





读完本篇你将会了解到:
1.对象的创建详细过程
2.对象分配内存的两种方式
3.对象栈上分配的详细说明+代码验证
4.对象gc的详细过程
5.对象从年轻代移动到老年代的几种方式
6.垃圾对象的判断方式
一、对象的创建
Java中对象的创建方式一般有两种,1.new xxx() 通过new关键字创建实例对象。2.通过反射创建对象。不管哪一种创建方式,jvm底层的执行过程是一样的。
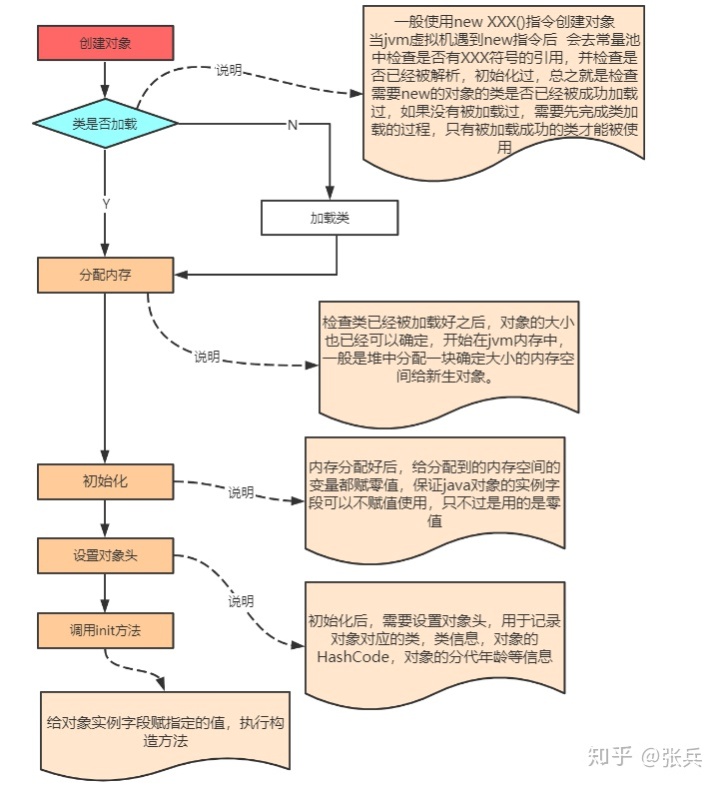
创建对象大致分为5步:1.检查类是否加载,没有加载先加载类 2.分配内存 3.初始化 4.设置对象头 5.执行初始化方法 例如构造方法等
1.检查类是否加载:当需要创建一个类的实例对象时,需要先判断该类是否被成功加载过了,若没有加载,要先进行类的加载,如果加载过了,会在堆区有一个类的class对象,方法区会有类的相关元数据信息。
为什么需要有这一个判断?之前讲类加载时说过,类的加载都是懒加载,只有当使用类的时候才会加载,所以先要有这个判断。
2.分配内存:类加载成功后,jvm就能够确定对象的大小了,然后jvm会在堆内存划分一块对象大小的内存空间出来,分配给新生对象。(当然,如果开启了逃逸分析,jvm会先判断,是否可以在栈上分配,栈上分配是jvm对内存的一种优化,减轻堆的压力,通过标量替换的方式,把对象肢解到栈上,这个后面会讲)
jvm如何在堆中分配内存的呢?
