






嵌入式特征选择方法,号称结合了过滤式和包裹式的优点,将特征选择嵌入到模型构建的过程中:
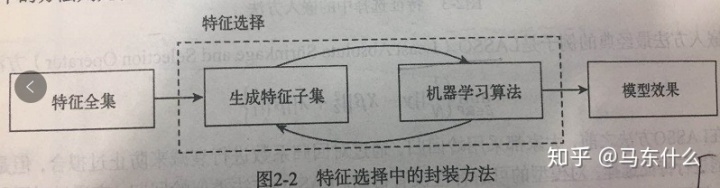
这是特征选择的一整个流程的总结,所谓嵌入式特征选择,就是通过一些特殊的模型拟合数据然后根据模型自身的某些对于特征的评价的属性来作为评价指标,最后再使用包裹式的特征选择方法来选择,当然,很多时候我们还是仅停留在计算出评价指标的阶段,因为包裹式特征选择的最大问题就是计算量和时间是三者之中最大的。
最常用的进行嵌入式特征选择的模型:树模型和带正则项的模型(线性回归、逻辑回归、svm、svr、神经网络等)。
鉴于最近在写回归类模型的面经,就先从这类模型的特征选择方法开始说起好了。首先最常用的就是广义线性回归里的L1正则化。
基于L1正则项的嵌入式特征选择
下面以lasso为例
import pandas as pd
from sklearn.datasets import load_boston
from sklearn.linear_model import Lasso
from sklearn.preprocessing import StandardScaler
X=pd.DataFrame(load_boston().data)
y=load_boston().target
sd=StandardScaler()
X=sd.fit_transform(X)
coefs=[]
for alpha in [0.01,0.05,0.1,0.5,1]:
lr=Lasso(alpha=alpha)
lr.fit(X,y)
coefs.append(lr.coef_)
coefs=pd.DataFrame(coefs)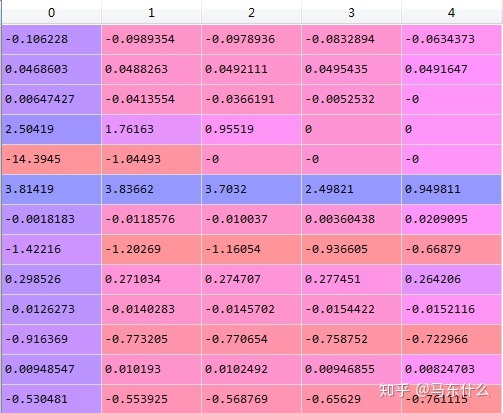
这里就存在一个很严重的问题了,我们取了5组不同的的正则化系数的情况下,得到的特征重要性(也就是线性模型的权重值)的变化情况很严重,比如从上往下数第4、5个特征的变动幅度太大了,虽然越大的正则化系数越容易得到小的权重系数,但是问题是这里的第4、5个特征的相对其它特征的权重系数的取值的排序也发生了非常大的变化,尤其是第5个特征,在正则化系数取值为0.01的时候其权重系数为-14.3945,可以说负贡献很大,但是当正则化系数为其他值是,权重系数大幅下降甚至变成了0。
这里的发生这种现象的原因有很多,比如存在多重共线性问题会导致权重的方差变化增大,通过查看原始数据的相关系数表可以看出,这列特征和其它特征存在较大的相关关系:
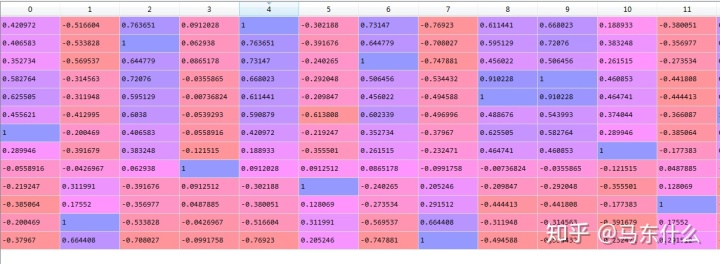
当然,不仅仅是共线性的问题,不同的数据集本身就会产生不同的特征重要性判断,这个在后面的树模型的feature importance中也会有这样的问题,而且数据量越小越容易出幺蛾子,关于更加详细系统的lasso的这种不稳定的原因,后续会写到回归类面经的专栏里,以及多重共线性的相关的问题,这里不赘述了,因为要写起来太特么多了。
那么这里我们应该怎么解决这个问题?我们到底应该依赖与哪一个正则化系数给出的判定的结果。
1、思路一
lassocv的思路给出了一个比较暴力的解决方案,尝试大量的正则化系数,然后选择损失函数最小的模型对应的正则化系数。简单说,也就是对于上述的不稳定性问题采取无视的态度。就是取泛化性能最好的模型的特征重要性判断结果。
lr=LassoCV(alphas=np.linspace(0,1,100),cv=3)
lr.fit(X,y)
print(lr.alpha_) #这里的alpha为最佳的alpha值
print(lr.mse_path_) #输出每一个alpha对应的交叉验证的mse的值类似的逻辑回归也有类似的LogisticRegressionCV的方法,原理基本是类似的,这里就不赘述了,自己去看官网的api就行。
不仅仅是线性回归和逻辑回归,任何广义线性模型如FM/FFM,神经网络,都可以使用L1正则项对损失函数施加惩罚项。
思路二
类
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1413
1413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









