





前言
- 本文为练手记录,适用于刚入门的朋友参照阅读练习,大神请绕道,谢谢!
- 阅读大约需要10分钟。
一、理解项目概况并提出问题
1.1 登陆官网查看项目概况
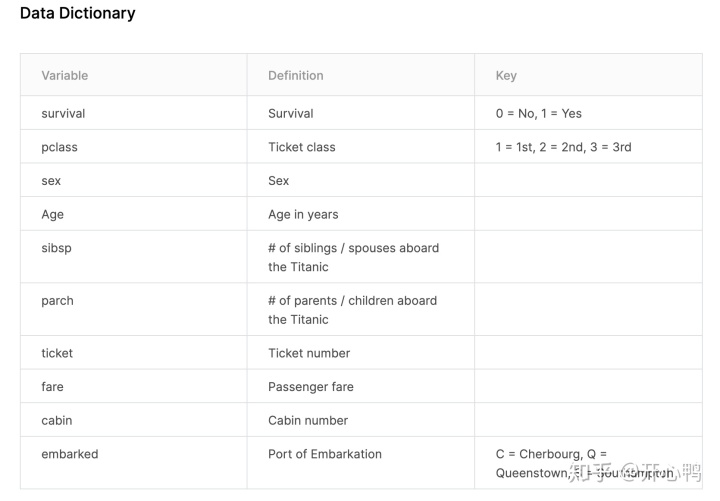
Titanic: Machine Learning from Disasterwww.kaggle.com变量解释:
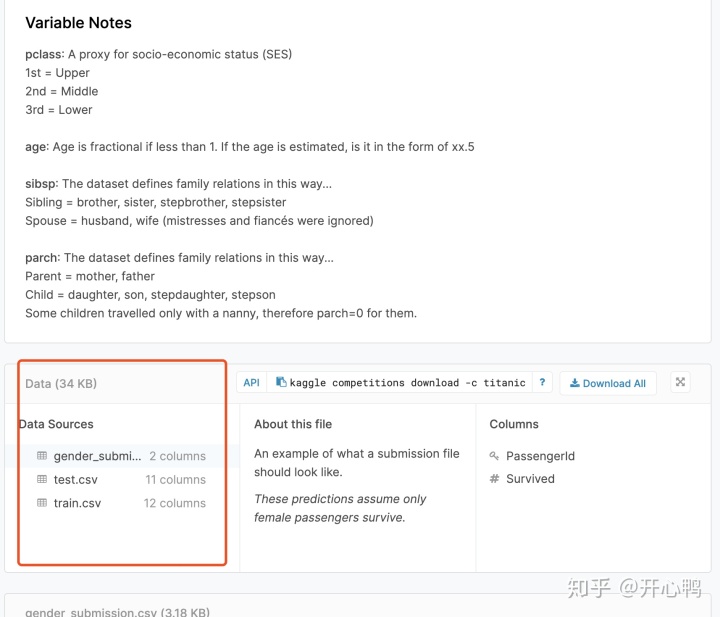
下载三个数据集,测试数据,训练数据和预测数据。
1.2 整体思路
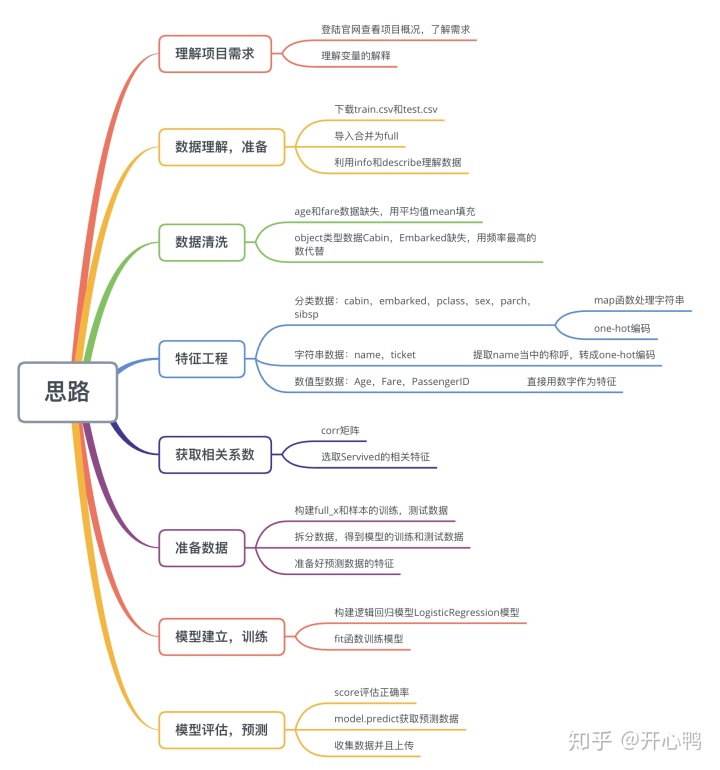
1.3 提出问题
1)有没有可能一些特定的人群如妇女儿童会比大多数人更容易存货?
