





1. 三件套简介
- hdfs:用于存储大数据的分布式文件系统,在hadoop当中是充当存储的角色。
- mapreduce:分布式计算框架,是用于计算的,分为map端和reduce端。
- yarn:资源调度器,其负责资源和作业的调度管理,毕竟几十台机子,数据和计算的节点也不一定在同一个地方,所以需要协调执行的过程。
2. 安装配置jdk、hosts、ssh
1)安装配置jdk
就在/usr/java这个目录下安装。一般的linux系统都是自带java的,但可能版本不够新的原因我们会重新安装一个java,这次我们安装的jdk1.8。同时,因为/usr/目录下没有java这个目录,所以我们也手动创建一个。
mkdir -p /usr/java
[root@JD /]# cd /usr/java
[root@JD java]# ll
total 355840
drwxr-xr-x 8 root root 4096 Nov 17 00:24 jdk1.8.0_121
-rw-r--r-- 1 root root 191100510 Nov 14 01:25 jdk1.8.0_121.zip
-rw-r--r-- 1 root root 173271626 Nov 28 14:13 jdk-8u45-linux-x64.gz
#解压
[root@JD java]# tar -zxvf jdk-8u45-linux-x64.gz这个地方有一个小坑的,就是解压后的jdk的用户和用户组有点问题,我们需要修改一下。
#修正用户和用户组权限
[root@JD java]# chown -R root:root jdk1.8.0_45
[root@JD java]# ll
total 355844
drwxr-xr-x 8 root root 4096 Apr 11 2015 jdk1.8.0_45
-rw-r--r-- 1 root root 173271626 Nov 28 14:13 jdk-8u45-linux-x64.gz2)JAVA_HOME 显性配置
配置java的环境变量,使用全局配置文件
vi /etc/profile #进入到编辑模式
export JAVA_HOME=/usr/java/jdk1.8.0_45
export PATH=$JAVA_HOME/bin:$PATH
:wq
#使环境变量生效
[root@JD java]# source /etc/profile
#查看是否生效
[root@JD java]# which java
/usr/java/jdk1.8.0_45/bin/java配置hosts
#前两行系统自带的千万不要删
[root@JD java]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.0.3 JD3)配置ssh
使用root用户配置ssh时,不需要给authorized_keys赋权限;使用非root用户配置ssh时,必须要给authorized_keys赋0600权限,否则配置的ssh不生效。
创建用户
#创建用户
[root@JD /]# useradd hadoop
[root@JD /]# id hadoop
uid=1002(hadoop) gid=1003(hadoop) groups=1003(hadoop)
#切换用户
[root@JD ~]# su - hadoop
Last failed login: Thu Nov 28 12:17:14 CST 2019 from 40.76.65.78 on ssh:notty
There were 114 failed login attempts since the last successful login.
[hadoop@JD ~]$ pwd
/home/hadoop生成公私钥
[hadoop@JD ~]$ ssh-keygen
#查看隐藏文件
[hadoop@JD ~]$ ll -a
total 12
drwx------ 3 hadoop hadoop 70 Nov 28 15:30 .
drwxr-xr-x. 5 root root 43 Nov 28 15:08 ..
-rw-r--r-- 1 hadoop hadoop 18 Apr 11 2018 .bash_logout
-rw-r--r-- 1 hadoop hadoop 193 Apr 11 2018 .bash_profile
-rw-r--r-- 1 hadoop hadoop 231 Apr 11 2018 .bashrc
drwx------ 2 hadoop hadoop 36 Nov 28 15:30 .ssh
#进入.ssh文件
[hadoop@JD ~]$ cd .ssh
查看生成的公私钥
[hadoop@JD .ssh]$ ll
total 8
-rw------- 1 hadoop hadoop 1675 Nov 28 15:30 id_rsa
-rw-r--r-- 1 hadoop hadoop 391 Nov 28 15:30 id_rsa.pub
#将公钥放置到对方机器的用户目录下
[hadoop@JD .ssh]$ cat id_rsa.pub >> authorized_keys
[hadoop@JD .ssh]$ ll
total 12
-rw-rw-r-- 1 hadoop hadoop 391 Nov 28 15:32 authorized_keys
-rw------- 1 hadoop hadoop 1675 Nov 28 15:30 id_rsa
-rw-r--r-- 1 hadoop hadoop 391 Nov 28 15:30 id_rsa.pub测试ssh
还是需要输入密码,也就没生效,因为是非root用户,需要给authorized_keys赋0600权限
[hadoop@JD .ssh]$ ssh JD date
The authenticity of host 'jd (192.168.0.3)' can't be established.
ECDSA key fingerprint is SHA256:OLqoaMxlGFbCq4sC9pYgF+FdbcXHbEbtSrnMiGGFbVw.
