





#0
今天的主题是反射。反射是属于Java语言的一项高级特性,在初学反射特性的时候,总是会提到运行时云云。但自己并不能理解这些学院气息浓厚的术语,最终也只能这么理解:
- 我能够获取一个class的Class对象,及其Field(属性)、Method(方法)、Constructor(构造器)
- 我能够利用反射特性构造实例
这种理解方式只能记住「反射能做什么」,但是却无法回答「反射存在的意义」。后面这个问题,才是掌握反射特性的关键所在。因此,今天的文章将首先回答「为什么需要反射」,然后再详细说明「反射能做什么」,最终将从源码层面说明「为了实现反射特性究竟做了哪些工作」。
老规矩,先上图。
#1
使用Java语言编写程序时,从在IDE敲代码开始到程序运行为止,大致上会经历三个阶段。
- 编写
- 这个过程就是各位在IDE环境下敲代码的过程,敲出来的是.java文件
- 编译
- JVM负责将.java文件编译成.class文件
- 运行
- JVM将.class文件加载进虚拟机并运行
所谓的运行时就是指上述的第三个阶段。在这个阶段,程序已经不受程序员的控制,它只会按照代码里面的逻辑运行。假设,你正在开发程序,你希望它能够在「运行时」能够从磁盘文件或者网络连接中获取一串字节,并根据获取的字节生成一个对象。这个时候,如果没有反射机制,那么这个功能就无法实现。
在Java源码阅读(十)——Class(一)介绍的newInstance()中提到的.class文件就是上述提到的从磁盘文件或网络连接中获取的一串字节。
反射的这些用途在编写业务代码时候还体会不到,但是在编写通用框架的时候,没有反射特性寸步难行。举一个简单的例子,Spring中的@RequestBody注解就可以读取前端传入的参数(即从网络连接中获取的字节)并构造对应POJO的实例。
#10
结合.class文件的格式,在不考虑内部类的情况下,普通类的组成部分如下
标识符 类名 接口集合{
// 字段
// 构造函数
// 方法
}
根据官方的解释,反射特性提供以下功能
- 在运行时判断任意一个对象所属的类
- 在运行时构造任意一个类的对象(即调用构造函数)
- 在运行时判断任意一个类所具有的成员变量和方法(通过反射设置可以调用 private)
- 在运行时调用一个对象的方法
在介绍反射特性的使用时,将分为两个部分介绍。
- 第一个部分是与Class对象相关的,包括
- 获取Class对象
- 判断是否为某个类的实例
- 创建实例
- 第二个部分是与Field、Method和Constructor有关的
- 这里只涉及如何获取Field、Method和Constructor
Class
获取Class对象有三种方法
// 1、使用Class类的forName()静态方法
// 这个最常见,加载Mysql的驱动就是用这个方法
Class.forName("com.mysql.jdbc.Driver")
// 2、调用某个对象的getClass()
String str = new String("str");
Class> clazz = str.getClass();
// 3、直接获取某一个Class的class
Class> class = String.class;
通过isInstance()判断当前对象是否是某个类的实例
public native boolean isInstance(Object obj);
通过反射来生成对象主要有两种方式。
Constructor
先通过 Class 对象获取指定的 Constructor 对象,在调用 Constructor 对象的 newInstance() 方法来创建实例。这种方法可以用指定的构造器构造类的实例。
// 获取String所对应的Class对象
Class> c = String.class;
// 获取String类带一个String参数的构造器
Constructor constructor = c.getConstructor(String.class);
// 根据构造器创建实例
Object obj = constructor.newInstance("str");
newInstance
使用 Class 对象的 newInstance() 方法来创建对象对应类的实例。
Class> c = String.calss;
Object str = c.newInstance();
实际上是获取默认的无参构造函数,然后通过无参构造函数的newInstance()方法来创建的实例。
FMC
FMC是我对Fields、Method、Constructor的合并简称,在Class类中,这三个涉及到的源码逻辑十分相似,因此这里以Field为例,说明在Class类内部相关的源码逻辑。
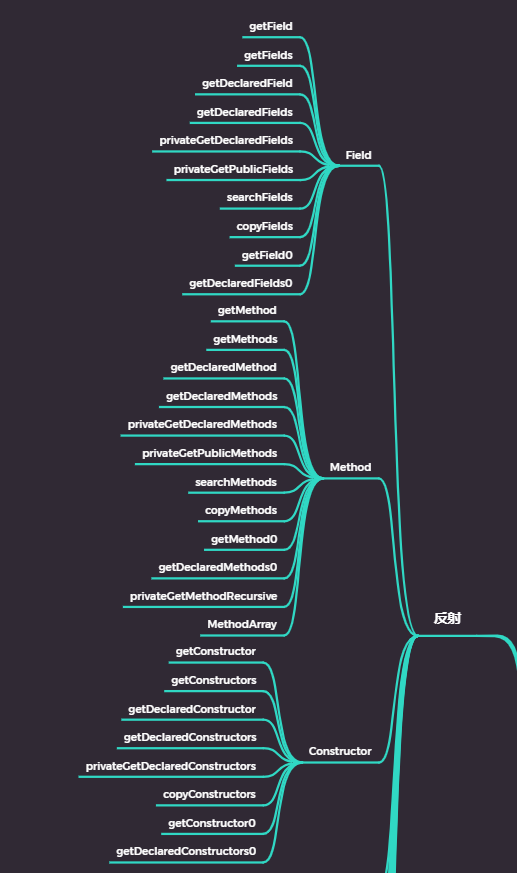
相比之下,Method方面多了privateGetMethodRecursive()和MethodArray
Constructor方面少了searchConstructors()和privateGetPublicConstructors()
这些存在差异的地方我会在最后会单独说明。
反射特性最基础的作用就是获取Field,以getField为例子,获取Field一共有三个步骤
- 检查权限
- 获取
- 复制
