







作者 Iris (PG深度爱好者)
业务背景
近期在支撑应用厂商从Oracle改造到PostgreSQL的改造工作,目前大部分O库业务表已经成功转化为PG表,应用厂商提出关于Oracle分区表迁移到PG分区表的改造方法和思路问题。由于应用业务数据每天产生大几千万数据,需要对每天的数据进行分区存储。业务表需要保留30天数据,30天之前的数据删除。
在原Oracle分区表设计中,以时间范围分区,区域为列表分区来创建混合分区。在分布式MYSQL数据库里可以通过时间范围分片规自动生成分片规则。在PG中分区表是通过表继承来实现的,创建一个空的主表,每个分区表按时间进行创建,去继承主表。
分区表介绍
数据库表分区把一个大的物理表分成若干个小的物理表,并使得这些小物理表在逻辑上可以被当成一张表来使用。
分区术语
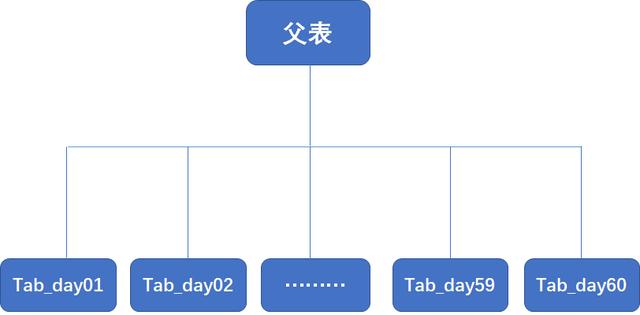
· 主表 / 父表 该表是创建子表的模板。可以理解为一个标准模板表,正常情况下它并不储存任何数据。
· 子表 / 分区表 / Child Table / Partition Table 子表继承并属于一个主表。子表中存储所有的数据。主表与分区表属于一对多的关系,一个主表包含多个分区表,而一个分区表只从属于一个主表
分区优势
· 分区后, 单个分区表的索引和表都变小了, 可以保持在内存里面, 适合把热数据从大表拆分出来的场景.
· 对于大范围的查询, 大表可以通过索引来避免全表扫描. 但是如果分区了的话, 可以使用分区的全表扫描. 适合经常要做大 范围扫描的场景, 按照范围分区(分区后采用全表扫描), 减少索引带来的随机BLOCK扫描.
· 大批量的数据导入或删除, 对于大表来说, 删除大量的数据使用DELETE的话会带来大量的VACUUM操作负担.而使用分 区表的话可以直接DROP分区, 或者脱离子表和父表的继承关系.
· 使用分区表,可以把不常用的分区放到便宜的存储上.
· 因为每个表只能放在一个表空间上, 表空间和目录对应, 表的大小受到表空间大小的限制. 使用分区表则更加灵活.
本地分区
范围分区:根据字段存储的值取值范围进行分区, 例如日志表的时间字段, 用户表的ID范围等等。
哈希分区:根据字段存储值HASH再做和分区数做比特运算得到一个唯一的分区ID. 或者取模.例如mod(hashtext(name),16), 对16个分区的场景。
list分区:与哈希分区类似, 但是直接使用字段值作为分区条件. 适合KEY值比较少并且比较均匀的场景.例如按性别字段作为分区字段. 那么就分成了2个区。
本地分区,子表继承表自动继承父表的约束, 非空约束. 但是不自动继承的是(uk,pk,fk,索引,存储参数等)。如果需要继承父表约束,需要添加like table_partition including all 参数。例如:CREATE TABLE tab_partition_2020_01_1 (like tab_partition including all) inherits (tab_partition);
创建分区表
创建本地分区表
创建父表
创建主标。限制应用数据1月份的数据插入到2020年1月份分区表中,也可以为主表创建约束条件和唯一键。
CREATE TABLE tab_partition
(
date_key date check(date_key>to_date('2020-01-01 00:00:01','yyyy-mm-dd hh24:mi:ss') and date_key
hour_key smallint,
client_key integer,
item_key integer ,
account integer,
expense numeric);
创建子表
创建多个分区表。每个分区表必须继承自主表,并且正常情况下都不要为这些分区表添加任何新的列。
CREATE TABLE tab_partition_2020_01_01 (like tab_partition including all) inherits (tab_partition);CREATE TABLE tab_partition_2020_01_02 (like tab_partition including all) inherits (tab_partition);CREATE TABLE tab_partition_2020_01_03 (like tab_partition including all) inherits (tab_partition);CREATE TABLE tab_partition_2020_01_04 (like tab_partition including all) inherits (tab_partition);
CREATE TABLE tab_parti
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3742
3742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









