





来自 Word2Vec 的词向量满足矢量相加: “国王 - 王后 = 男人 - 女人“ 。但 BERT或ELMO 给出的词向量编码了上下文信息,不再满足矢量相加。最近两篇文章发现这些上下文相关的词向量学到了语法的树结构【1,2】。这篇文章解读如何从 BERT 词向量提取语法树。
故事要从 Hewitt 和 Manning 的文章 A Structural Probe for Finding Syntax in Word Representations 【文献2】说起。这篇文章发明了一种结构探针“structural probe“,计算词向量在高维语义空间(比如1024维)中的距离,并将其映射到语法树中词与词之间的距离。从下图看出,BERT 词向量几乎完美学到了语句的语法树结构。

语法树中词与词之间的距离 Tree Distance
这篇文章的第一个洞见是,语法树中词与词之间的距离满足勾股定理,即 Squared L2 distance。文献【1,3】给出了非常清晰的几何图像。即树结构中不相邻词之间的距离由勾股定理给出,如下图右边树的节点A和B之间距离计算公式:
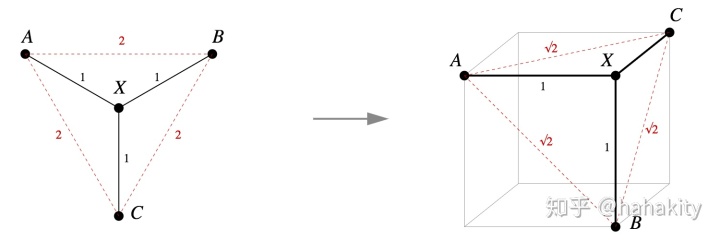
对于更复杂的语法树,文献【1,3】给出了树距离的一般计算公式,即每条边都对应一个新的与之前所有边都垂直的维度。
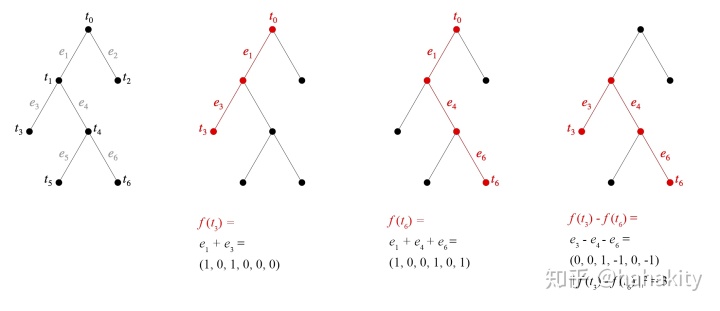
如上图语法树,
这样
高维空间词向量之间的距离
现在我们知道了如何计算语法树中两个词
计算两个1024维向量之间的距离,最简单的公式是内积距离:
- 半正定
- 交换对称
- 三角不等式
这些条件可以通过一个半正定的测度矩阵
这个公式也可以理解为先将 1024 维的词向量线性映射到低维空间,再计算距离。
但这个线性映射矩阵 B 如何选取呢?文章通过训练一个神经网络,来学习 B 矩阵的矩阵元。损失函数设为词向量之间的距离
其中
测试运行
文章的源代码开源,Github 地址为:https://github.com/john-hewitt/structural-probes 这个代码提供了预训练的 Pytorch 版 BERT-Large 模型,以及预训练的语法树探针(即线性映射矩阵B的参数)。使用这些预训练模型,大家可以测试 BERT 词向量学到的语法树。
根据说明文档,下载安装,运行Github中提供的最简单的例子,"The chef that went to the stores was out of food"。得到 BERT 词向量学到的树结构如下,树结构中“is”是 “was” 的原型。
对比 Github 中文章作者运行得到的树结构,两者有微小的差别,即文章作者运行结果正确寻找到了语法树的 Root -- “is”。我测试的结果,BERT 词向量学到的树结构把“out“识别成了语法树的 Root。

代码还输了不同词在语法树中的深度,Root 词深度最浅,一般是一个语句的谓语。对于这个简单的例子,我测试运行得到的词深度分布如下,从词的深度来看,"was" 深度最浅,理应被当作 Root,之前所示树结构的画图部分应该有Bug。
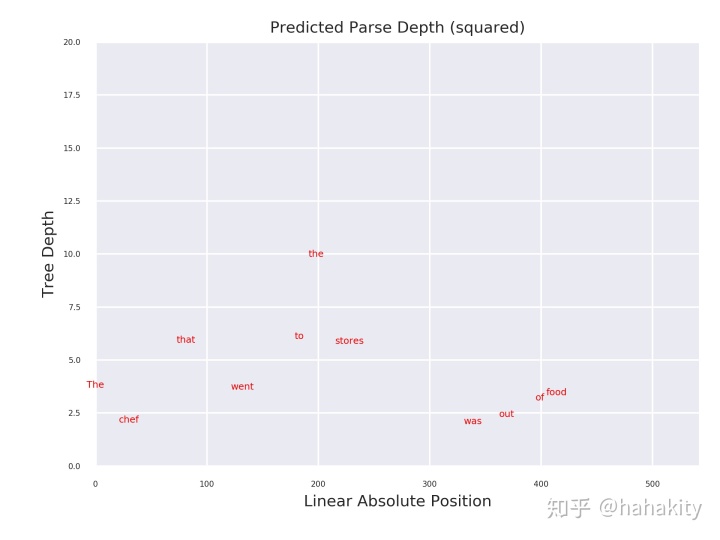
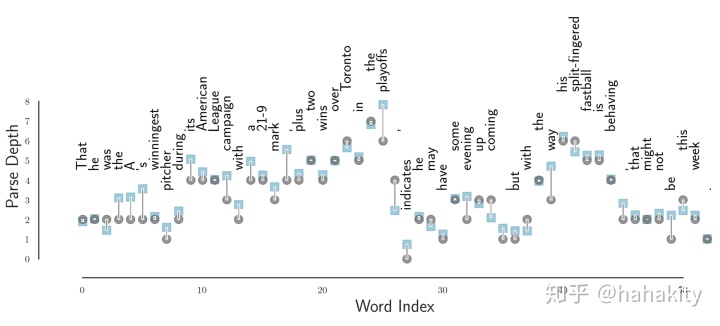
文章对一些非常长的语句,对比了词在基准语法树中的深度与在BERT Tree 中的深度。下图横坐标是词在句子中的位置,纵坐标是词在语法树中的深度。灰色原点表示词在基准语法树中的深度(标准答案),蓝色方块是 BERT 词向量学到的语法树中词的深度。可以看到两者比较一致,尤其是两者都学到了语法树的根结点 -- “indicates"。
总结
这两篇文章从一个异乎寻常的角度研究 BERT 词向量究竟学到了什么。从结果来看,语法树结构编码在 BERT 词向量中。但BERT 词向量是1024维空间的向量,语法树只是这个巨大空间的低维投影。如果将BERT词向量向其他方向投影,定义新的距离测度,能不能揭示 BERT 词向量学到的其他内容?
参考文献
- Visualizing and Measuring the Geometry of BERT
- https://nlp.stanford.edu/pubs/hewitt2019structural.pdf
- Language, trees, and geometry in neural networks
- https://dawn.cs.stanford.edu/2018/03/19/hyperbolics/
- Poincaré Embeddings for Learning Hierarchical Representations
- Hyperbolic Geometry














 2665
2665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