一般有两种方式:1.指针碰撞法 2.空闲列表
指针碰撞:前提堆中的内存空间比较规整,维护一个内存指针,然后通过移动指针的方式给对象分配内存空间。jvm默认使用指针碰撞分配内存
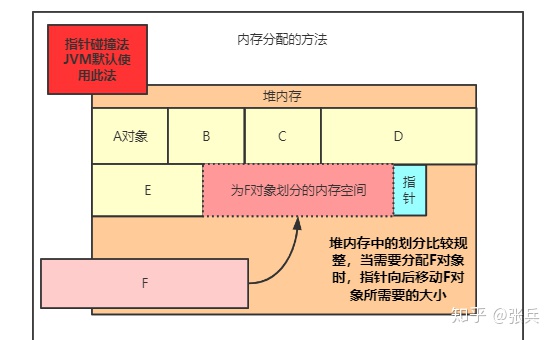
空闲列表:堆中的内存并不规整,比较凌乱,jvm通过维护一个空闲列表的方式,为新生对象分配内存,这个空间列表中保存了所有空闲的内存,当对象需要分配内存时,从空闲列表中找到一块足够对象大小的内存,分给新生对象。
这种方式可能会产生一些碎片空间。因为并不是每次都凑巧能找到正好对象大小的空间,很多时候都是大于对象带下的,造成部分空间浪费
思考题:当多个线程同时分配内存时,这里是否会有线程安全问题?
答案:当然有。
例如:用指针碰撞时,如果F和G同时需要分配内存,F和G的大小不同,他们同时获取到了指针位置,同时移动指针为对象分配内存空间,这样就会出现并发问题。
空闲列表也会有并发问题。
jvm当然有方法解决并发问题,两种方法:1.cas+重试机制 2.TLAB(thread local Allocation buffer)本地线程分配缓冲(默认)。
cas+重试机制:就是通过cas操作移动指针,只有一个线程可以移动成功,移动失败的线程重试,直到成功为止。
本地线程分配缓冲:这种方式设计思想很简单,就是当线程开启时,就为每个线程分配一块较大的空间,然后线程内部创建对象的时候,就从自己的空间分配,这样就不会有并发分配问题了。
如果线程自己的空间用完了,那就要从堆中内存分配了,从而转为cas+重试机制解决并发问题。
以上是对象想创建的第二步,内存分配。
3.初始化:就是对分配的这一块内存初始化为零值,也就是给实例对象的成员变量赋值为零值,引用类型为null,int类型赋值为0等等操作。这样的话,对象就可以在没有赋值情况下使用了,只不过访问对象的成员变量都是零值。
4.设置对象头:在说道对象头这一块,先来看看对象的结构。
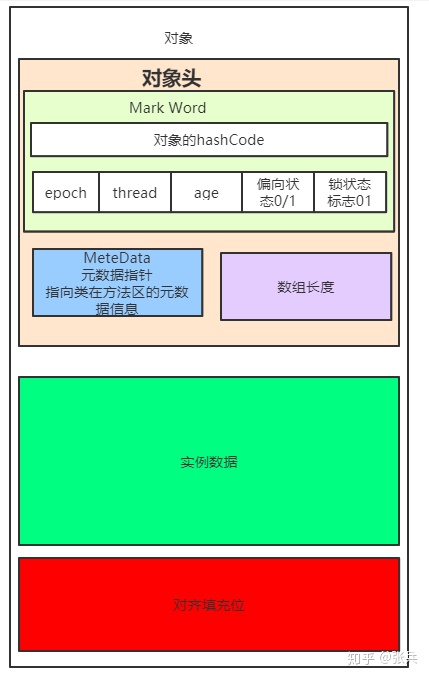
对象分为对象头,实例数据区,对齐填充位。
实例数据区:就是保存对象成员变量的值,引用类型的话保存的是内存地址。
对齐填充位:不是必然存在的,因为hotspot虚拟机要求对象的起止地址必须是8字节的整数倍(可能是为了便于寻址操作),也就是要求对象大小为8字节的整数倍,其实对象的大小不一定正好是8字节的整数倍,那么就需要这个对齐填充位给进行占位,补够8的整数倍。
