






Avro(读音类似于[ævrə])是Hadoop的一个子项目,由Hadoop的创始人Doug Cutting(也是Lucene,Nutch等项目的创始人)牵头开发。Avro是一个基于二进制数据传输高性能的中间件。在Hadoop的其他项目中例如HBase(Ref)和Hive(Ref)的Client端与服务端的数据传输也采用了这个工具。Avro是一个数据序列化的系统。Avro可以将数据结构或对象转化成便于存储或传输的格式。Avro设计之初就用来支持数据密集型应用,适合于远程或本地大规模数据的存储和交换。它的主要特点有:
丰富的数据结构类型;
快速可压缩的二进制数据形式,对数据二进制序列化后可以节约数据存储空间和网络传输带宽;
- 存储持久数据的文件容器;
- 可以实现远程过程调用RPC;
- 简单的动态语言结合功能。
当前市场上有很多类似的序列化系统,如Google的Protocol Buffers, Facebook的Thrift。Avro提供着与诸如Thrift和Protocol Buffers等系统相似的功能,但是在一些基础方面还是有区别的,主要是:
动态类型:Avro并不需要生成代码,模式和数据存放在一起,而模式使得整个数据的处理过程并不生成代码、静态数据类型等等。这方便了数据处理系统和语言的构造。
未标记的数据:由于读取数据的时候模式是已知的,那么需要和数据一起编码的类型信息就很少了,这样序列化的规模也就小了。
不需要用户指定字段号:即使模式改变,处理数据时新旧模式都是已知的,所以通过使用字段名称可以解决差异问题。
Avro依赖模式(Schema)来实现数据结构定义。可以把模式理解为Java的类,它定义每个实例的结构,可以包含哪些属性。可以根据类来产生任意多个实例对象。对实例序列化操作时必须需要知道它的基本结构,也就需要参考类的信息。这里,根据模式产生的Avro对象类似于类的实例对象。每次序列化/反序列化时都需要知道模式的具体结构。所以,在Avro可用的一些场景下,如文件存储或是网络通信,都需要模式与数据同时存在。Avro数据以模式来读和写(文件或是网络),并且写入的数据都不需要加入其它标识,这样序列化时速度快且结果内容少。由于程序可以直接根据模式来处理数据,所以Avro更适合于脚本语言的发挥。
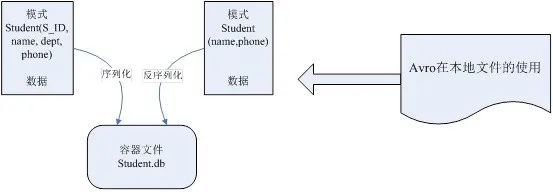
Avro支持两种序列化编码方式:二进制编码和JSON编码。使用二进制编码会高效序列化,并且序列化后得到的结果会比较小;而JSON一般用于调试系统或是基于WEB的应用。对Avro数据序列化/反序列化时都需要对模式以深度优先(Depth-First),从左到右(Left-to-Right)的遍历顺序来执行。基本类型的序列化容易解决,混合类型的序列化会有很多不同规则。对于基本类型和混合类型的二进制编码在文档中规定,按照模式的解析顺序依次排列字节。对于JSON编码,联合类型(Union Type)就与其它混合类型表现不一致。
Avro为了便于MapReduce的处理定义了一种容器文件格式(Container File Format)。这样的文件中只能有一种模式,所有需要存入这个文件的对象都需要按照这种模式以二进制编码的形式写入。对象在文件中以块(Block)来组织,并且这些对象都是可以被压缩的。块和块之间会存在同步标记符(Synchronization Marker),以便MapReduce方便地切割文件用于处理。下图是根据文档描述画出的文件结构图: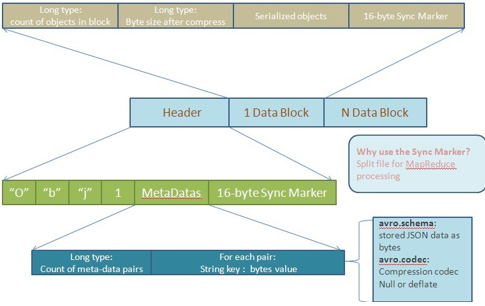
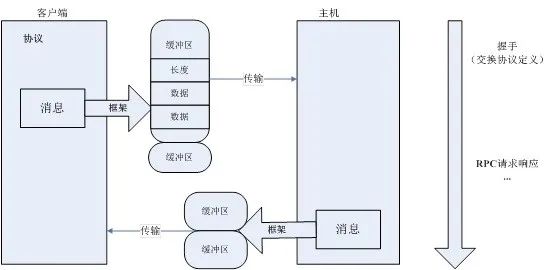
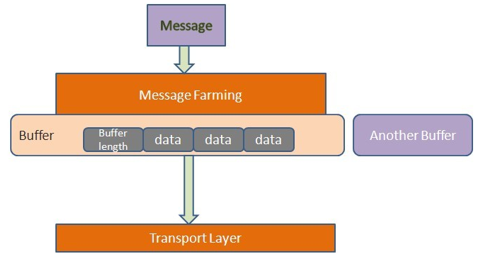
每个缓冲区以四个字节开头,中间是多个字节的缓冲数据,最后以一个空缓冲区结尾。这种机制的好处在于,发送端在发送数据时可以很方便地组装不同数据源的数据,接收方也可以将数据存入不同的存储区。还有,当往缓冲区中写数据时,大对象可以独占一个缓冲区,而不是与其它小对象混合存放,便于接收方方便地读取大对象。对象容器文件是Avro的数据存储的具体实现,数据交换则由RPC服务提供,与对象容器文件类似,数据交换也完全依赖Schema,所以与Hadoop目前的RPC不同,Avro在数据交换之前需要通过握手过程先交换Schema。
参考资料:
Avro官方文档
http://avro.apache.org/docs/current/spec.html
Doug Cutting的文章
http://www.cloudera.com/blog/2009/11/avro-a-new-format-for-data-interchange/
各序列化系统性能比较
http://wiki.github.com/eishay/jvm-serializers/
原文链接:https://www.biaodianfu.com/avro.html
往期推荐 点击标题跳转 1、Spark速度比MapReduce快,不仅是内存计算 2、干货 | Kafka 内核知识梳理,附思维导图 3、MapReduce Shuffle 和 Spark Shuffle 结业篇 4、实时数仓 | 你想要的数仓分层设计与技术选型














 4728
4728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