2)不同等第仓存货概率是不是不同?
3)生存概率和年龄有关系吗?
4)生存概率会不会收到家庭成员多少的影响?
二、数据理解、准备
2.1 数据查看、合并

首先我们通过pandas的read_.csv函数来导入两个csv然后用shape函数看看行列。

通过train.append()来合并数据集。
合并的原因是因为训练数据特征要和测试数据特征一致。
我们发现测试数据集比训练数据集少一行是因为少了survive,这个参数是最后需要和预测数据集比对查看正确率的,所以会缺失。合并时忽略在appen参数加上ignore_index=True用NaN填充。

合并成功
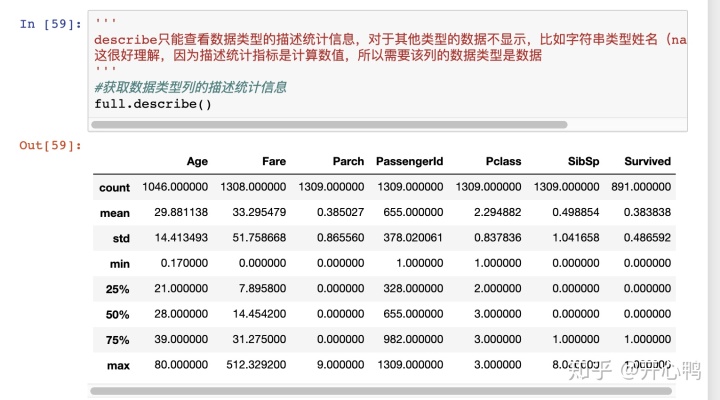
我们通过describe()来查看数据类型的描述统计信息
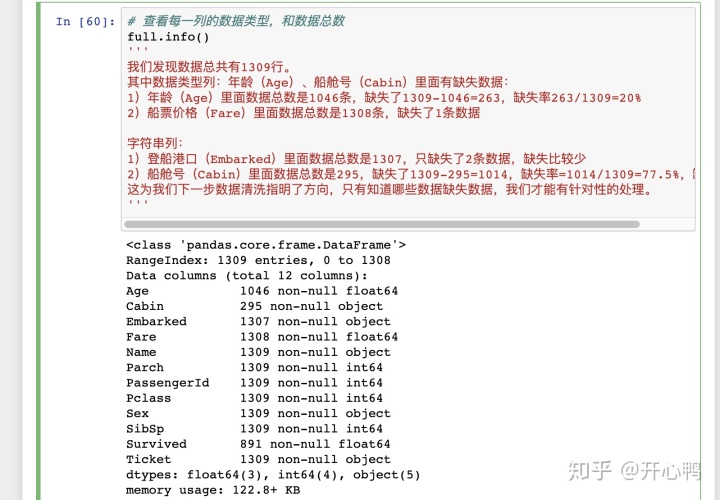
用info函数查看所有列的行,可以查看缺失情况,为进一步数据清洗做准备。
2.2 通过可视化理解数据