ECDSA key fingerprint is MD5:d3:5b:4a:ef:8e:00:41:a0:5e:80:ef:75:76:8a:a3:49.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'jd,192.168.0.3' (ECDSA) to the list of known hosts.
hadoop@jd's password:
#赋0600权限
[hadoop@JD .ssh]$ chmod 0600 authorized_keys
#测试ssh,成功
[hadoop@JD .ssh]$ ssh JD date
Thu Nov 28 15:37:31 CST 20193. hdfs的伪分布式部署
3.1 修改用户、用户组
[root@JD /]# ll
total 522100
-rw-r--r-- 1 root root 434354462 Nov 28 14:15 hadoop-2.6.0-cdh5.16.2.tar.gz
[root@JD /]# mv hadoop-2.6.0-cdh5.16.2.tar.gz /home/hadoop/software/
#修改用户用户组
[root@JD /]# chown hadoop:hadoop /home/hadoop/software/*
#查看是否修改成功
[root@JD /]# ll /home/hadoop/software
total 424176
-rw-r--r-- 1 hadoop hadoop 434354462 Nov 28 14:15 hadoop-2.6.0-cdh5.16.2.tar.gz3.2 创建文件夹并解压tar包
#切换hadoop用户
[root@JD ~]# su - hadoop
#创建文件夹
[hadoop@JD ~]$ mkdir app software data sourcecode log tmp lib
[hadoop@JD ~]$ ll
total 0
drwxrwxr-x 2 hadoop hadoop 6 Nov 28 17:20 app #解压的文件夹 软连接
drwxrwxr-x 2 hadoop hadoop 6 Nov 28 17:20 data #存放数据
drwxrwxr-x 2 hadoop hadoop 6 Nov 28 17:20 lib #存放第三方jar
drwxrwxr-x 2 hadoop hadoop 6 Nov 28 17:20 log #存放日志文件
drwxrwxr-x 2 hadoop hadoop 6 Nov 28 17:20 software #存放tar包
drwxrwxr-x 2 hadoop hadoop 6 Nov 28 17:20 sourcecode#源代码编译
drwxrwxr-x 2 hadoop hadoop 6 Nov 28 17:20 tmp #临时文件
#解压tar包
[hadoop@JD software]$ tar -zxvf hadoop-2.6.0-cdh5.16.2.tar.gz -C ../app/
[hadoop@JD software]$ cd ../app
[hadoop@JD app]$ ll
total 4
drwxr-xr-x 14 hadoop hadoop 4096 Jun 3 19:11 hadoop-2.6.0-cdh5.16.2
#建立软连接
[hadoop@JD app]$ ln -s hadoop-2.6.0-cdh5.16.2 hadoop
[hadoop@JD app]$ ll
total 4
lrwxrwxrwx 1 hadoop hadoop 22 Nov 28 17:32 hadoop -> hadoop-2.6.0-cdh5.16.2
drwxr-xr-x 14 hadoop hadoop 4096 Jun 3 19:11 hadoop-2.6.0-cdh5.16.23.3 修改hadoop的配置文件
到/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop这个目录下,把hadoop-env.sh,core-site.xml和hdfs-site.xml这三个配置文件修改了,具体如下:
hadoop-env.sh文件
export JAVA_HOME=你java的安装目录 #这里就是告诉hadoop你的java在哪里
export HADOOP_PREFIX=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0 #这里是明确hadoop的安装目录,也可以不写
[hadoop@JD app]$ cd hadoop/etc/hadoop/
[hadoop@JD hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_45core-site.xml文件
#将<configuraiong></configuration>这个删了,把我这个copy上去就好了
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:9000</value>
</property>
</configuration>
#注意这里的hadoop001是我的主机hostname,你要把你的hostname写上去,至于端口号就不用改了hdfs-site.xml文件
#将<configuraiong></configuration>这个删了,把我这个copy上去就好了
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
#就是说将副本系数标志成1。3.4 配置hadoop的个人环境变量
#配置hadoop的环境变量,一般就在hadoop这个用户的个人环境变量文件中配就行了。
[hadoop@JD ~]$ pwd
/home/hadoop
#编辑.bashrc文件,配置hadoop环境变量
[hadoop@JD ~]$ vi .bashrc
export HADOOP_HOME=/home/hadoop/app/hadoop
