






不管是做后端服务开发还是大数据开发,阅读源代码是个人技能成长过程中必不可少的一环节,本节带你走读一下SparkContext的源代码。后续会列举一些源代码的阅读经验!
SparkContext可以说是整个Spark中统揽全局的一块,因为所有的内部组件都在SparkContext中进行初始化,包括我们在学习中知道的一些DAGScheduler、TaskScheduler、SparkUI、内存管理、日志管理等等,都在SparkContext中显而易见。所以我建议你是在学习Spark原理之后,在捎带手查看一下SparkContext的源代码,这样你会理解的更加深刻。
另外,本文的结束还列举了,如何使用Git+Insight在线的阅读源代码,函数的跳转等等都是支持的,再也不用下载代码到本地然后编译了!好叻,现在开始吧。
如果编写Spark程序,那么第一行代码就是
new SparkContext().setMaster(“local[*]”).setAppName(“xx”),可以说SparkContext是整个Spark 计算的启动器,只有将sparkContext 启动起来,后续的关于调度,存储,计算相关的操作才能够运行,本文基于spark2.x源码概述关于SparkContext里面所包含的启动项都有哪些以及这些启动项的作用是什么,之后在说一下关于SparkEnv环境创建的过程,阅读本文最好打开spark源码参考着看,可以在git上面打开spark关于sparkContext的代码,地址为:https://github.com/apache/spark/blob/c5f9b89dda40ffaa4622a7ba2b3d0605dbe815c0/core/src/main/scala/org/apache/spark/SparkContext.scala#L73
如图为SparkContext内部的一些组件:

SparkEnv :Spark运行时环境,Spark 中任务执行是通过Executor,所有的Executor都有自己的执行环境SparkEnv,在Driver中也包含了SparkEnv,为了保证`Local模式的运行,SparkEnv内部还提供了不同的组件,来实现不同的功能
LiveListenerBus:SparkContext中的事件总线,可以接收各个使用者的事件,异步将SparkListenerevent传递给注册的SparkListener
Spark UI :Spark的用户界面,SparkUI间接依赖于计算引擎,调度引擎,存储引擎,Job,Stage,Executor等组件的监控都会以SparkListenerEvent的形式传递给LiveListenerBus,SparkUI将从各个SparkListener中读取数据并显示在web界面
SparkStatusTracker:用于监控作业和Stage进度状态的低级API
ConsoleProgressBar :定期从sc.statusTracker获得active stage的状态信息,展示到进度条[在SparkUI上面可以看到进度条],会有一定的延时。内部有一个timer 500ms refresh一遍
DAGScheduler:DAG调度器,是Spark调度系统中重要的组件之一,负责创建Job,将DAG的RDD划分到不同的Stage,提交stage等,SparkUI中有关Job和Stage监控数据都来自DAGScheduer
TaskScheduler:Task调度器,是Spark调度系统中重要的组件之一,负责将任务发送到集群,运行,如果有失败的任务则重新执行,之后返回给DAGScheduler,TaskScheduler调度的Task是由DAGScheduler创建的,所以DAGScheduler是TaskScheduler前置调度。
HeatbeatReceiver:心跳接收器,所有的Executor都会向HeatbeatReceiver发送心跳信息,HeatbeatReceiver接收到心跳之后,先更新Executor最后可见时间,然后将此信息交给TaskScheduler。
ContextCleaner:异步清理RDD、shuffle和广播状态信息
ExecutorAllocationManager: Executor动态分配管理器,根据工作负载动态调整Executor数量,当在配置spark.dynamicAlloction.enabled属性为true的情况下,在非local模式下或者spark.dynamicAllcation.testing属性为true时启用
ShutdownHookManager:设置关闭钩子的管理器,可以给应用设置钩子,这样当JVM退出的时候就会执行清理工作
除了以上这些SparkContext包含的内部组件,还包括如下一些属性:
creationSite:CallSite类型,保存着线程栈中最靠近栈顶的用户定义的类和最靠近栈底的Scala或者Spark核心类的信息,其中ShortForm属性保存着上述信息的间断描述,LongForm属性保存着上述信息的完整描述,具体的信息可以参阅源码部分地址为:core/src/main/scala/org/apache/spark/util/Utils.scala/getCallSite
allowMulitipleContext : 是否允许多个SparkContext实例,默认为False,可以通过设置Spark.Driver.allowMulitipleContexts来控制
startTime:标记sparkContext的启动时间戳
stopped:标记sparkContext是否处于停止状态,采用原子类型AtomicBoolean
addedFiles:用于每个本地文件的URL与添加此文件到到addedFiles时的时间戳之间的映射缓存 new ConcurrentHashMap[String, Long]
addedJars : 用于每个本地Jar文件的URL与添加此文件到addedJars时的时间戳之间的映射缓存 new ConcurrentHashMap[String, Long]
persistentRdds : 用于对所有持久化的RDD保持跟踪
executorEnvs:用于存储环境变量,将用于Executor执行的时候使用
sparkUser:当前系统的登录用户,可以通过环境变量SPARK_USER来设置 通过Utils.getCurrentUserName()获取
checkpointDir :RDD计算过程中用于记录RDD检查点的目录
localProperties:InheritableThreadLocal保护的线程,其中的属性值可以沿着线程栈一直传递下去
_conf : SparkContext的配置,会先调用config的clone方法,在进行验证配置,是否设置了spark.master和spark.app.name
_jars : 用户提交的jar文件,当选择部署模式为yarn时,_jars是由spark.jars属性指定的jar文件和spark.yarn.dist.jars属性指定的并集
_files : 用户设置的文件,可以根据Spark.file属性指定
_eventLogDir : 事件日志的路径,当spark.enabled属性为true时启用,默认为/tmp/spark-events,也可以通过spark.eventLog.dir来指定目录
_eventLogCoder : 事件日志的压缩算法,当spark.eventLog.enabled属性与spark.eventLog.compress属性为true时,压缩算法默认为lz4,也可以通过spark.io.compression.codec属性指定,目前支持lzf,snappy和lz4
_hadoopConfiguration: Hadoop配置信息,如果系统属性SPARK_YARN_MODE为true或者环境变量SPARK_YARN_MODEL为true,那么将会是YARN的配置,否则为Hadoop的配置
_executorMemtory : Executor内存大小,默认为1024MB,可以通过设置环境变量(SPARK_MEM或者SPARK_EXECUTOR_MEMORY)或者Spark.executor.memory属性指定其中Spark.executor.memory优先级最高
_applicationId : 当前应用的标识,TaskScheduler启动后会创建应用标识,通过调取TaskScheduler的ApplicationId获取的
_applicationAttempId : 当前应用尝试执行的标识,Spark Driver在执行时会多次尝试,每次尝试都会生成一个标识来代表应用尝试执行的身份
_listenerBusStarted : LiveListenerBus是否已经启动的标记
nextShuffleId : 类型为AtomicInteger,用于生成下一个shuffle标识
nextRddId :类型为atomicInteger,用于生成下一个rdd标识
1.创建SparkEnv
在Spark中,需要执行任务的地方就需要SparkEnv,在生产环境中,Spark往往运行于不同节点的Execute中,SparkEnv中的createDriverEnv用于创建SparkEnv,之后sparkEnv的实例通过set设置到SparkEnv伴生对象env属性中,然后在需要用到sparkEnv的地方直接通过伴生对象get获取SparkEnv
2.创建心跳接受器(HeatbeatReceiver)
在Spark local运行模式中,driver和executor在同一个节点同一个进程中,所以driver和executor可以本地交互调用,但是在分布式的环境中,driver和executor往往运行在不同的节点不同的进程中,driver就无法监控executor的信息了,所以driver端创建了心跳接收器,那么心跳接收器是如何创建的。