重点说下对象头,对象头分为mark word,元数据区,对于数组对象还有记录数组长度的区域,这三块保存着对象的hashCode值,锁的状态,类元数据指针,对象的分代年龄等等信息。
mark word在32位操作系统中占4个字节 在64位中占8个字节
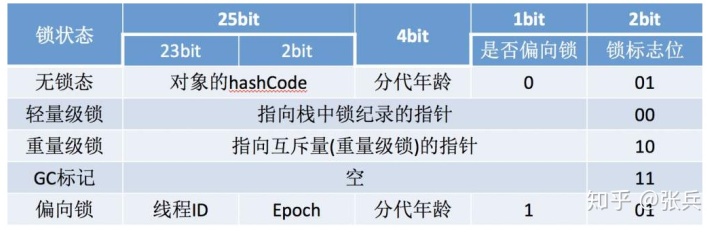
设置对象头,就是设置对象头中对象的hashcode,分代年龄,锁状态,类元数据指针等信息。对象头设置好了之后就可以执行对象的一些初始化方法了。
5.执行初始化方法:这一步,jvm会给对象的成员变量设置程序员指定值的初始值,并且会执行构造方法。
通过工具来看一下对象的大小
添加依赖
对象内存分配
- 逃逸分析:即jvm判断对象会不会逃离某个方法,比如在某个方法中创建对象,方法执行完成后 对象就成了垃圾对象,这就是对象没有逃离方法之外,针对这种情况,jvm可以做很多优化,例如,锁消除,栈上分配等。
如果判断对象并不会被外部访问,也就是未逃逸出方法,jvm会进行栈上分配,但是jvm一般不会直接在栈内创建对象,而是将对象的成员变量分解成若干个可以被方法使用的局部变量所代替,这些代替的局部变量在栈帧或寄存器中分配空间,这样就不会因为没有一大块连续的内存空间而导致无法在栈上分配,这种方式有个专业名词:标量替换。
验证一下栈上分配
public 假设:一亿个对象都分配在堆中,15M是不够用的,会发生gc
jvm配置:我们把堆的内存配置15m -Xms15m -Xmx15m 并打印出gc日志 -XX:+PrintGC
(1)开启逃逸分析和标量替换
-XX:+DoEscapeAnalysis -XX:+EliminateAllocations
执行结果:

没有发生gc,说明不是在堆上分配的。
猜测可能是在栈上分配,因为通过标量替换,对象的成员变量转化为局部变量分配在栈帧中,随着alloc()方法的进栈和出栈 对象被回收,所以没有发生gc。
验证一下猜想:
(2)开启逃逸分析,关闭标量替换
-XX:+DoEscapeAnalysis -XX:-EliminateAllocations
执行结果:
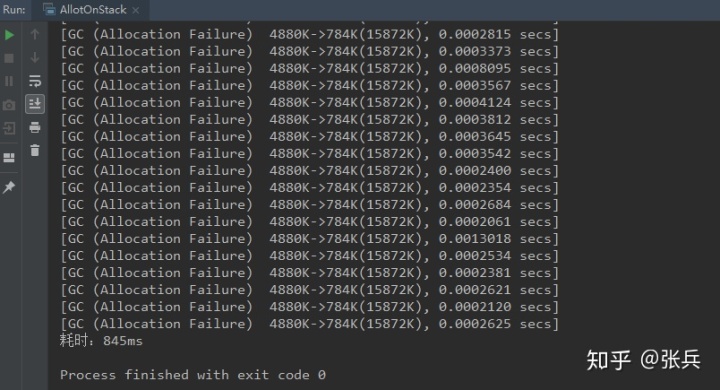
发生了大量的gc;
虽然开启了逃逸分析,但是并没有开启标量替换,所以会在堆中分配 因此会导致发生大量gc
(3)关闭逃逸分析,开启标量替换
-XX:-DoEscapeAnalysis -XX:+EliminateAllocations
执行结果:
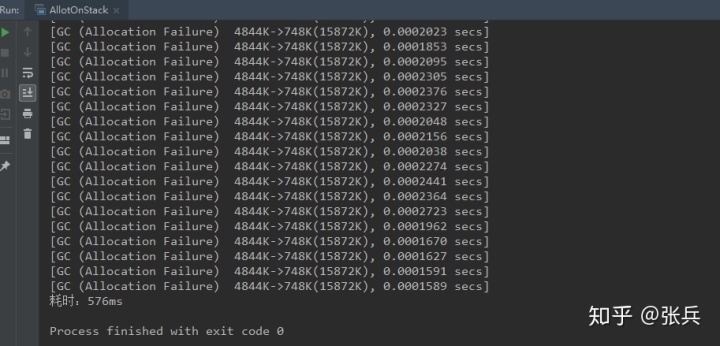
一样的结果,会发生gc,在堆上分配。
