





请先看下这个case.
对某一个key value应用,从网卡接收数据包到应用层处理,再把数据发送出去,整个系统资源消耗情况如下:

可以看出,Sockets接口+TCP是系统瓶颈。
根据下图模型,瓶颈在于TCP(包括sockets接口)。
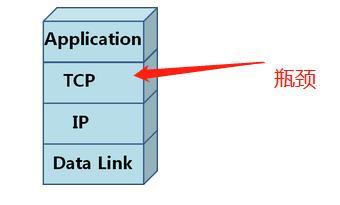
要想提升系统吞吐量,必须要优化TCP。
由于网络延迟的存在,对用户体验影响更大的是如何快速传递数据到客户端,而这属于流量优化的范畴。
本文讲述如何优化TCP性能和TCP数据传递。
1、什么是TCP加速
引用百度百科的定义:

主流的TCP加速方式主要有 :基于流量的加速传递和数据包处理性能优化。
基于流量的方式主要通过修改拥塞控制算法来达到快速传递数据包的目的。
数据包处理性能优化包括内核优化、TCP offload和基于用户态TCP协议的方式。这些方式可用于优化数据包处理,从而提升系统的吞吐量。
2、基于流量的TCP加速方式
2.1 TCP双边加速
TCP双边加速需要在TCP连接的两端部署硬件设备或安装软件。
双边加速的优点是可以利用压缩等技术进一步提升TCP传输效率,缺点是部署麻烦。
双边加速一般应用于公司不同分支之间的远距离访问。
下图是双边加速的一个例子。TCP加速设备之间采用SCTP的协议进行交互,而原本TCP对端跟TCP加速设备之间则采用常规的TCP协议进行交互。这种透明代理的方式方便了TCP加速设备之间采用特殊的方式来加速。

2.2 单边加速
TCP单边加速只需要在在TCP的一端部署软件或设备,达到提升TCP快速传输数据的目的。
绝大部分TCP单边加速都是通过修改TCP的拥塞控制算法来实现。
下图显示了某商用化产品的单边加速情况,数据包的发送很暴力,并没有慢启动过程。这种无视网络状况发送数据包的方式,大部分场景下确实能够提升性能,但这样的性能提升方式其实是抢占了互联网带宽资源,就像高速公路走应急车道一样。

近几年出现的google拥塞控制算法BBR可以看成是单边加速的一种。

上图展示了相对于传统拥塞控制算法CUBIC,BBR算法在网络丢包情况下仍然表现优异,原因在于BBR算法摒弃丢包作为拥塞控制的直接反馈因素,通过实时计算带宽和最小RTT来决定发送速率和窗口大小。
在移动应用场合,大部分网络丢包并不是由于路由器网络拥塞导致,因此在移动场合,BBR算法具有更好的适应性。
在Linux内核4.9以上版本(不包括docker环境),使用BBR算法,一般只需要在sysctl.conf文件加上下面两句:

然后执行sysctl -p使其生效。
TCP单边加速的优点是只需要在一侧进行部署,缺点是无法直接利用压缩等功能,而且大都会破坏互联网的公平性。
3、内核优化
3.1 纯内核优化
根据Wikipedia内容:

我们得知,内核需要根据实际场景进行优化,不能一概而论。合理优化,可以提升性能很多(有时能够提升10倍),但如果盲目优化,性能反而下降。
当今的内核,在大部分场景下,TCP buffer能够自动调整buffer大小来匹配传输,所以在内核方面需要优化的地方就是选择合适的拥塞控制算法。
下面是Linux默认算法CUBIC和BBR算法在丢包情况下的对比情况:
在丢包情况下,BBR所受影响没有Linux TCP默认算法CUBIC那么大,而且在20%以下的丢包率情况下性能远超CUBIC。一般建议在非网络拥塞导致丢包的场合使用BBR算法,例如移动应用。
对于带宽比较大,RTT时间比较长的应用场景,可以参考。
3.2 Dedicated fast path
由于内核处理TCP是通用的处理方式,不同的场景,执行的路径是不一样的,针对某些场景做特殊的优化,可以大大提升TCP的处理性能。
这方面可以参考论文"TAS: TCP Accleration as an OS Service"。
4、TCP offload
内核消耗性能的地方主要有如下四个方面:

目前TCP offload常用的功能是TCP/IP checksum offload和TCP segmentation offload,主要是解决上面第二个问题。
其它问题需要更加强大的网卡支持,这方面可以参考"https://www.dell.com/downloads/global/power/1q04-her.pdf"。
"TCP Offload Engines"论文中描述了网络应用内存拷贝的情况,具体参考下图。

不管是发送路径还是接收路径,系统存在大量内存拷贝,直接影响了TCP/IP协议栈性能,可以利用TCP offload功能,NIC直接拷贝到应用的buffer中去,减少拷贝次数,从而提升性能。
TCP offload可能是未来的趋势,部署方便,代价小,是非常值得关注的一个方向。
5、用户态TCP协议
用户态的协议栈在下列场合比较有用:

是否要采用用户态TCP协议栈,可以参考"https://blog.cloudflare.com/why-we-use-the-linux-kernels-tcp-stack/".
6、总结
TCP加速是一个很大的领域,这方面应用得好,可以极大提升程序的性能,因此性能优化不要忽视这方面内容。















 1283
1283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









