






说到语言和语言范式的演进,我们会发现早在ES6加入lamda表达式和更多数组的组合子方法的同时,主流高级语言如Java8、Python乃至C++等都有了相关支持;关注到前端框架、库中的内容,和Java虚拟机上的Groovy、Scala、Kotlin的发展,说明以类操作为主的语言逐渐在吸纳函数式编程的优点。
这其中,不管是语言的feature、框架和库的补充、还是设计模式的实现,实际上都是在寻求对编程实现中遇到的一些问题更系统化的解决方案。
JS在设计之初语言层面还是比较简单,后面添加的内容以扩展为主。对函数良好的支持、原型继承和灵活的语言类型使得它可以化繁为简,用精炼的元素堆叠复杂的结构。
我们还是先探讨基于函数式的编码思维,随后额外讨论一些前端开发的其他相关特征。
一 状态和副作用
对于大多数系统来说,我们根据状态的变化来决定系统行为、体现在系统之外;在内部,我们用明确的属性值或全局的变量来记录当前系统的状态;电梯里有几个人,水管里自来水传递到了哪个节点,这些都直接影响到接下来的行为的选择和执行。

图一 电梯的状态影响我们的判断和行为
语言上,我们使用if、while等语句,描述在某些状态下的程序执行次序和跳转方向。我们还会做for循环。如果把代码块看做一段过程,过程中语句执行时一定会产生副作用,以产生我们需要的结果。
我们可以看到一段过程的运行时,状态改变和对外输出副作用是一定会发生的,否则就只是一个占用资源(同样是副作用)的无意义的运行过程。
状态和副作用在我们的流程树中,在每段流程中伸出了枝丫。理想情况我们希望我们的系统是流程树组成的小片森林,而实际上可能是一片荆棘。它有很好的聚合度,每个模块也能很灵活地处理外部状态变化导致的内容变化。但当外部变化不可控、模块执行的时序会对模块产生影响时,整理起来会很麻烦。

图二 不同的状态意味着节点的不同形态
良好的设计可以帮助我们规避系统中各状态的高耦合;我们此时可能会借由一些额外的分层(适配器、中间者、代理、外观包装等等),限制这些内部状态变化直接交汇影响,进而保障系统的可维护和扩展性。
回到函数式,函数式的思维中也要处理状态和副作用;之前说过,没有状态和没有副作用的程序是无意义的。函数式的思想在与:基于要发生的过程,偏向于把状态处理集中在过程的一段,尽量理想化地处理成过程的入参;将副作用集中在过程的另一端作为结果。面向对象编程封装不确定因素,函数式减少不确定因素。
函数式语言的设计出发点偏向于研究怎么把过程进行组合拼装复用,这个组合拼装的过程是没有外部状态参与进来的。基于过程同样需要进行一些批量操作、封装、抽象,不过这些操作针对的对象是需要集中管理的命令。下节我们讨论下关于过程的抽象。
二 过程和高阶抽象
函数在某些语言语境(比如JS)下意味着过程。
构建过程抽象和构建数据抽象是我们计算机语言系统的两种世界观。抽象的核心在于对本质的解释和屏蔽细节处理。
我们可以方便地用一个类型/原型来定义一个实例,以便高效地声明一类数据模型;随着时间的进展,这些数据模型的状态发生变化,互相影响,进而演化出我们的整套系统。
这种描述有些类似电影中的群戏,《十二硬汉》中十二个主角代表十二种人物类型,状态变化反应此类人物的普遍心理,进而影响整个电影的走向。

图三 群戏
与此同时,对于过程,我们也可以高效地抽离。我们可以通过命令、迭代器这些概念,来用类型描述我们的过程/函数,这种世界观类似上述数据模型层面的抽象。
对于函数式来说,如果不是很执着于过程的归类和定义,我们可以尝试多做一些事情。
1 我们可以快捷地把过程反复包装
方便过程反复包装的背景优势有:
(1) 在这里函数式可以使用匿名函数,即没有锚的过程抽象;