首先通过SparkEnv的NettyRpcEnv(基于Netty RPC)的setupEndPoint方法,然后向Dispatcher注册HeartbeatReceiver,并返回HeartbeatReceiver的NettyRpcEndPointRef的引用
3.创建和启动调度系统
Spark调度系统主要分为TaskScheduler和DAGScheduler,TaskScheduler负责请求集群管理器给应用程序分配并运行Executor并给Task分配Executor并执行,DAGScheduler主要用于在任务交给TaskSchduler执行之前做一些准备工作,比如创建Job,将DAG的RDD划分到不同的Stage,提交Stage等,如代码:
val (sched, ts) = SparkContext. createTaskScheduler( this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler( this)
_heartbeatReceiver. ask[ Boolean]( TaskSchedulerIsSet)SparkContext.createTaskScheduler方法用于创建和启动TaskScheduler,针对不同的部署模式创建调度器的方式也不同,在代码中,_schedulerBackend表示SchedulerBackend的引用,_taskScheduler表示TaskScheduler的引用,在TaskScheduler中还会创建DAGScheduler的实例,最后向_heartbeatReceiver发送TaskSchedulerSet的消息,HeartbeatReceiver接收到之后将获取SparkContext的_taskScheduler属性设置到自己的Schduler属性中
4.创建Executor动态分配管理器
ExecutorAllocationManager: Executor动态分配管理器,根据工作负载动态调整Executor数量,当在配置spark.dynamicAlloction.enabled属性为true的情况下,在非local模式下或者spark.dynamicAllcation.testing属性为true时启用
ExecutorAllocationManager内部会定期的根据负载计算所需的Executor数量,如果Executor需求数量大于之前向集群管理器申请的数量,那么向集群管理器申请添加executor数量,反之,如果executor需求数量小于之前向集群管理器申请的数量,那么向集群管理器申请减少executor。此外,ExecutorAllocationManager还会定期向集群管理器申请移除已经过期的executor
5.创建和启动ContextCleaner
ContextCleaner:异步清理RDD、shuffle和广播状态信息
通过配置spark.cleaner.referenceTracking(默认为true)来决定是否启用ContextCleaner
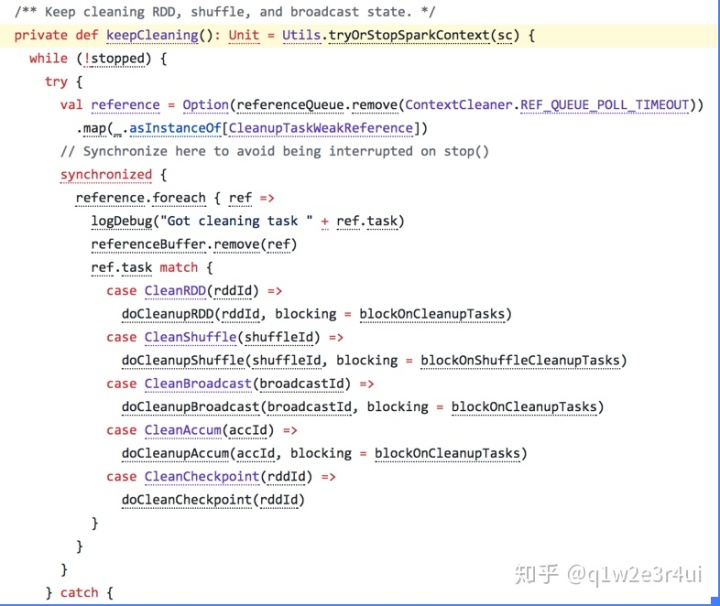
ContextCleaner的组成:
referencesQueue:缓存顶级的AnyRef引用
referencesBuffer:缓存AnyRef的虚引用
listeners:缓存清理工作中的监听器数组
cleaningThread:清理具体工作的线程,此线程为守护线程
periodicGCService:用于执行GC的调度线程池
periodicGCInterval:执行GC的时间间隔,可通过spark.cleaner.periodicGC.interval配置,默认30分钟
blockOnCleanUpTasks:清理非shuffle数据是否是阻塞的,可通过配置spark.cleaner.referenceTracking.blocking配置,默认是true
blockOnShuffleCleanUpTasks:清理shuffle数据是否是阻塞的,可通过配置spark.cleaner.referenceTracking.blocking.shuffle ,默认是false
stoped:标记contextCleaner是否停止状态
以上可以在github上打开spark源码进行边看文章边看源码,你会受益良多。
在这里推荐一个github源码阅读插件Insight.io for Github 在chrome扩展程序里可以直接查询

希望本文对你有帮助!
感谢关注“码农星球”。本文版权属于“码农星球”。我们提供咨询和培训服务,关于本文有任何困惑,请关注并联系我们。














 4624
4624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









