





一、原因:
在用beutifulsoup爬取网页的信息时,我们会遇到信息变成乱码的情况,之所以出现这种情况,是因为requests和beautifulsoup模块都会自行评测原网页的编码格式。
二、解决办法:
(1)查看网页编码格式:
既然要将soup中编码格式改为正确的,那我们首先就要知道你要爬取的网页编码格式是什么。
首先是F12—>到控制台Console—>输入document.charset。
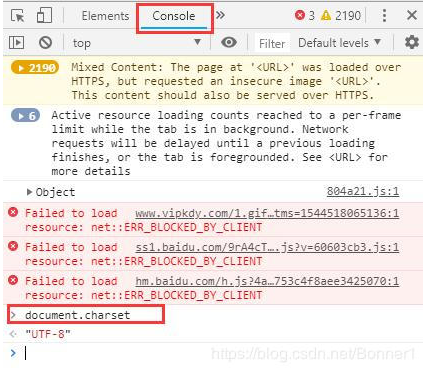
此处的utf-8就是该网页的编码格式。
(2)修改爬取时的编码格式:(这里是改为utf-8)
import requests
from bs4 import BeautifulSoup
html = requests.get("http://www.baidu.com/")
html.encoding='utf-8'//将编码格式改为utf-8
soup = BeautifulSoup(html.text,'lxml')
print(soup.XX)
(3)关于中文乱码:
BeautifulSoup在解析utf-8编码的网页时,如果不指定fromEncoding或者将fromEncoding指定为utf-8会出现中文乱码的现象。
解决此问题的方法是将Beautifulsoup构造函数中的fromEncoding参数的值指定为:gb18030
importurllib2
fromBeautifulSoupimportBeautifulSouppage =urllib2.urlopen('http://outofmemory.cn/');soup =BeautifulSoup(page,fromEncoding="gb18030")printsoup.originalEncoding
printsoup.prettify()















 2581
2581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