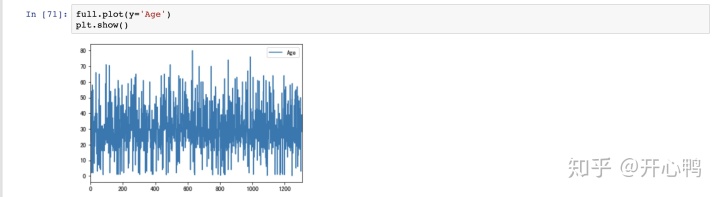
我们对所有人的年龄进行可视化,发现年龄差距比较大。
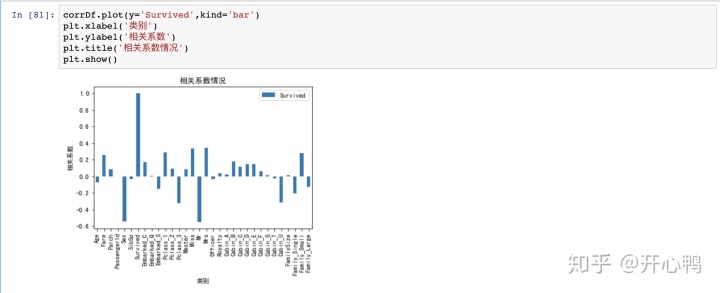
我们对相关系数进行可视化,可以明显的看出一些参数的正相关和负相关性大小,方便我们选取变量。
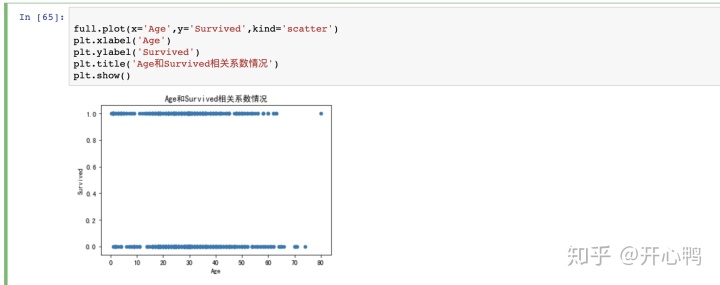
我们也可以通过散点图发现年龄和生存率关系不是很大,和上图相关系数所呈现的信息保持一致。
三、数据清洗,准备
3.1 处理float64缺失值:Age,Fare
对于数值型数据我们直接用平均值填充
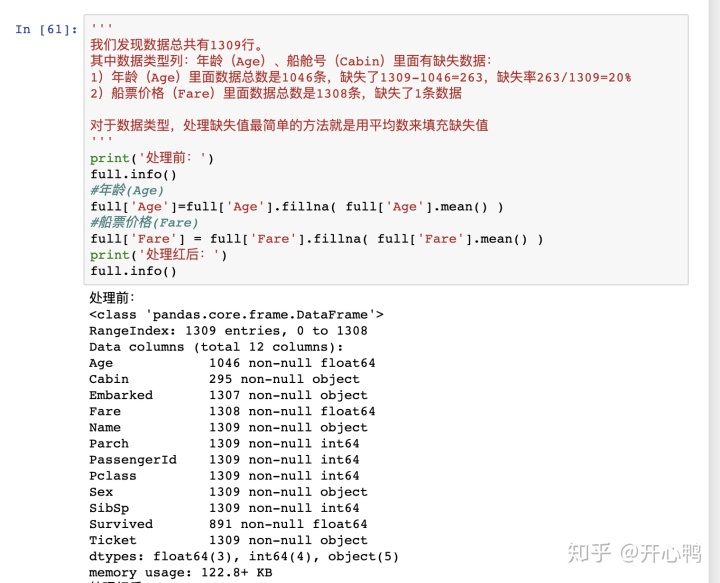
full['Age']=full['Age'].fillna(full['Age'.mean()])
full['Fare']=full['Fare'].fillna(full['Fare'.mean()])3.2 处理object缺失:Cabin,Embarked
