





算法训练函数的选取
算法的性能与训练函数的选取有着显著的影响。为了分析并选取合适的参数以及BP神经网络的训练函数,本次实验选取Sphere函数对遗传算法优化的BP神经网络算法进行测试分析,以获得较合理的训练函数。其中实验环境同本章第2节。
(1)实验数据:本节利用 Sphere 函数随机抽取 5000 组值,其中前 4900 组值用于训练,后 100 组值用于预测,实验中函数取值范围及维数同上。
(2)遗传算法优化的 BP 神经网络拓扑结构:在本章第2节中我们实验选取了贝叶斯正则化法和 L-M 优化法,根据遗传算法优化的 BP 神经网络算法流程图可知,在 BP权值和阈值初始化时以及样本训练时都需确定 BP 神经网络的训练函数,因此本文提出的遗传算法优化 BP 神经网络算法模型共四种,即:
模型 ①:初始权值和阈值——L-M 优化法,网络训练——L-M 优化法;
模型 ②:初始权值和阈值——L-M 优化法,网络训练——贝叶斯正则化法;
模型 ③:初始权值和阈值——贝叶斯正则化法,网络训练——L-M 优化法;
模型 ④:初始权值和阈值——贝叶斯正则化法,网络训练——贝叶斯正则化法。
(3)参数设定:遗传算法的遗传代数设为 100 代,种群规模为 10,交叉概率为 0.8,变异概率为 0.09,BP 神经网络结构为 9-14-1,设定学习速率为 0.1,训练精度为 10-6,最大训练次数为 10000 次。
(4)实验仿真:
表1 遗传算法优化的 BP 算法中不同训练函数对 Sphere 函数预测结果对比

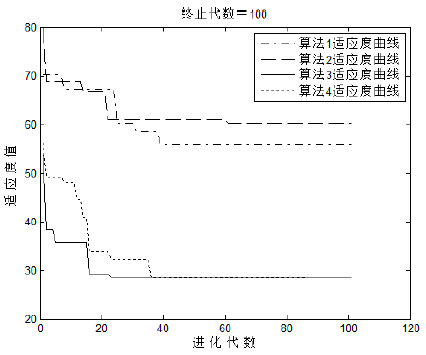
图1 四种算法适应度曲线
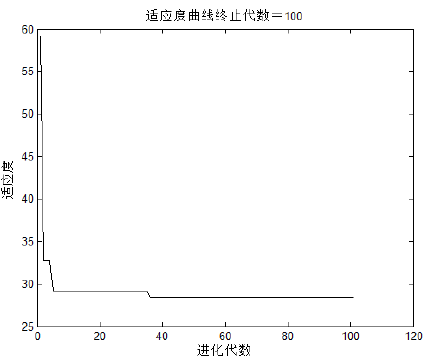
图2 算法④适应度曲线(最大训练次数 300)
(5)结果分析: 从图1中可以看出,这四种算法在40代以前基本达到了其最佳适应度,而模型③和模型④的算法效果更佳,说明在对BP神经网络的权值和阈值进行初始化时选用贝叶斯正则化法效果较好,这样可以获得最佳适应度值。 从表1中可以直观的看出,模型②和模型④的算法预测性能较好,其方差和相对误差范围相比其他两种算法较小,但模型②算法的收敛精度偏大。为了避免算法因偶然性而得到的较好的预测结果,本人经过反复测试,虽然是同一算法,同一组测试数据,但每次运行时的训练次数都不同,特别是模型②和模型④算法的训练次数甚至达到了设定的终止训练次数,即1000次。 综合以上分析以及本人对算法的反复测试验证,选用模型④较为理想。首先,该算法的预测效果相对较好;其次,该算法的适应度曲线较好,最多进化到40代附近就能达到最佳适应度值,虽然图1中显示模型③适应度曲线最好,但最终在40代左右模型③和模型④达到了接近的最佳适应度,这是因为这两者选用的训练函数是相同的,而图中产生差异的原因是其算法的随进性本质所导致的,同时这也说明了该算法的可靠性,即该算法运行多次都能达到最佳适应度值。除了上述两个优点之外,还有一个缺点,即模型④训练次数相比之下过多,本人经过多次运行后发现,有时甚至达到所设定的最大训练次数值,为了解决这一问题,在其它参数不变的情况下,把训练次数设定为300,其运行结果为:训练次数300次,收敛精度3.6×10-3,方差5.1×103,相对误差(-1.1, 0.4);适应度曲线如图2所示。其预测效果相对较好,如果需要更高预测精度,可以适当增加训练次数。为了能发挥该算法的最优性能,下面对其参数遗传算法部分的参数进行探讨。
《来源于科技文献,经本人分析整理,以技术会友,广交天下朋友》














 2956
2956











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