(2) 函数式之外,我们利用语言特性进行一些快捷的元编程操作,比如模板能力、原型能力(JS),这方便我们打破类型束缚和编译期限制。
元编程的能力不必须是哪一种,或者说并不是必选的。但如果我们不能快捷地在运行时更改方法的运行方式,对过程的精简处理就会变得很啰嗦,甚至受限于频繁地编译。虽然此处意味着纯函数会受到隐形的影响。
这里会有一些feature方向上冲突,更灵活的能力往往意味着更大的编码风险。不过函数式集中处理状态和副作用的做法会帮助处理风险,甚至稳定性更高。函数式的类型处理也更关注于能力。后面我们在第五节再论。
代码一 过程的封装
// 对数组map的容错操作
const _map = (arr, func) => !!(arr && arr.length) && arr.map(func)
// JSX中
{
_map(items, group => {
return (
<div key={group.id} className="grid-row">
{
_map(group, x => ( <div key={x.id}>{x.name}</div> ))
}
</div>
)
})
}
2 我们关注另一种软件世界观: 流过系统的信息流
这种系统的表达在电影中可以类比于长镜头。长镜头往往以一个主要状态(主角或情节推进),一个镜头反复切换到观众需要关注的内容,不切换大场景,一镜到底表述整个过程和结果。

图四 长镜头/一镜到底 《鸟人》
信息流式的系统更贴合我们现在的互联网场景。用户通过营销被吸引进我们的商业平台,查看必要的信息后,一定几率转化生成契约,商家进行履约,商品被配送,最终完成整个交易。这一场景明显区别于早期以信息归纳、增删改查为主要能力的维护状态的管理系统。
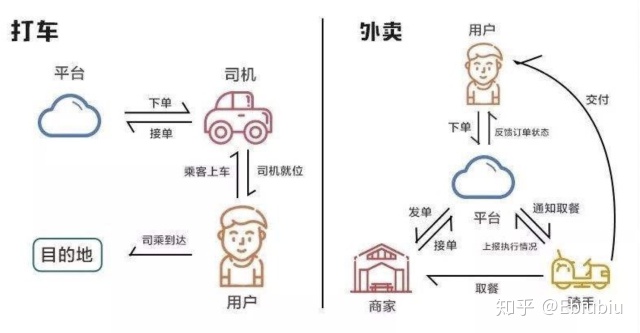
图五 信息流/交易和履约
整个链路我们使用用户、商家、合同、商品、配送的Keys,串联起清晰的软件模型。
对于信息流来说,我们需要处理很多关于过程本身的工作。并发并行、同步异步、有限工作还是无限待命、哪些工作流需要合并哪些又需要拆分。
如果能系统地区分过程的种类并进行优化,会方便我们节省处理业务流程的精力。
以上两点可以看做是对过程的更高程度的抽象:反复对过程进行抽象使用 和 对信息流过程的处理方法归纳,使得我们可以更高效地描述系统的运行。
关于函数的抽象我们聊得稍微干了点。下面两节我们回到程序的设计中,看下函数式思维影响编码设计思路的两个重要侧面: 程序本身拥有更多控制权 和 函数式思维对数据结构的影响。
三 控制权转移--承担更多的运行时
1 你可能不太需要一个循环
编译期,或者部署期间(webpack),可以帮我们处理一些工作。比如发现部分代码错误和提高代码覆盖率,减少代码体积等。函数式语言并不排斥这些,多数函数式语言也并不是JS这样类型松散和解释型语言。
第二章中我们在说过程和高阶抽象时,提到系统更高效的表达。运行时可以帮我们承担语言中一些常见功能。
比如数组的循环操作,for(,,)的操作需要声明数组长度、底标的步进等内容,在做数组操作时是稍显繁琐的。map操作将数组当做集合处理,集合的边界本身作为集合的一个特性,在运行时限制了循环的界限。
作为另一种解决过程堆叠的方法,递归在运行时承担更多的内容。递归的终止条件根据上一层的返回结果确认,也就是说编码时我们只能给出终止条件,但执行次数不像拥有步进或枚举条件的循环一样一目了然。通过上篇文章中的尾递归和CPS我们可以看出,完善的递归会将函数的返回结果持续包装进新的递归方法中,反复进行调用。
