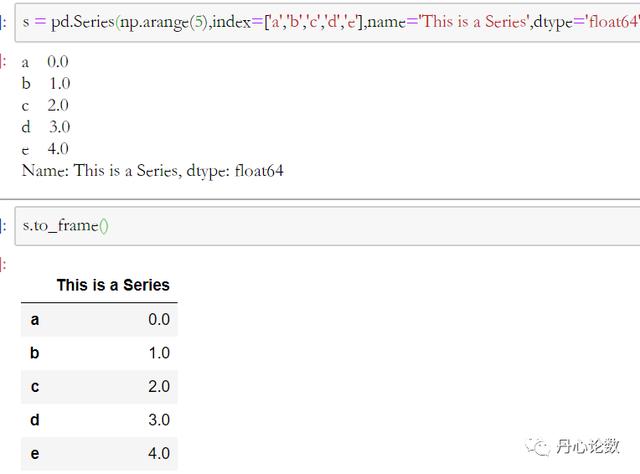
(3)to_frame():将series转为dataframe
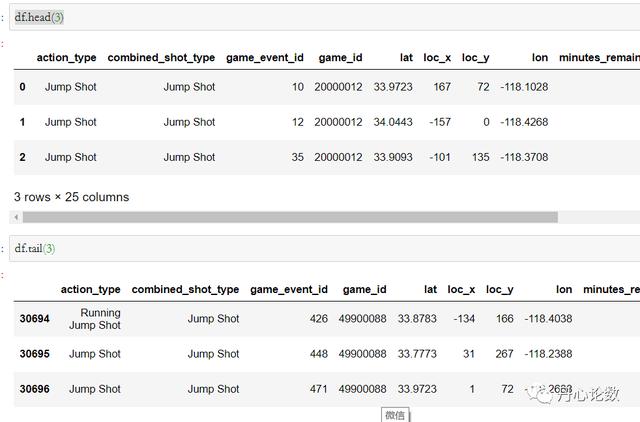
(4)head和tail:显示前n行和后n行
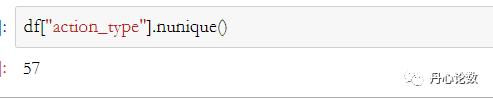
(5)unique和nunique:显示所有唯一值和唯一值的个数

(6)duplicated和drop_duplicates:返回是否是重复值和删除重复值

(7) count和value_counts:返回非缺失值的个数和每个元素出现的个数

(8)describe和info:describe默认统计数值型数据的各个统计量【均值、最值、中位数、四分位数】。info函数返回有哪些列、有多少非缺失值、每列的类型


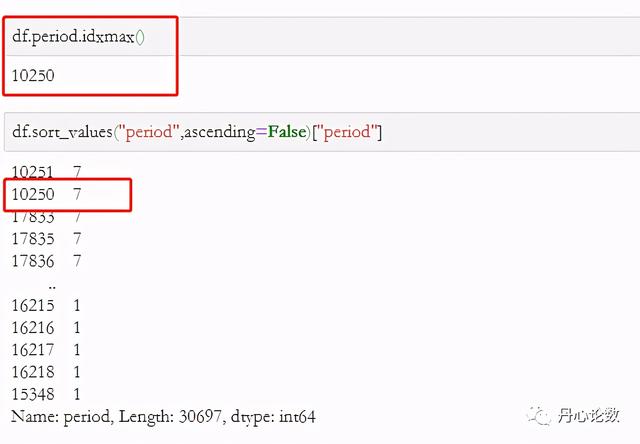
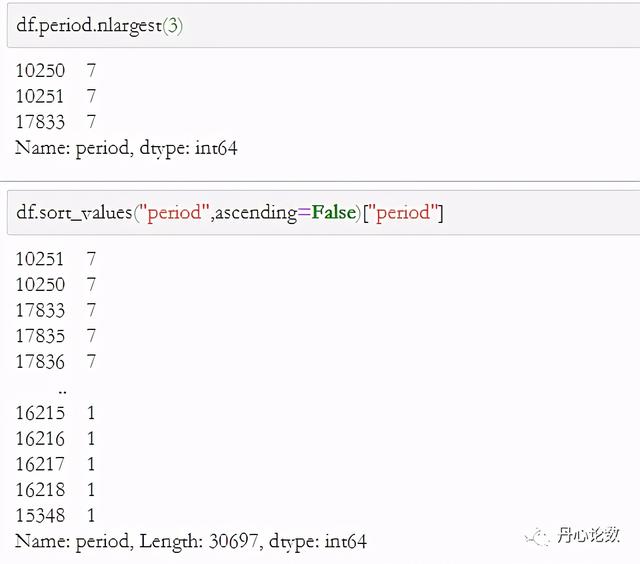
(9)idxmax和nlargest:返回最大值所在的索引和返回前n大的元素值
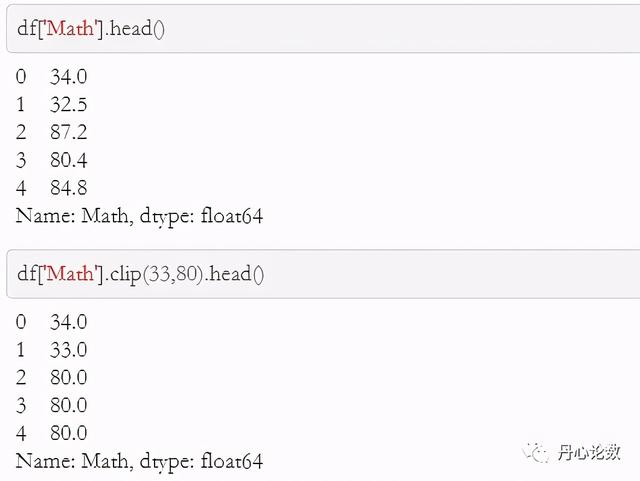
(10)clip和replace:对超过或者低于某些值的数进行截断和对某些值进行替换
(11)apply和map:一个高级函数,可看作对for循环的高级封装和速度优化,参数可以是映射或者函数,series调用时是对每个元素进行操作,dataframe调用时是对每个列进行操作,需要配合axis参数。map函数是对每个元素进行操作

(12)sort_index和sort_values:按照索引进行排序和按照列【可以是多个列】进行排序

















 2785
2785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