public Field getField(String name)throws NoSuchFieldException, SecurityException {
// 检查权限
checkMemberAccess(Member.PUBLIC, Reflection.getCallerClass(), true);
// 获取并复制
Field field = getField0(name);
if (field == null) {
throw new NoSuchFieldException(name);
}
// 返回
return field;
}
检查权限
在获取Field之前,需要检查访问权限。checkMemberAccess()会根据当前类的ClassLoader和调用类的ClassLoader进行判断,当两个ClassLoader不相同,那么需要借助SecurityManager的checkPermission进行判断。判断完毕后,还需要进行包访问权限的判断。
private void checkMemberAccess(int which, Class> caller, boolean checkProxyInterfaces) {
final SecurityManager s = System.getSecurityManager();
if (s != null) {
final ClassLoader ccl = ClassLoader.getClassLoader(caller);
final ClassLoader cl = getClassLoader0();
if (which != Member.PUBLIC) {
if (ccl != cl) {
// 检查是否可以访问对象成员
s.checkPermission(SecurityConstants.CHECK_MEMBER_ACCESS_PERMISSION);
}
}
// 检查包访问权限
this.checkPackageAccess(ccl, checkProxyInterfaces);
}
}
这些访问控制权限检查的方法(包括checkPackageAccess和checkMemberAccess)只需要知道目前的作用就可以了,要弄明白这些方法的实现原理需要额外知识,而且现在是在做反射特性的讲解,一头扎进去会陷入只见树木不见森林的陷阱,并不利于我们学习反射特性,因此这里暂时就到这个层面。
获取与复制
getField()通过getField0()获取.class文件的Field信息。简单来说这个方法分为三个部分
- 从当前Class定义的public的字段中查找。如果没有找到,则进行下一步
- 递归地对其接口调用
getField0进行字段查找。如果没有找到,则进行下一步。 - 递归地对其父类调用
getField0进行字段查找。如果没有找到,则进行下一步。
private Field getField0(String name) throws NoSuchFieldException {
Field res;
// 获取当前类,被声明为public的Field
if ((res = searchFields(privateGetDeclaredFields(true), name)) != null) {
return res;
}
// 递归的获取其接口所声明的Field
Class>[] interfaces = getInterfaces();
for (int i = 0; i Class> c = interfaces[i];
if ((res = c.getField0(name)) != null) {
return res;
}
}
// 递归获取其父类声明的Field
if (!isInterface()) {
Class> c = getSuperclass();
if (c != null) {
if ((res = c.getField0(name)) != null) {
return res;
}
}
}
return null;
}
抛开其他逻辑,这段代码的关键逻辑是res = searchFields(privateGetDeclaredFields(true), name)。
其中privateGetDeclaredFields将会获取当前类所有声明的Field,根据参数publicOnly判断是否只返回public的。
而searchFields将会在传入的参数fields中寻找以name为属性名的Field。
privateGetDeclaredFields的逻辑也分为三个部分
- 检查初始化情况
- 从反射缓存中获取
- 如果没有缓存,那么通过虚拟机获取,并设置缓存
因为反射会造成性能的降低,其原因是通过JVM的native方法从.class文件中获取对应的数据再生成对应的对象。
为了尽最大可能降低性能降低造成的负面影响,因此在Class类中声明内部类ReflectionData用于缓存反射数据。
比如rd.declaredPublicFields就是缓存的已声明的public属性。
private Field[] privateGetDeclaredFields(boolean publicOnly) {
// 检查初始化情况
checkInitted();
// 从缓存中获取Field
Field[] res;