递归在完成操作之前副作用最收敛,不依赖外部状态变化、内部消化条件,也就是说递归将状态的管理和转移 交付给运行时,是更接近底层级别的操作。不过递归的缺点也比较明显,更底层的操作对消耗资源的控制更难,控制不好会造成调用栈超限。
以上探讨了在解决某些集合操作时,综合考虑编码效率、稳定性来看,函数组合子 > 递归 > 循环; 其中在函数组合子和递归时都基于运行时承担了一些代码限制功能,迭代让位于了高阶函数/过程的调用。
用兴趣的同学可以研究没有锚点时的递归的等价描述,不动点和Y组合子,算是高阶函数的深度表现。
运行时还有个好处是,当处理的层次提高时,在运行时承载的工具方法并不需要多次编译(除非语法层面更改)。从语言层面我们能在运行时处理更高一级的过程抽象是非常有必要的。
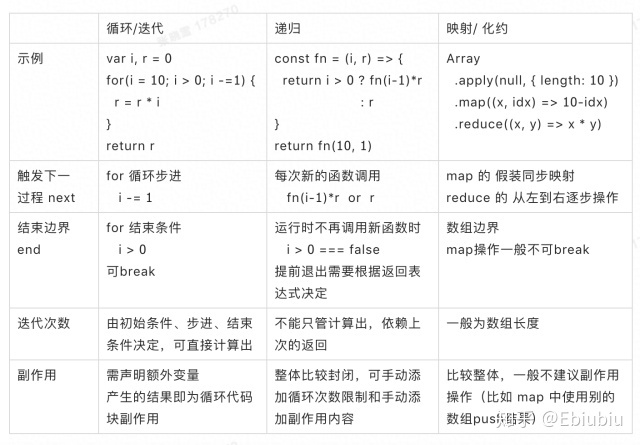
图六 循环、递归和映射
2 函数式过程抽象忽略的细节操作
为了更高效地处理核心逻辑,高级语言已经逐步包裹了繁琐的细节处理。比如Java之于C系语言,GC处理变得更可人。
代码运行场景中最核心的内容是 输入输出和调用消耗。在函数式的理想封装下,固定的输出得到固定的输出,我们就可以用输出对函数调用做等价转换。当我们不再关心封装黑盒内的细节时,针对结果我们可以做缓存记忆。这部分是关于过程抽象本身的细节封装。
当我们使用类型约束代码时,在类为主要结构的语言中,每次演进中类型的声明和推导(可能会是环境完成)都很重要。我们会依赖泛型来填补方法处理中的参数类型的不确定性。而从我们JS的角度考虑,或查看其它函数式语言,类型标识更多是对于函数方法的描述。我们最终的关注的类型描述表述为 f:: a -> b -> c -> a 的过程描述 和 参数a的类型描述。那么在过程中的类型细节也和过程抽象本身一样得到了封装。

图七 自动洗车机器 car -> cleanCar
除上面两点外,闭包、函数的部分施用等函数式特点,也将无用环境变量的回收时机、函数的调用时机(惰性调用)等交付给运行时。运行时和函数式语言特点的结合,可以帮我们屏蔽很多操作细节。
四 类型、数据结构和操作
本节我们探讨更多关于类型和数据结构的内容,它们是从结构上描述对象的核心概念。
传统命令式/面向对象的语言鼓励我们建立专门针对某个类的方法,而函数式鼓励在数据结构上使用共通的变换。在某些语言中对集合的映射处理上,我们可能在一类子类中实现map方法的接口; 而JS中,我们偏向于使用 Array.prototype.map,直接处理所有具备length属性和自然数下标的类数组鸭子类型(可以参考代码段一 中对range的实现)。
数据结构和类内部方法的绑定很重要,确保了方法调用时的合理性和精准度。在面向大规模系统时,良好的数据结构可以给与更强的约束;函数式的关注点在于操作过程和变化,它鼓励不通过数据结构,更多通过能力进行数据操作。
Haskell中有明确的类型类(typeclass)的概念,Int类是明确的 Eq(可判断相等)、Ord(可判断大小、排序)、Show(可转为字符串表述)的实例类型。这有些像Java中实现isEqual、和具备其他能力的接口; 更类似JS中的能力检测,根据判断给定的数据是否具备toString方法,来判定是否进行某些操作。
这里类型类或能力检测的概念,更方便我们跨越类型进行某些操作,比如基于Show类型类和 toString方法做全局的序列化等。
有种说法,100个函数操作一种数据结构的组合,好过10个函数操作10种数据结构。 我理解的是,在JS中,以具备某个属性、某种能力的函数内容来判断是否可进行某种操作,方便另一种约定——过程变量必须是某种数据结构、做数据结构的变化。