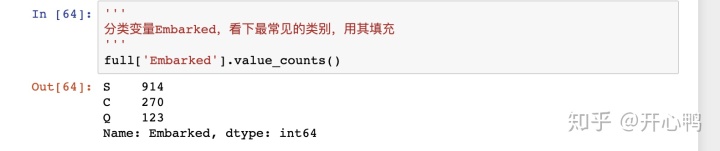
用value_counts()函数来查看每个属性总和发现S最多,我们就用S填充

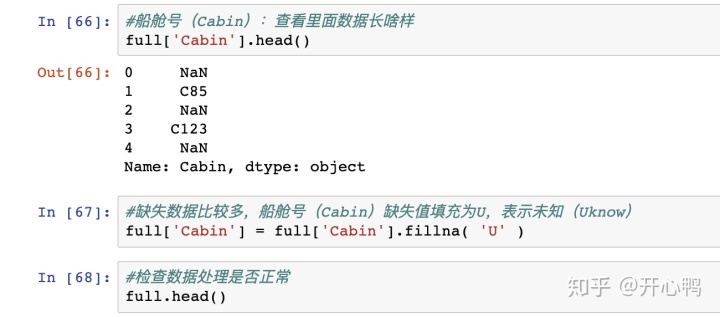
发现还存在控制,我们用U来表示未知。

用http://full.info()查看发现所有数据已经填充完毕
四、特征工程
数据分析当中核心就是提取数据特征,因为数据特征代表了和数据结果的联系。
4.1 对各个变量进行分类
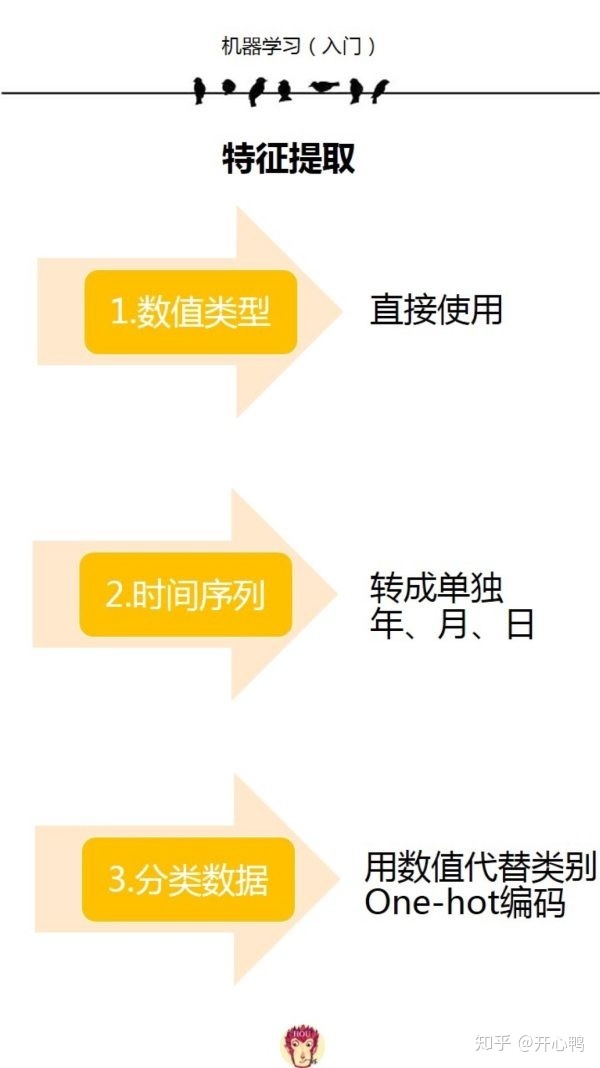
而具体提取数据特征的步骤大致为:
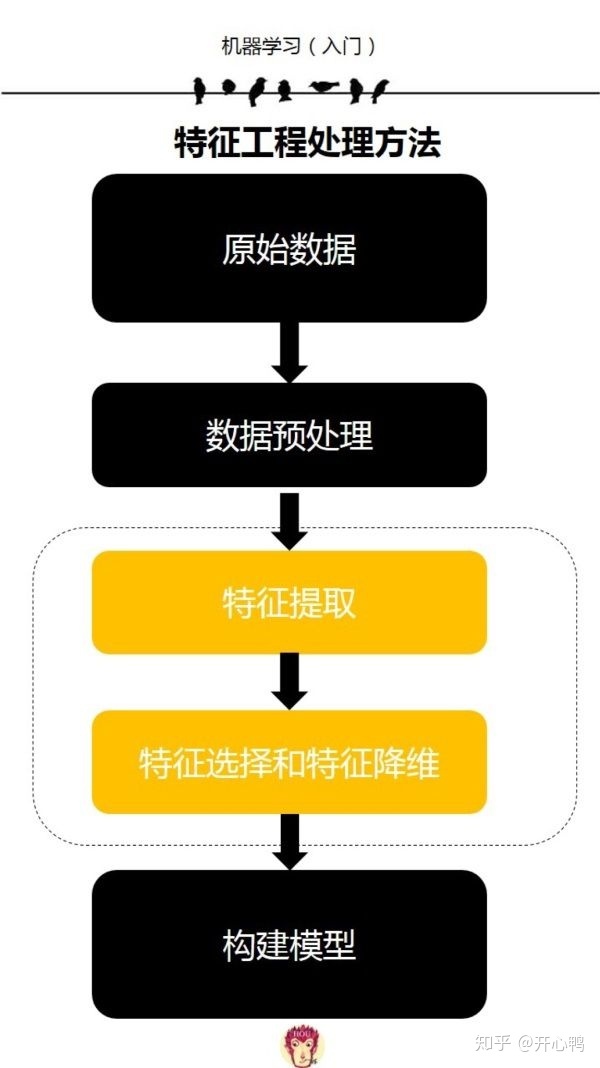
4.2 分类数据特征提取
分类数据主要有Sex,Cabin,Embarked,Pclass,Parch,SibSp,下面逐个清理。
1、性别
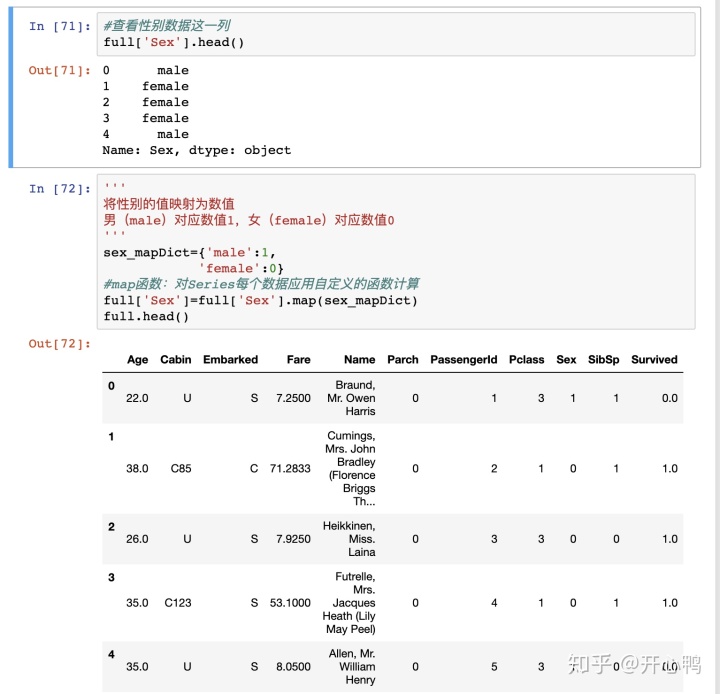