ReflectionData rd = reflectionData();if (rd != null) {
res = publicOnly ? rd.declaredPublicFields : rd.declaredFields;if (res != null) return res;
}// 如果缓存数据为空,那么通过虚拟机进行调用
res = Reflection.filterFields(this, getDeclaredFields0(publicOnly));if (rd != null) {// 根据传入的参数决定设置哪个缓存if (publicOnly) {
rd.declaredPublicFields = res;
} else {
rd.declaredFields = res;
}
}return res;
}为了降低反射带来的性能消耗,Class类中运用了很多方法,作为Class内部类的ReflectionData就是其中一个方法。
除此之外,在searchFields中也有一小部分性能优化。这个性能优化是借助JVM内存结构中的字符串常量池来实现的,通过String.intern()手动将通过反射获取字段名称加入常量池,这样在后续反射时就能够直接通过常量池中的字符串进行比较,从而省去了在堆中创建字符串对象的时间。
private static Field searchFields(Field[] fields, String name) {
// intern()方法是一种手动将字符串加入常量池中的方法
// 适用于只有有限值,并且这些有限值会被重复利用的场景
// Class的属性名完美符合要求
String internedName = name.intern();
for (int i = 0; i if (fields[i].getName() == internedName) {
// 最终是使用newInstance构造了新的实例
// 并不会真正返回通过VM获取的实例
return getReflectionFactory().copyField(fields[i]);
}
}
return null;
}
ReflectionData
ReflectionData是Class类中用户缓存反射数据的一个内部类,其缓存内容与反射特性提供的接口一一对应。
包括
- 声明的[字段(Field)|方法(Method)|构造器(Constructor)],不包括父类的
- public的[字段(Field)|方法(Method)|构造器(Constructor)],包括父类的
- 声明的public的[字段(Field)|方法(Method)],不包括父类的[字段(Field)|方法(Method)]
- 接口数组
ReflectionData的定义
private static class ReflectionData<T> {
volatile Field[] declaredFields;
volatile Field[] publicFields;
volatile Method[] declaredMethods;
volatile Method[] publicMethods;
volatile Constructor[] declaredConstructors;volatile Constructor[] publicConstructors;// Intermediate results for getFields and getMethodsvolatile Field[] declaredPublicFields;volatile Method[] declaredPublicMethods;volatile Class>[] interfaces;// Value of classRedefinedCount when we created this ReflectionData instancefinal int redefinedCount;
ReflectionData(int redefinedCount) {this.redefinedCount = redefinedCount;
}
}上面就是ReflectionData类的定义,每个声明的属性都是volatile的,目的是在多线程环境下保持各个属性的可见性。
为了能让ReflectionData更好地发挥其作为缓存的作用,Class类中还有定义了其他的字段和方法进行支持。
ReflectionData的辅助字段
// 是否使用反射缓存的开关字段
private static boolean useCaches = true;
// 计数器
private volatile transient int classRedefinedCount = 0;
第一个字段「useCaches」见名知意,很好理解。
第二个字段「classRedefinedCount」展开来的话又是一个很大的话题,这里简单的说一下,这个字段的目的是统计Class被重新定义的次数。
作为Java语言的开发都知道对象行为(方法、函数)是存储在方法区的。
那么方法区中的数据从哪来的?答案是,方法区中的数据是类加载时从class文件中提取出来的。
那么class文件从哪来的?答案是,从Java或者其他符合JVM规范的源代码中编译而来。
那么源代码从哪来的?废话,当然是手写!