在函数式语言中,基于业务的数据结构更像是可以揉捏的单一结构体。
实际上,函数式语言中的数据结构和类型,会偏向于拥有编码上的某些能力,比如上面提到的可排序能力;以及包含集中叠加态,有分拆过程的能力的Maybe,Eighter等。
一个普通JS对象,可以通过表达式添加length方法和自然数keys形成事实上的数组对象;而基于类型和数据结构的语言就需要使用一个转换器。我们在后面的系列中会看到一个Just对象,也很容易通过增加flatMap方法形成事实上的Maybe对象。如果我们希望能灵活操纵过程,数据结构和类型上的分类和取舍就比较显著。
以上内容可以看出,函数式的语言思维中,我们的操纵比较细致,多是从某个实例对象的变化触发,我们从类型得到的最大好处是它的实例们统一的行为能力;
我们还会想到,在传统语言里,类型/Class带给我们的还有封装、复用和code时的检查。
事实上,函数闭包的特性可以帮我们快捷实现封装;函数自身的高阶调用可以便捷实现工厂方法和抽象工厂,结合一定的元编程能力就可以在生成过程中实现复用。
最后到出入参的约束问题。如果不考虑编译期间的类型检查,我们可以在函数组合的传入部分进行手动校验,手动进行类型的重载;过程中把异常态向后传导;结果处再进行检查。
这里可以看到,抛掉编译器检查,实际上我们完全可以按照需求自己对类型的作用进行补强。补强的经过会带来复杂度,但我们可以更关注编码时自己要什么和用什么。这其中我们可能要设计下调试姿势,来补充约束的能力。
代码二 深克隆方法,组合模式根据反射类型判断实现多态,根据闭包变量记录引用
function cloneDeep(target){
let copyed_objs = [];
const _cloneDeep = target => {
if (!target || (typeof target !== 'object')) {
return target;
}
for(let i= 0; i < copyed_objs.length; i += 1){
if(copyed_objs[i].target === target) {
return copyed_objs[i].copyTarget;
}
}
let obj = Array.isArray(target) ? [] : {};
copyed_objs.push({ target:target, copyTarget:obj});
Object.keys(target).forEach(_key => {
if(obj[_key]) { return; }
obj[_key] = _cloneDeep(target[_key]);
});
return obj;
}
return _cloneDeep(target);
}
函数式编程时,我们还是依赖于具体的函数式语言的语言特性:是动静态类型还是类型类,还是其他的灵活形式,来完成过程的切面操作。
我们可以看到函数式偏向于在代码的执行过程中操作对象,使用本身语言去迎合问题,通过重塑语言来解决问题,这样也更容易催生描述式风格的代码(声明式代码)。
编码中的问题我们其实有过一些总结:经典的设计模式、各语言的特性、和设计的结果 - 那些框架,我们接下来做些讨论。
五 设计模式、语言feature
设计模式可以看做赋予了名字的、编目记录下来的常见问题的解决方案。诞生之初的描述主要基于主流的命令式语言加以类为基础的封装模式。
在当前的前端繁杂的场景中,设计模式中的很多常用模型已经包含在语言feature和框架的实现中(单例: 有初始值的闭包元素)。结合JS的灵活的数据结构,还有一些设计模式会被简介地诠释。