我们发现这里的性别是用male和female,我们要将其转换成0,1.
首先定义映射的字典,
sex_mapDic={'male':1,
'female':0}
通过map函数让每个数据进行自定义函数计算
full['Sex']=full['Sex'].map(sex_mapDict)
2、登陆港口Embarked

我们首先用创建DataFrame()二维数据表,之后用get_dummies(full['Embarked',prefix='Embarked'])来进行one-hot编码存入二维表中。
(3)船舱等级Pclass

客舱等级也是一样的步骤。
(4)船舱号Cabin

这里有一个知识点是lambda函数

直接定义:landba c:c[0]
代表输入c输出c[0] 非常简单粗暴
(5)Parch,SibSp数据
接下来处理Parch,SibSp数据,先理解下这两个数据是什么意思。
SibSp:表示船上兄弟姐妹数和配偶数量,理解为同代直系亲属数量,
Parch:表示船上父母数和子女数,理解为不同代直系亲属数量。
所以FamilySize等于=本人+sibsp+parch
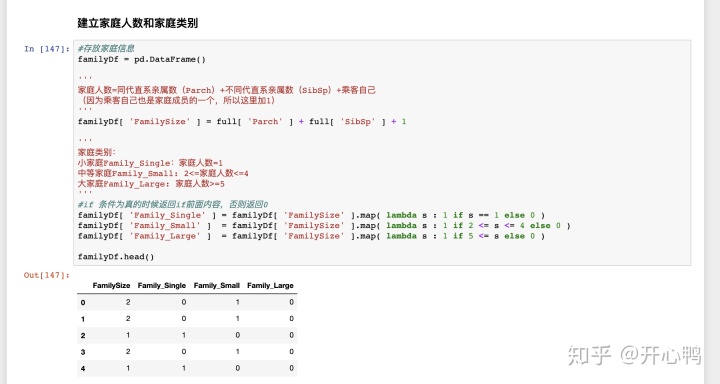
这里和前面不同的是,前面可以直接1 2 3 等仓用特征提取函数,这里要进行范围划分所以要自己产生列,然后用map函数映射修改。
且这里的lambda函数有所不同用到了一个if判断,写法是if为真结果放前面,为假else结果放后面。
lambda s :1 if s==1 else 0
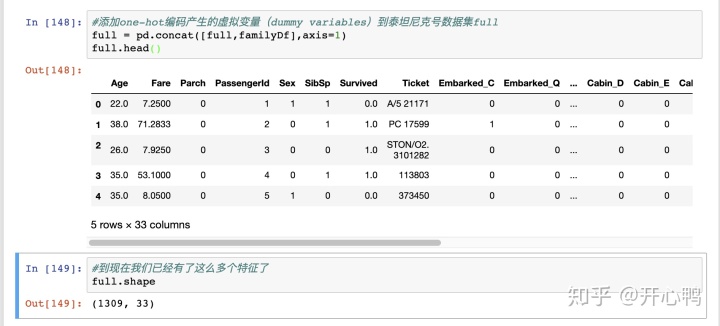
合并后发现已经有33个特征了
4.3 字符串数据提取特征
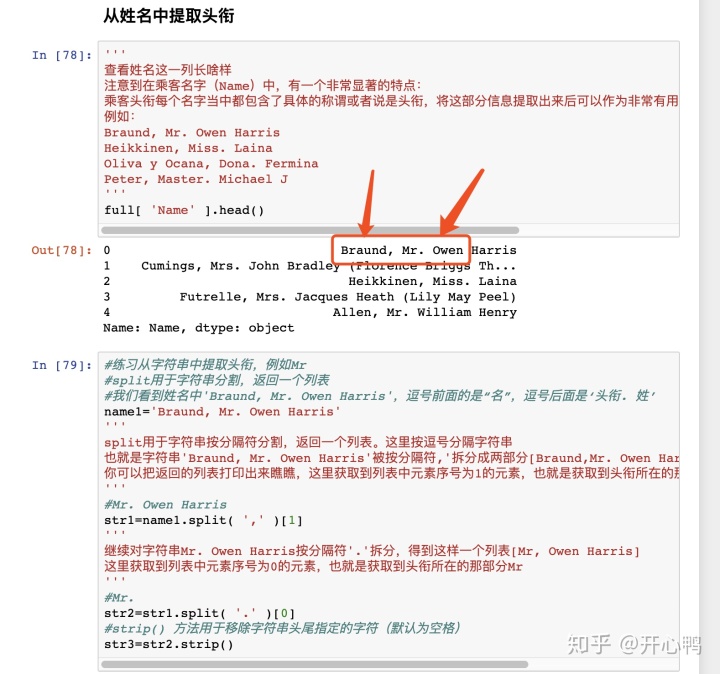
提取姓名的时候逗号前面是名字,逗号后面句号前面的是称谓所以我们要用split函数提取两次。
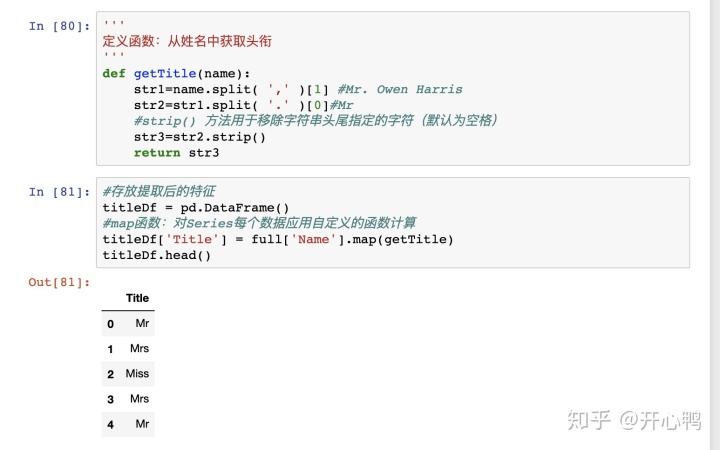
