






1.数据预处理
导入包
import 导入数据(数据资源分享链接见文末)
data 在Console查看导入的数据
data因为原excel文件里还有其他信息,所以数据需要处理
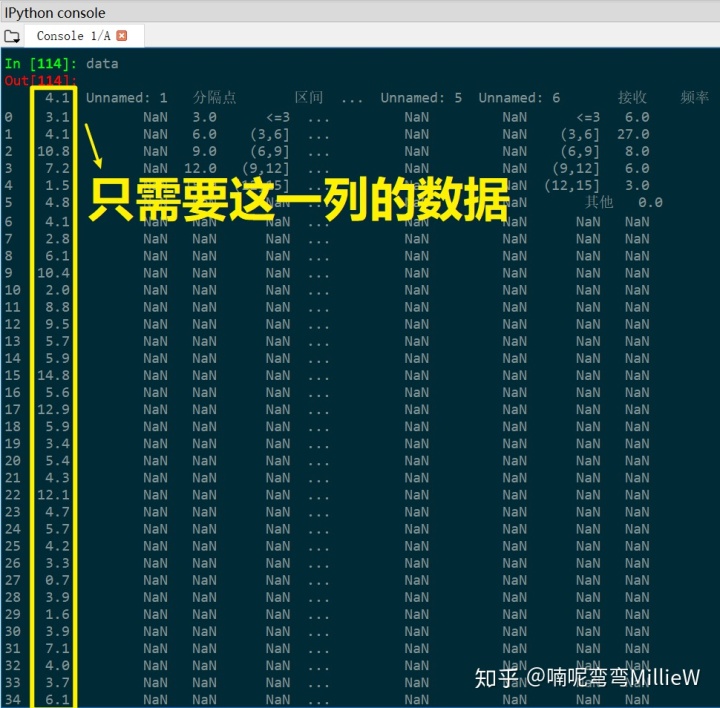
处理数据
在Console查看data的数据类型:
type(data)
取Dataframe类型的数据的第一列:
data1=data.iloc[:,0]统计数据个数:

发现少1个数(总共应该有50个数)
原来是第一个数4.1被当成了DataFrame的索引:
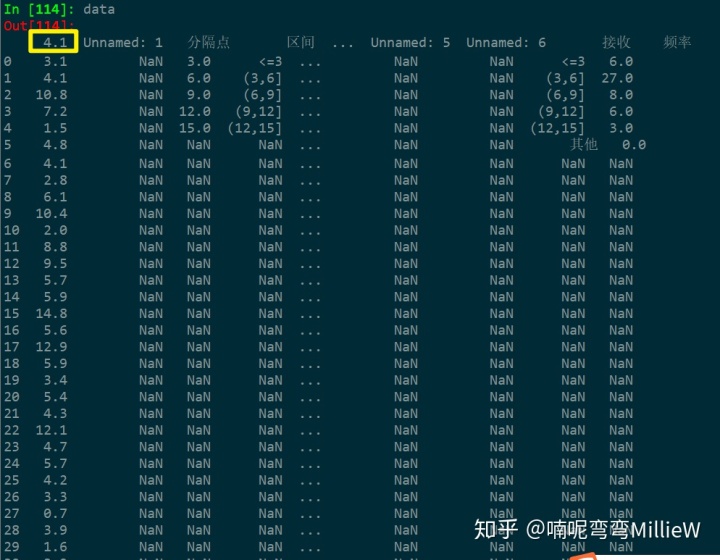
补充缺失的值4.1
先在Console查看data1的数据类型
type(data1)
补充Series的缺失值:
n=pd.Series([4.1])
data2=data1.append(n)2.制作频数分布表
将data2分为5个区间(0, 3],(3, 6],(6, 9],(9,12],(12,15]:
a=pd.cut(data2,[0,3,6,9,12,15], labels=[u"(0,3]",u"(3,6]",u"(6,9]",u"(9,12]",u"(12,15]"])在Console查看a:

......

计算频数
b=a.value_counts()在Console查看b:
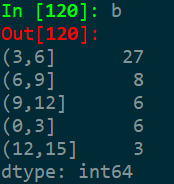
按照b的索引升序排序
b2=b.sort_index()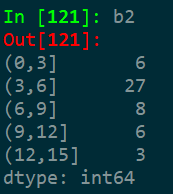
3.绘制频数分布图
将Series转换为DataFrame,便于使用Seaborn绘图:
c={'section':b2.index,'frequency':b2.values}
e=pd.DataFrame(c)matplotlib字体的默认设置中并没有中文字体,为避免中文字符乱码,添加中文字体:
plt.rcParams['font.sans-serif']=['SimHei']使用Seaborn的barplot绘制条形图:
ax = plt.figure(figsize=(10, 5)).add_subplot(111)
sns.barplot(x="section",y="frequency",data=e,palette="Set3") #palette设置颜色设置y轴刻度范围:
ax.set_ylim([0, 30])设置坐标轴文字:
ax.set_xlabel('区间', fontsize=20)
ax.set_ylabel('频数', fontsize=20)设置标题:
ax.set_title('频数分布图', size=40)设置坐标轴刻度字体大小:
plt.xticks(fontsize=30)
plt.yticks(fontsize=30)显示每个柱体的值:
for x, y in zip(range(5), e.frequency):
ax.text(x, y, '%d'%y, ha='center', va='bottom', fontsize=30, color='grey')保存图片:
plt.savefig('Python绘制的频数分布图.jpg',dpi=500,bbox_inches = 'tight')
#bbox_inches = 'tight'使保存的图片显示完整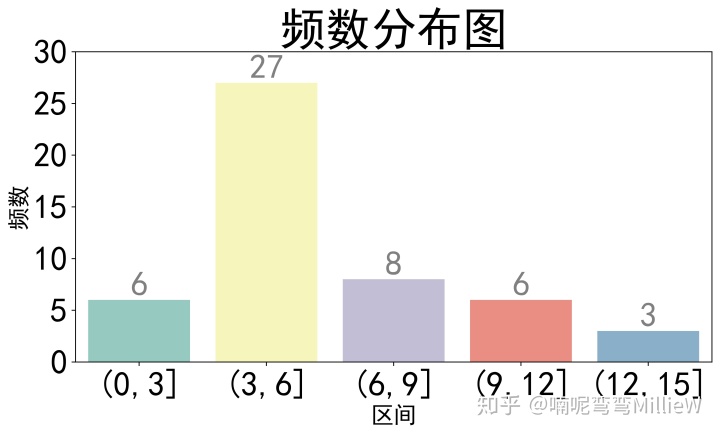
获取数据和源代码:
链接:https://pan.baidu.com/s/17dh7WBCd8KGcuNcwkmZ1Pw
提取码:n996















 2267
2267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