访问者 Visitor 模式:
我对Visitor模式的理解是基于调用者的方法重载(编译时多态)。
在函数式语言中,我们遇到和命令式一样的问题,实际代码中虽然有些语言不方便重载,但根据具体访问者做Map处理即可。
组合 Composite 模式:
这里的组合模式指的不是函数式里面的函数组合,而是有包含或指向关系的节点和枝叶的共同操作,在业务中广泛应用在级联选择器或其他树结构的业务组件中。
如果我们使用对象直接操作,只要灵活地根据是否含有子节点或后续作出分支操作即可。
两种模式的JS代码都可以参考上面代码二深拷贝代码中的内容。
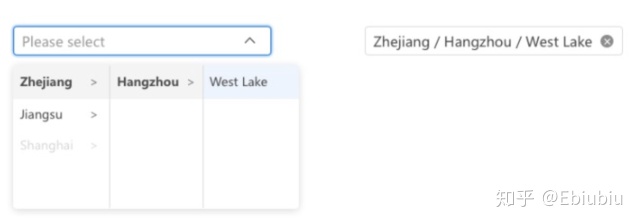
图八 级联选择器和访问者/组合模式
这些模式看起来处理有些随意,实际上能比较好地体现函数式对对象结构的方便操作。设计模式中有一个出发点是 合成复用原则,它同时是 开闭原则的提现,他们的宗旨是 使用组合和聚合 代替继承复用,来保持良好的封装性和减少新旧类的 耦合度,进而 保证良好的扩展和修改上的稳定性。
函数式的思想也偏向于对对象结构的扩展,结合上篇文章的提到的不可变数据结构,保持原型的结构,方便地实现缓存(备忘录 Memento)和其他行为。如果涉及到更多的时序和并发操作,不可变数据结构还是天生的线程安全。
在JS和很多语言里,函数以各种形式的第一公民形式存在;JS中函数更以对象的形态存在。我们对函数的抽象操作可以unlift 一级到对一个实例的操作。此时,我们可以在高级函数,甚至语言自身层面(自举、计时器模拟调度线程)调控我们的行为。这里我们需要解决一系列的问题: 占用的空间和运算资源、运行时错误、任务的调度等。
我们下节以异常态为例,看下函数式语言怎样自己再次对运行时进行包装。
六 异常态
一个良好的系统,除了会产生常态的错误信息(我们会有意识接住,并手动塞入报错信息的错误)外,还可能产生运行时的异常。我们经常看到的 Cannot read property 'f' of undefined 这种语法错误,多源于类型的约束缺失;其他常见的还有堆栈溢出,还有一些框架如react在做代码转换时的遇到的错误。
对于运行时才出现的错误(除了大范围的资源缺失外),我们使用函数式时的态度,更趋向于把错误当做正常态进行处理。可行性原因之一我们上面说过,基于过程的高阶抽象,我们可以包裹运行环境接住错误并处理成错误对象;动机之一是我们可以方便对错误进行传导、收集和改进。
异常态的处理有两种归宿,一是让它消失在catch后,另一种归宿是让他崩溃。大家日常写到的业务代码的崩溃代价不总是可控,有时仅影响一个代码块;但在当前框架层层包裹的情况下,更多情况是影响外层的更多功能,比如渲染白屏。我偏向JS更适合catch后接住错误,并进行收集的方式,或者至少在生产环境客户端需要这样。
除了使用装饰器代理等方法加入try...catch模块这类原始方法外,我们还会使用类似Maybe、Promise的reject的方法等。这些处理方式,是把代码的可行运行状态都进行封装,用事件流中的分支状态,来控制事件流中的成功、错误、迭代等状态。
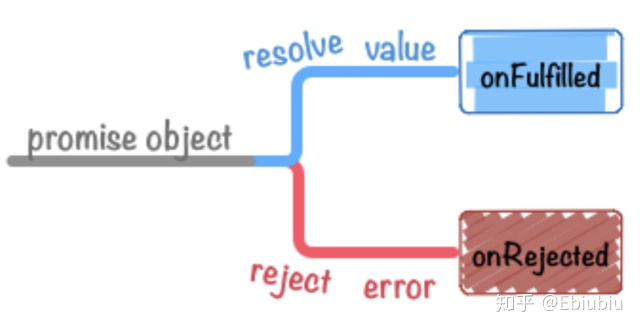
图九 Promise-error/reject
后面我们在演进的文章中继续讨论。
七 前端的其他特征
本篇的最后,我们讨论下前端的一些客观的特征,这些特征不一定关联函数式,但在我们设计工具和编码时常在一起考虑,也常被混淆。