总结:只有同时开启逃逸分析和标量替换,对象才能成功在栈中分配,这是一种优化,减少堆的压力,减少发生gc的频率。
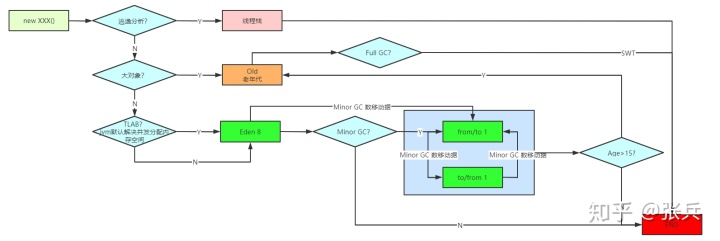
当然,大部分情况下对象是在堆中分配的,为了方便分代回收垃圾,堆划分为年轻代(eden,s0,s1)和老年代两个区域。
而新生对象一般分配到eden伊甸园区,大对象一般直接进入老年代(大对象可以通过参数指定)。当eden区的内存不够了,会触发一次minor gc。
二、对象的回收
1.eden区分配对象
对象在jvm内存中分配好内存后,当对象不再被使用,是需要被回收掉的,腾出来空间给其他对象使用。这就是对象的gc,垃圾回收,本篇只会大概介绍一下gc,并不涉及gc算法和垃圾回收器的讲解(gc算法和垃圾回收器的详细解析将在下一篇文章中)。
上面说了,一般对象分配在eden区,当eden区不够用了,发生一次minor gc。
先来看看minor gc和full gc
Minor GC/Young GC:指发生在年轻代的垃圾回收动作,效率高速度快,但是只清除年轻代的垃圾对象。
Major GC/Full GC:指发生一次全面的垃圾回收动作,作用范围包括老年代,年轻代,方法区等内存区域,发生Full GC 会有一次比较长的STW(Stop The World),效率低,速度慢,清除的垃圾对象较多。
年轻代分为eden区和两个survivor区,比例为8:1:1,这个比例可以通过参数修改,不推荐改动,因为这个比例一定是一个大多数场景下最优的一个比例,让eden区足够大,survivor够用即可。
当eden区满了以后,会发生minor gc,存活下来的对象会被移动到survivor区,如果survivor区装不下这批对象,则会直接移动到老年代。
一般99%的对象都会被回收掉,因为年轻代一般都是朝生夕死的对象,存活时间很短,所以大部分对象都会被回收的,而存活下来的对象的年龄+1。
随着minor gc,存活下来的对象在两个survivor区来回移动,年龄不断+1,年龄到15岁时,就被移动到老年代。
public 结果:
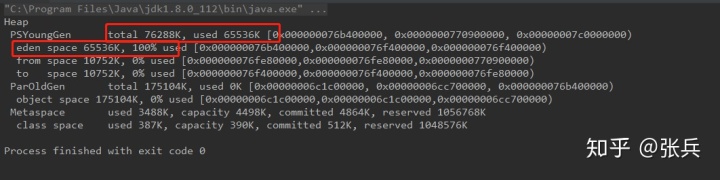
可见年轻代总共70M左右,eden占60M左右,被使用100%,而我们创建的数组对象全部分配到eden区了。
假如我们一次创建70M的对象会发生什么?
public 结果:

首先发生了一次gc,
eden去只用了16%左右的空间,老年代也用来34%左右的空间,这是为什么呢?