没错,归根结底,源代码都是手写的。
但是考虑到一个场景:当在开发Java应用时,一旦代码有任何更新,都需要将正在运行的程序停下来,重新走一次「编写-编译-运行」的流程。
有人会说了,现在不用这么费时费力的方式,通过热部署的方式,代码修改即见效。同样的思想也运用在使用Vue或者React进行前端应用编写的时候。那么在Java中实现热部署的原理是什么呢?
通过调用java.lang.instrument.Instrumentation提供的redefineClasses能够将自己提供字节码文件替换掉已存在的class文件
通过这种方式实现热部署,而classRedefinedCount会在调用redefineClasses后增加次数用以记录。
记录调用redefineClasses重新定义.class文件次数的目的是:当重新定义.class原有的缓存数据ReflectionData可能会失效。一旦失效,那么缓存数据就应当重新定义。
ReflectionData的使用
reflectionData被定义为一个软引用,并且reflectionData会等到第一次执行相关反射操作时才会创建。
// 软引用
private volatile transient SoftReference> reflectionData;// 延迟加载private ReflectionData reflectionData() {
SoftReference> reflectionData = this.reflectionData;int classRedefinedCount = this.classRedefinedCount;
ReflectionData rd;// 返回条件有以下几个// 1.打开缓存开关// 2.软引用reflectionData不为空// 3.软引用中的ReflectionData实例不为空// 4.ReflectionData实例中记录的redefinedCount与classRedefinedCount相等if (useCaches &&
reflectionData != null &&
(rd = reflectionData.get()) != null &&
rd.redefinedCount == classRedefinedCount) {return rd;
}return newReflectionData(reflectionData, classRedefinedCount);
}当软引用被JVM回收或者旧缓存数据失效了,会调用newReflectionData创建新的缓存数据。
// 创建新的ReflectionData
private ReflectionData newReflectionData(SoftReference> oldReflectionData,int classRedefinedCount) {
if (!useCaches) return null;
while (true) {
// 根据新的记录次数创建新的缓存数据
ReflectionData rd = new ReflectionData<>(classRedefinedCount);// 使用CAS的方式,将旧的缓存数据复制到新缓存的软引用上。if (Atomic.casReflectionData(this, oldReflectionData, new SoftReference<>(rd))) {return rd;
}// 如果CAS失败,那么将旧数据保留以准备下次的CAS
oldReflectionData = this.reflectionData;
classRedefinedCount = this.classRedefinedCount;// 如果其他的线程已经成功将旧的缓存数据更新,那么直接返回if (oldReflectionData != null &&
(rd = oldReflectionData.get()) != null &&
rd.redefinedCount == classRedefinedCount) {return rd;
}
}
}其他
上面是以getField(String name)作为示例说明反射特性的逻辑。其他的方法大同小异,差别在于目的不同。
- getField(String name)
- 获取以name命名的public字段,当前类若无定义则从其直接父类和直接接口中寻找
- getFields
- 获取所有的public字段,包括当前类、直接父类和直接接口中定义的
- getDeclaredField(String name)
- 获取以name命名的字段,从当前类中寻找
#11
这部分将对Method和Constructor中存在差别的部分进行说明
Method
通过反射获取对应Method在具体实现上和Field有不小的区别,以getMethod(String name, Class>... parameterTypes)为例,由于方法重载特性的存在,除了name以外还需要提供方法参数列表parameterTypes。
public Method getMethod(String name, Class>... parameterTypes)throws NoSuchMethodException, SecurityException {
// 检查权限
checkMemberAccess(Member.PUBLIC, Reflection.getCallerClass(), true);
// 获取并复制
Method method = getMethod0(name, parameterTypes, true);
if (method == null) {
throw new NoSuchMethodException(getName() + "." + name + argumentTypesToString(parameterTypes));
}
return method;
}
private Method getMethod0(String name, Class>[] parameterTypes, boolean includeStaticMethods) {
MethodArray interfaceCandidates = new MethodArray(2);
Method res = privateGetMethodRecursive(name, parameterTypes, includeStaticMethods, interfaceCandidates);
if (res != null)
return res;
// Not found on class or superclass directly
interfaceCandidates.removeLessSpecifics();
return interfaceCandidates.getFirst(); // may be null
}
可以看到获取Method的方法getMethod0与获取Field的方法getField0的区别在于「interfaceCandidates」。
private Method privateGetMethodRecursive(String name,
Class>[] parameterTypes,boolean includeStaticMethods,
MethodArray allInterfaceCandidates) {
Method res;
// Search declared public methods