事件驱动,手动处理并行操作,浏览器JS环境单线程,优秀的DSL:CSS和JSON等,这些都是前端在函数式上可以衍生自己特有工具和语法的一些特征。系列后面会从实用的角度再去分析这些内容。
在一些学习资料里面,大家会把前端的特性当做函数式的特性去和面向对象对比。首先面向对象和函数式的很多内容并不冲突,而前端的一些特性并非函数式的代表。
1 弱类型和动态类型
类型的处理上,很多设计之初考虑更多的语言都要求的更加严格,不管本身是偏函数式,还是多范式的语言。JS的弱类型和动态类型一开始的出发点在于提高这一脚本语言的开发和学习速度;在前端复杂度还不够高时,原生编码盛行,交互数据层级处理常常不当,此时JS的类型时而带来一些坑。
上面提到函数式语言的处理类型和数据结构时并没有指出JS类型的便利;总体上不管什么语言,涉及数据交互、参数类型多态时,都希望有明确的约束。
实际工作中,我们首先要明确不应该支持不显著的隐式转换(0+'' 这种处理还比较浅显易懂)和跨类型的值比较;其次,我们也不要排斥手动的类型转换和动态类型方便我们的一些操作,比如假值判断 (!(a); a || b )等。
在工具开发时,我们使用"==="带类型判等;在需要断言类型的时候,我们手动检校;而回到业务上,我们用对象表述复杂的数据类型,其对应的基本类型都是Object这个笼统的代名词。实际上我们对类型的要求完全可以按需操作。
类型对我们编码的影响主要还在于编码效率和系统健壮性的取舍。这点我偏向于编码效率,尤其在高度抽象过程的函数式中;我认为此处系统健壮性的缺失,更多是对编码设计理解的问题,可以通过更良好的设计、编码人员技术提升、和运行时的限制来解决。
2 Array的组合运算
Array的运算中,有一部分有明显的函数式风格,比如map/filter/reduce,常被作为函数式的典型用法。操作返回新的数组、支持链式操作,甚至还可以添加额外的字段完成被观察、或保存值以外的信息(比如错误值、或者Map结构的Key)。链式调用时默认this指向点操作符的左侧,也使得传入的方法方便支持箭头函数。
但首先Array的大多数运算是对传入值做处理、并不支持同级的链式操作这些特性的。比如常用的push、reverse等(可以使用concat等代替);其次Array作为JS常用类型,使用时是有时会受到JS便捷的重写原型方法的能力威胁,不过当代编辑器中存在lint等工具可以去约束。
Array可以模拟很多常用的基础数据结构,比如 Map、Linkedlist、多维数组/矩阵、简便的树结构等,这些结构出现在包括函数式的诸多基础开发汇总。它有比较好的扩展能力,这来自于JS设计时自身对集合结构的简单抽象。
图十 JS中Array承担了集合的概念
小结
到这里我们已经赘述了很多前端和函数式思维内容。从系统中状态、过程,到运行时承担的更多内容、类型和数据结构,然后到具体的编码设计、异常态的改变和前端的其他特征。本文中的内容比较宽泛,有很多内容可能一段时间后我也会有新的理解。
语言范式和它背后的编程思维,在经历过理论完善到相关语言的诞生、再到持续满足于具体领域的工程化需求后,已经融合了很多内容,不是很理想化但是很实用。我也只能从前端的视角片面地观察它。
可能talk is cheap,下章开始我会从函数式编码Monadic 来揭开函数式工具和编码方式在前端的具体演进,期待大家指正。附:推荐《函数式编程思维》图灵书,文中有些内容来自本书的消化。
需要留意此书基于的语言是Java虚拟机上的几种语言,且有些函数式特性的分析来自一些语言的具体实现。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