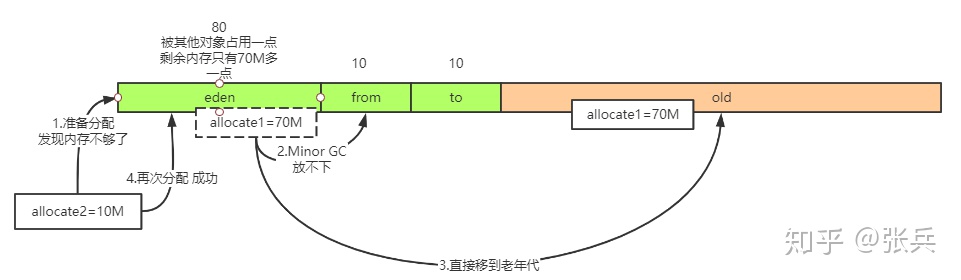
分析一下:当我们先给allocate1 分配内存,这60M再加上一些其他对象(程序运行肯定还有其他一些jvm创建的对象)全部分配在eden区,一下子把eden去占满。
然后开始分配allocate2了,需要在分配10M出来,这时候发现eden区不够,触发一次gc,把eden区的对象移动到from区,移动过去60多M,发现from区装不下(因为from区只有10752K大),那么把装不下的那批对象全部移到老年代。所以老年代会被占用了34%左右。
2.大对象的内存分配
什么是大对象?
就是占用内存比较多的对象,这个大对象的定义可以通过参数-XX:PretenureSizeThreshold设置,大对象一般直接分配到老年代,这是jvm的一种优化设计。
为什么这么设计?试想一下,如果还是分配eden的话,大对象会一下子占用eden区很多空间,给其他对象留的空间就变少了,容易触发minor gc,在gc时,大对象如果存活,还需要复制这个大对象到survivor区,而且容易导致survivor区不够用,最终还是要被移到老年代。
不如直接分配到老年代。
public 配置jvm参数 -XX:+PrintGCDetails -XX:PretenureSizeThreshold=1000000(表示对象达到1000000 单位B,1kB就是大对象) -XX:+UseSerialGC
执行结果:
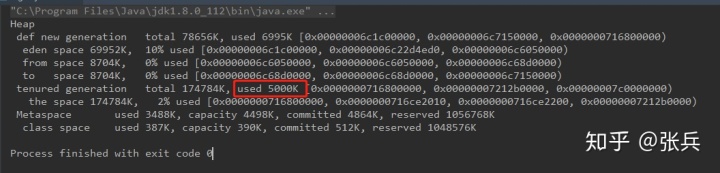
这5M的对象直接进入老年代了。
3.长期存活的对象
上面提到过,当对象在经历了15次minor gc后是要被移动到老年代的,这种存活了较长时间的对象就是长期存活对象,移动到老年代的阈值就是对象的分代年龄,对象没经过一次的minor gc,年龄就+1,可以通过参数-XX:MaxTenuringThreshold修改这个值,
年轻代一般都是存放一些朝生夕死的对象,每次发生在年轻代的Minor GC效率都是很高的速度比Full GC快很多,当一个对象变成了“老当益壮”,jvm就会认为你还能活挺久的,就不让在待在年轻代玩了,会把你移入老年代,所以老年代一般都是存放一些存活时间较长的对象,并不容易被GC回收。
4.对象动态年龄判断
这是一种什么机制呢?解释一下,就是说在程序运行的过程中,会不断有新的对象产生,也会不断发生gc回收垃圾对象,因此不断有对象从eden区转移到survivor区,而survivor区中的对象也会越来越多,各个年龄的对象都有。