if ((res = searchMethods(privateGetDeclaredMethods(true),
name,
parameterTypes)) != null) {
// 对于静态方法的额外处理
if (includeStaticMethods || !Modifier.isStatic(res.getModifiers()))
return res;
}
// 其他都差不多,比如从直接父类和直接实现的接口中寻找
if (!isInterface()) {
Class super T> c = getSuperclass();
if (c != null) {
if ((res = c.getMethod0(name, parameterTypes, true)) != null) {
return res;
}
}
}
Class>[] interfaces = getInterfaces();
for (Class> c : interfaces)
if ((res = c.getMethod0(name, parameterTypes, false)) != null)
allInterfaceCandidates.add(res);
return null;
}
由于从Java8开始,能够在接口中定义default方法,default方法是不需要在实现类中实现的。当没有在当前类和父类中获取到Method时,interfaceCandidates中会保存在递归中获取到的方法,这些方法中存在相同描述符的方法以及各个接口中相同描述符的default方法。「interfaceCandidates.removeLessSpecifics()」 会将不符合要求的方法剔除,并返回一个最接近的接口中定义的方法。
void add(Method m) {
// MethodArray初始长度是2
// 这里在进行扩容操作
if (length == methods.length) {
methods = Arrays.copyOf(methods, 2 * methods.length);
}
methods[length++] = m;
// 判断Method的类型,如果是default类型的,那么defaults计数器加1
if (m != null && m.isDefault())
defaults++;
}
void removeLessSpecifics() {
// 如果MethodArray中没有default方法,那么直接返回
if (!hasDefaults())
return;
for (int i = 0; i Method m = get(i);
// 找到第一个default方法
if (m == null || !m.isDefault())
continue;
// 以O(N^2)的复杂度,将MethodArray中的方法两两比较
for (int j = 0; j if (i == j)
continue;
Method candidate = get(j);
if (candidate == null)
continue;
// 比较两个method(返回值,方法名和参数列表)
if (!matchesNameAndDescriptor(m, candidate))
continue;
// 比较哪个method最接近
if (hasMoreSpecificClass(m, candidate))
remove(j);
}
}
}
MethodArray当中的方法就不一个个挑出来讲了,每个方法都十分简短易懂。
除了上面所谈及的,其他的和Field都相同,在这里就不赘述了。
Constructor
Constructor是用来创建对象实例的接口,正是这一点导致其不需要再递归地从父类或接口(接口没有定义Constructor)获取Constructor。以「getConstructor」为例说明Constructor在反射特性实现上的区别。
public Constructor getConstructor(Class>... parameterTypes)throws NoSuchMethodException, SecurityException {
// 检查权限
checkMemberAccess(Member.PUBLIC, Reflection.getCallerClass(), true);
// 获取并复制
// NoSuchMethodException由getConstructor0负责跑出
return getConstructor0(parameterTypes, Member.PUBLIC);
}
private Constructor getConstructor0(Class>[] parameterTypes,int which) throws NoSuchMethodException{
Constructor[] constructors = privateGetDeclaredConstructors((which == Member.PUBLIC));// 和Method相比,获取时不需要传递name参数,只需要通过参数列表进行比较即可// 参数列表的比较通过arrayContentsEq实现for (Constructor constructor : constructors) {if (arrayContentsEq(parameterTypes,
constructor.getParameterTypes())) {return getReflectionFactory().copyConstructor(constructor);
}
}throw new NoSuchMethodException(getName() + "." + argumentTypesToString(parameterTypes));
}相比Field和Method,Constructor的获取过程省略了很多步骤
- 不需要privateGet然后再search
- 因此没有提供searchConstructors方法
- 不需要递归查找
- 因此没有提供privateGetPublicConstructors
ReflectionFactory
上面所有涉及获取Field、Method和Constructor的代码中,在通过native方法获取到之后都会通过ReflectionFactory 返回Field、Method或Constructor对象的拷贝。
// 这是searchFields的代码中涉及到的片段
return getReflectionFactory().copyField(fields[i]);
以Field为例,如果光从复制Field对象拷贝的角度出发,那么上面的代码最终是通过Field中的copy实现的
Field copy() {
// This routine enables sharing of FieldAccessor objects
// among Field objects which refer to the same underlying
// method in the VM. (All of this contortion is only necessary
// because of the "accessibility" bit in AccessibleObject,
// which implicitly requires that new java.lang.reflect
// objects be fabricated for each reflective call on Class
// objects.)