定义一个函数同样用map映射批量修改。
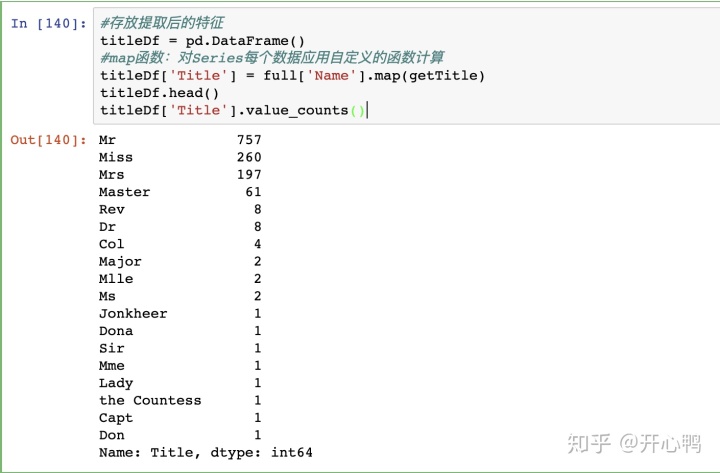
发现老外的称谓真的很多
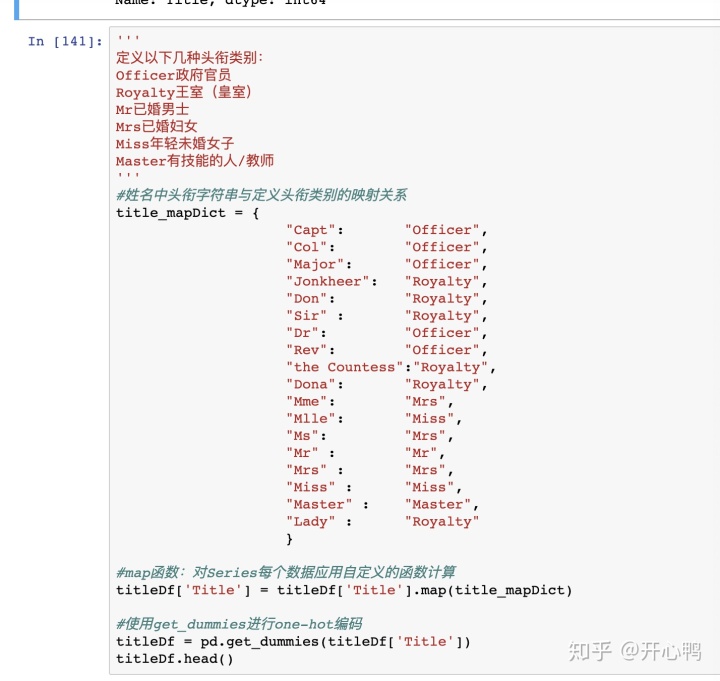
定义数据字典,转换onehot,重复的工作挺多。
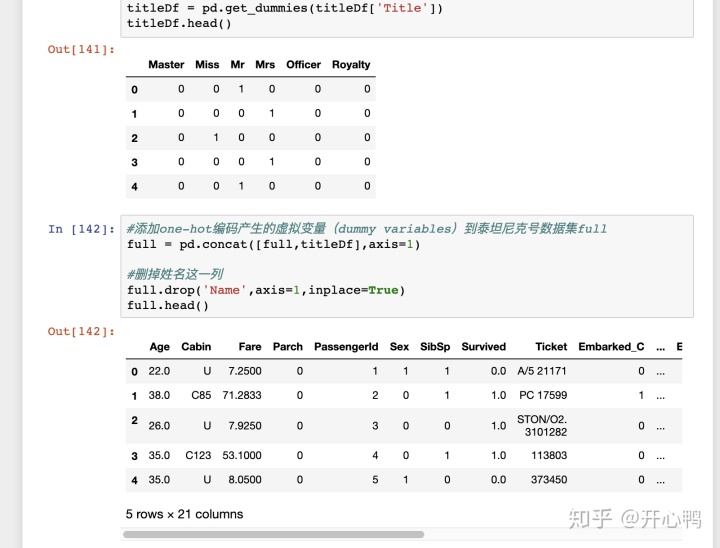
五、获取特征相关性
5.1 获取corr矩阵
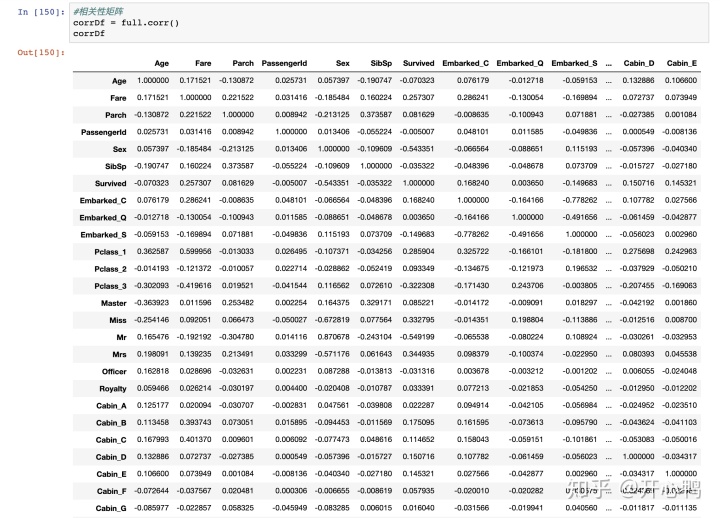
因为我们最终结果要知道是否生存,所以看survived这一列的相关性即可。
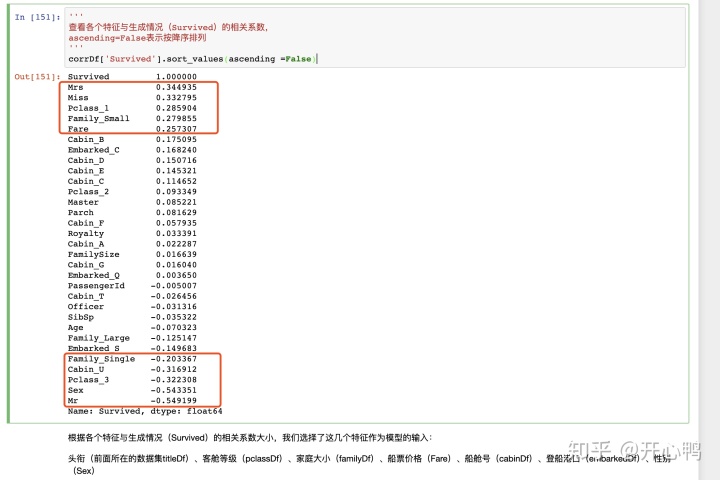
发现方框内几列呈现正负相关性非常的强
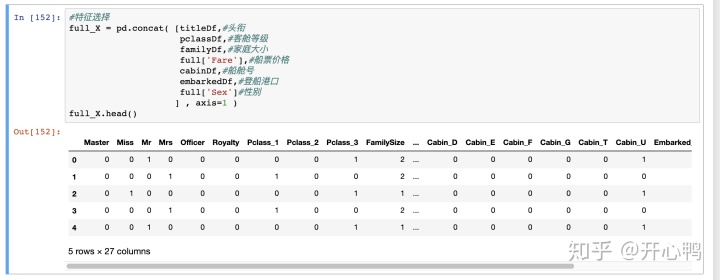
于是乎我们组合这几列27个影响因子。
六、准备数据

这里要清楚特征是我们提取的影响生存数的因素,标签是生存数。