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
#使环境变量生效
[hadoop@JD ~]$ source .bashrc
#查看是否生效
[hadoop@JD ~]$ which hadoop
~/app/hadoop/bin/hadoop
#格式化(看到successfully成功)
[hadoop@JD ~]$ hdfs namenode -format
INFO common.Storage: Storage directory /tmp/hadoop-hadoop/dfs/name has been successfully formatted.3.4 ssh无密码登陆
#如果是初次使用的话就直接在hadoop的家目录上输入命令:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa,
#如果不是的话就rm -rf .ssh 将这个文件夹删除再输入前面的命令。
#然后 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys,
将你本机的公钥放到 ~/.ssh/authorized_keys这个文件里面,
在本机ssh你的本机,如果可以无密码登陆就ok了。
#这个.ssh文件夹下的情况:
total 12
-rw-rw-r-- 1 hadoop hadoop 606 Sep 19 23:16 authorized_keys
-rw------- 1 hadoop hadoop 668 Sep 19 23:16 id_dsa
-rw-r--r-- 1 hadoop hadoop 606 Sep 19 23:16 id_dsa.pub4. 初始化并启动hdfs
- 切换到/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/bin下,输入命令hdfs namenode -format来初始化你的namenode节点。
- 切换到/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/sbin下,输入命令./start-dfs.sh,看到这样的输入就是对的了:【此节为使用之前版本的内容】
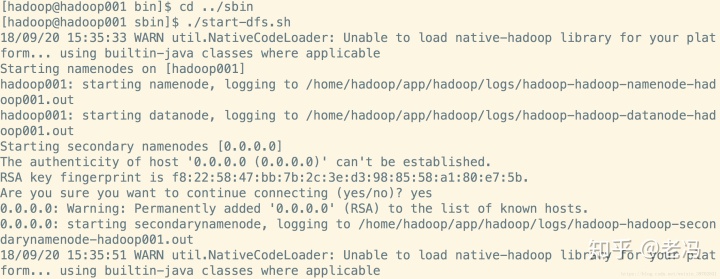
注意图片中已经将hadoop-2.6.0-cdh5.7.0重命名为hadoop了,所以路径名称上有所不同。
然后输入命令jps来查看进程,这个查看进程和ps -ef有什么区别呢?jps是用来查看与java有关的进程的,要是用ps -ef 也是可以查看到hadoop相关的进程的,就是太多了不好找。

这样就好了,然后我们可以在web浏览器中输入主机的ip或者hostname加端口号50070来查看hadoop的overview
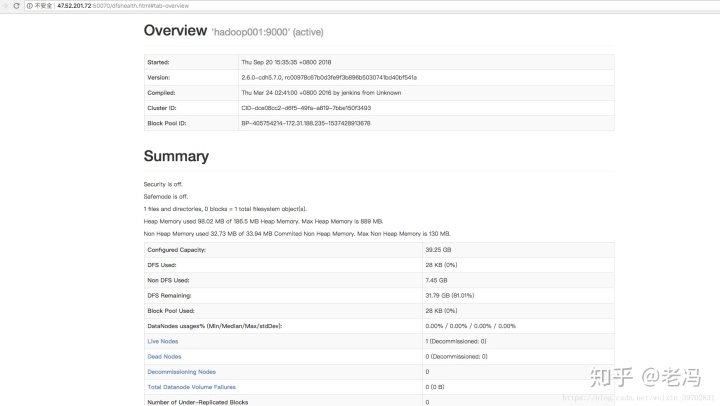
1)坑:第一次启动会输入yes确定信任关系,我们打开./ssh下的known_hosts文件,这个文件中存放信任关系。将来也许在启动hadoop的时候一直要输入密码,就是这里面已经存在了主机的信任关系,但是密匙对是新的。
2)配置DN SNN都以 JD启动
- namenode 名称节点 老大 读写请求先经过它 主节点
- datanode 数据节点 小弟 存储数据 检索数据 从节点
- secondarynamenode 第二名称节点 老二 h+1
NN: JD fs.defaultFS控制的在core-site.xml文件中
DN: slaves文件配置
SNN: hdfs-site.xml文件配置
[hadoop@JD hadoop]$ pwd
/home/hadoop/app/hadoop/etc/hadoop
#删除localhost,替换为JD
[hadoop@JD hadoop]$ vi slaves
JD
#添加属性
[hadoop@JD hadoop]$ vi hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>JD:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>JD:50091</value>
</property>
#重新启动,都是使用JD启动,并且不用输入yes,jps发现进程都起来了,成功
[hadoop@JD ~]$ start-dfs.sh
[hadoop@JD ~]$ jps5. hadoop fs的常规命令
1)创建文件
[hadoop@JD ~]$ echo "111111" > aaa.txt
[hadoop@JD ~]$ ll
total 4
-rw-rw-r-- 1 hadoop hadoop 7 Nov 28 22:06 aaa.txt
2)上传文件
[hadoop@JD ~]$ hadoop fs -put aaa.txt /
查看文件或文件夹
[hadoop@JD ~]$ hadoop fs -ls /
-rw-r--r-- 1 hadoop supergroup 7 2019-11-28 22:07 /aaa.txt
3)创建文件夹
[hadoop@JD ~]$ hadoop fs -mkdir /bigdata
[hadoop@JD ~]$ hadoop fs -ls /
-rw-r--r-- 1 hadoop supergroup 7 2019-11-28 22:07 /aaa.txt
drwxr-xr-x - hadoop supergroup 0 2019-11-28 22:11 /bigdata
4)下载文件
[hadoop@JD ~]$ hadoop fs -get /aaa.txt
5)删除文件
[hadoop@JD ~]$ hadoop fs -rm /aaa.txt
[hadoop@JD ~]$ hadoop fs -ls /
drwxr-xr-x - hadoop supergroup 0 2019-11-28 22:11 /bigdata














 6587
6587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