if (this.root != null)
throw new IllegalArgumentException("Can not copy a non-root Field");
Field res = new Field(clazz, name, type, modifiers, slot, signature, annotations);
res.root = this;
// Might as well eagerly propagate this if already present
res.fieldAccessor = fieldAccessor;
res.overrideFieldAccessor = overrideFieldAccessor;
return res;
}
在这当中关键的一步就是new Field(clazz,name,type,modifiers,slot,signature,annotations)。Java采用这种方式获取Field很是让我困惑。
为什么要重新拷贝一个Field对象,这样对Field对象的修改要怎么影响到字节码呢?
明明最终的逻辑是通过Field.copy来实现的,为什么要煞有其事的通过ReflectionFactory来包装一层呢?
在这里我只能说,这些都是反射特性的设计者考虑到种种因素(尤其是Method.invoke)而设计出来的。在这里如果展开来说的话会有很多很多点要提及,比如ReflectionFactory的膨胀机制,XXXAccessor,Unsafe类等等。这里就站在阅读Class类源码的层次来简单说明一下。
以获取Field为例,在调用searchFields之前,会调用privateGetDeclaredFields,这个函数最大的特点是会进行缓存,缓存的内容在ReflectionData中。
所有拷贝的Field中,都会通过root指向缓存中的Field,并且会设置FieldAccessor,拷贝后的Field和缓存中的Field都是共享同一个FieldAccessor。当对Field进行设置时,最终会调用Unsafe的对应方法直接操控内存(也就是JVM中的字节码)。
这也是classRedefinedCount修改次数存在的意义,当字节码被修改了之后,通过比较ReflectionData记录的次数就能够对缓存进行更新。
checkInitted
由于ReflectionData中使用useCache作为是否使用缓存的开关,而这个参数又是可以通过外部配置sun.reflect.noCaches进行设置的,因此在所有涉及到设置ReflectionData缓存的函数中需要检查是否进行了初始化,根据外部配置对useCache进行赋值。
这里判断系统初始化是否完成的方法是通过对System.out判断是否为空,如果系统初始化成功了,那么调用System.getProperty("sun.reflect.noCaches")对useCache进行赋值。
private static void checkInitted() {
if (initted) return;
AccessController.doPrivileged(new PrivilegedAction() {public Void run() {if (System.out == null) {return null;
}
String val =
System.getProperty("sun.reflect.noCaches");if (val != null && val.equals("true")) {
useCaches = false;
}
initted = true;return null;
}
});
}#100
反射的话题可以说很多很多,我这篇文章也只是很浅显地记录一下我目前所掌握的内容。实际上有经验人的能够看出来我这篇文章在内容深度上还十分欠缺,对于这个问题我有自己的看法,乘这个机会正好说明自己对阅读源码的一点看法。
源代码的阅读是一个需要讲究技巧的事情,不能一头扎进去不停地进入方法的内部,这么做的后果要么就是遇到native函数,要么就是陷入了细节无法自拔,从而「只见树木不见森林」。
首先,Java的代码设计是十分精妙的,许多方法都封装的很好,看到方法的名字就能够明白这个方法是做什么的,不需要去过分深入研究细节。
其次,要明确阅读源码的目的,要么是弄清楚代码逻辑流程,要么是学习代码设计的思想,而不是比看到更低层次的代码。
最后,有些代码的深入阅读是超过了这篇文章涉及的范围。更低层的代码需要其他语言设计的思想辅助理解,而代码只是实现思想的一种工具,思想永远比工具重要。
所以在满足代码目的的基础上,有些内容不必深入,当谈到对应话题的时候(比如阅读Field或Method源码时),自然会深入到应该有深度。














 87
87











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