这个机制就是说,当survivor区中的对象从年龄为1开始,年龄1+年龄2+...+年龄n对象的综合占用survivor区的50%以上,那么年n以上的对象全部被移动到老年代。
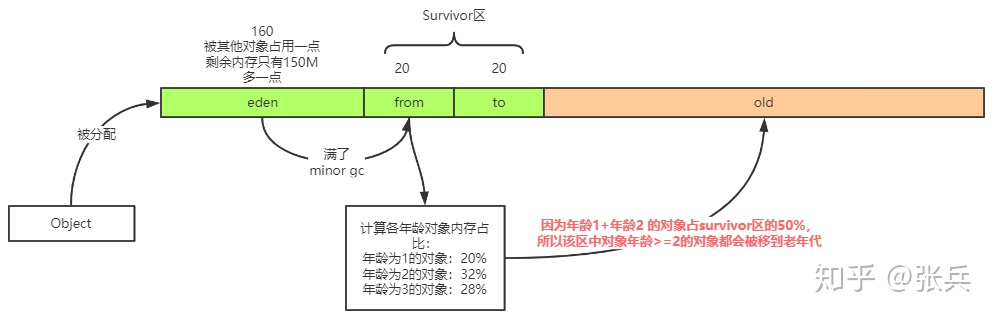
这种机制是jvm的一个预测机制,虽然这批对象没有到15岁,但是年龄低于这一批对象的其他对象都占survivor区的50%多了,预示着survivor区快要满了且这批对象可能会成为长期存活的对象,那不如提前进入老年代,减少年轻代的压力。这个机制一般是在minor gc之后触发的。
5.老年代空间分配担保机制
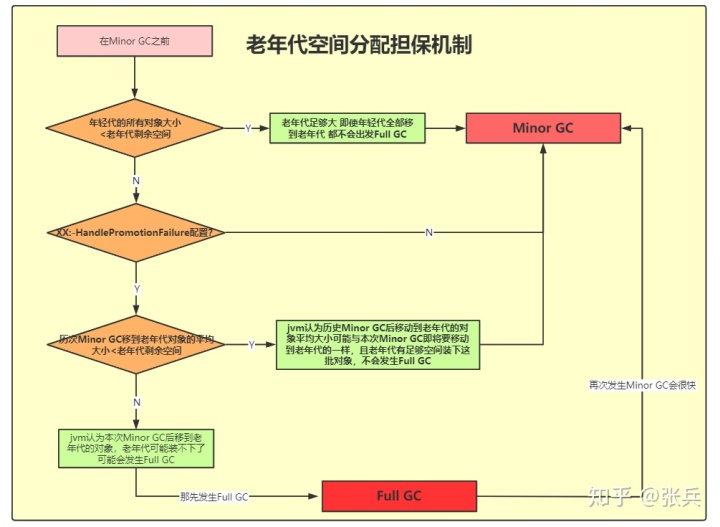
这个机制说白了就是jvm判断一下你本次Minor GC发生以后,移动到老年代的对象会不会导致发生Full GC,JVM判断如果会,那就先进行Full GC 之后如果需要在进行Minor GC 这时候Minor GC 回收的内存空间会很少,甚至都不需要在进行Minor GC 可以提升一部分GC效率。
总结对象被移动老年代的情况:
1.对象年龄达到15
2.大对象
3.minor gc后survivor区装不下存活的对象了
4.动态年龄判断机制
三、垃圾对象收判断方式
1.引用计数器
对象通过维护一个引用计数器,计算被引用的次数,对象被引用一次,计数器就+1。当计数器为0时,说明对象已经不被引用了,可以被回收了。
这种方式有个致命的缺陷,当堆中的两个对象相互引用,但这两个对象并没有被外部使用,他们的计数器是1,所以并不会被回收,造成内存泄漏。
一般很少有垃圾收集器会使用这种方式判断垃圾对象。
2.可达性分析法
这种方式也比较简单,就是从gc root(这个gc root 可以是栈中的引用变量,也可以是方法区的引用变量或常量)开始扫描堆中的对象,沿着gc root一路扫描,被扫描到的所有对象全部时存活对象。
比如A对象被线程占中的变量a引用着,A中引用着B对象,B又引用着C->D->E等等,沿着a开始扫描,会扫描到对象A,B,C,D,E并把他们标记为存活对象。
扫描完成之后,没有被标记的自然就是垃圾对象了。
拓展:如何判断一个类是无用的类?
1.首先这个类的所有实例对象都被回收了
2.这个类的class对象没有被引用,表示在任何地方都无法通过class对象反射出实例对象
3.这个类的类加载器被卸载回收了
这样就表示这个类再也无用了
下一篇:垃圾回收算法和垃圾回收器的详解















 187
187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