预测数据集在891行之后要进行区分。
七、模型建立、训练
用sklearn的linear_model的逻辑回归算法建立模型,并开始用拆分好的数据进行训练:
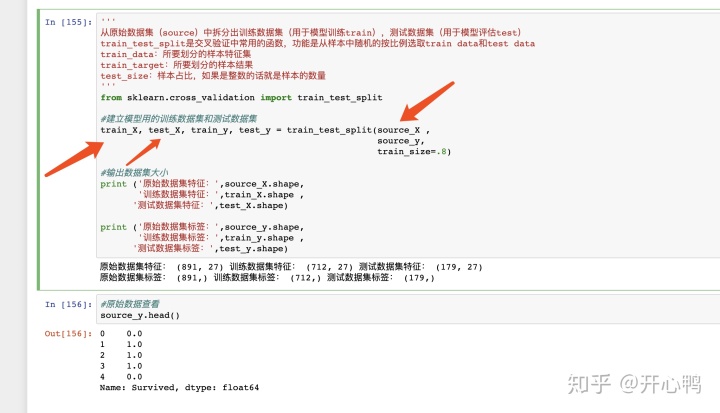
可以看到我们把原始数据以28分,分成训练数据和测试数据。

通过model.fit(train_x,train_y)进行训练
八、模型的评估、预测
8.1 模型正确率评估

输入model.score(test_x,test_y) 输入测试特征和标签进行评估分数
8.2 用模型进行预测,并按要求输出
将前面准备的预测数据特征pre_x,用模型的predict方法预测生存数据pre_y,并整理成整数型int数据

8.3 提交
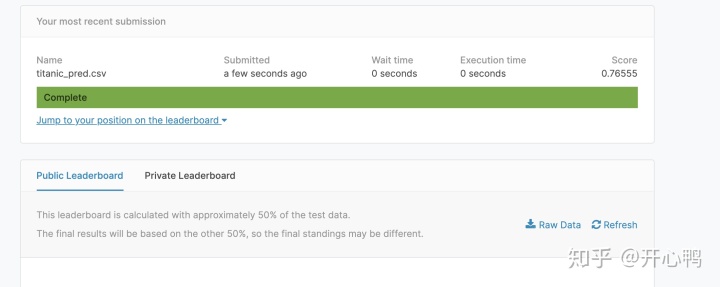
提交后我们就会看到我们的排名和成绩
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









