





深交所网站上的这个分省统计数据是提供下载的,但是要一个一个月的点击下载有点麻烦,这个数据每个月有两页,从2004年12月开始有完整数据,一直到2019年11月。
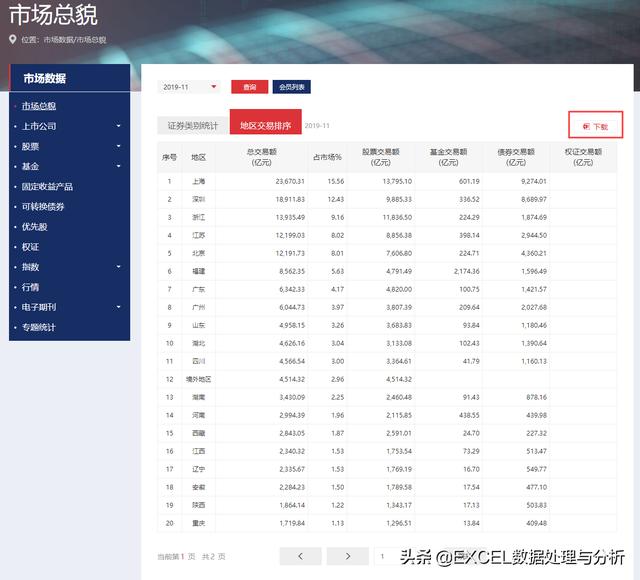
我们一直以来网络抓取的四步:
- 网站分析
- 试抓
- 定义抓取函数
- 抓取
第一步:网站分析
今天我们把这个网站分析说的详细一点,要用谷歌浏览器打开,我们打开这个网页之后,先右键检查,在network中按CTRL+R:
加载数据,相当于刷新数据。
然后我们要在网页上操作几步,例如:
选择月份、选择页码,这样在左边栏中就会有操作记录:
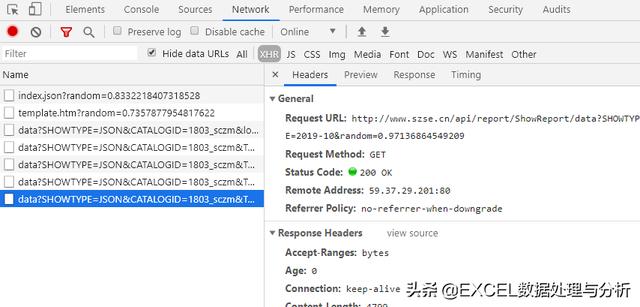
data?这几行就是我们操作返回的结果,依次点开我们就能在右边看到不同的内容:
我们要关注的地方:
Headers:
最上面的General里
- Request URL:是真实地址
- Request Method:是查询的方法,这里是GET
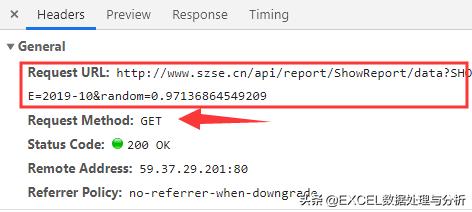
之前讲过GET与POST就在这里区分。
Request String Parameters:
这里是查询要传递给服务器的信息,下面这个格式是为了我们查看方便,按照记录的格式显示出来:
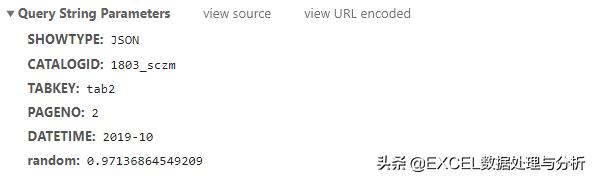
如果我们按下View source:

这一长长字符串,其实就是真实地址中的问号后面内容。
这个字符串的含义是这样的:我们要求服务器返回一个JSON格式的数据包,分类是1803_sczm,猜测一下“市场总貌”是不是就是拼音头,我们要市场总貌标签2的内容,页码是第二页,时间是2019-10,最后是一个随机数。
我们到网页上对应一下:
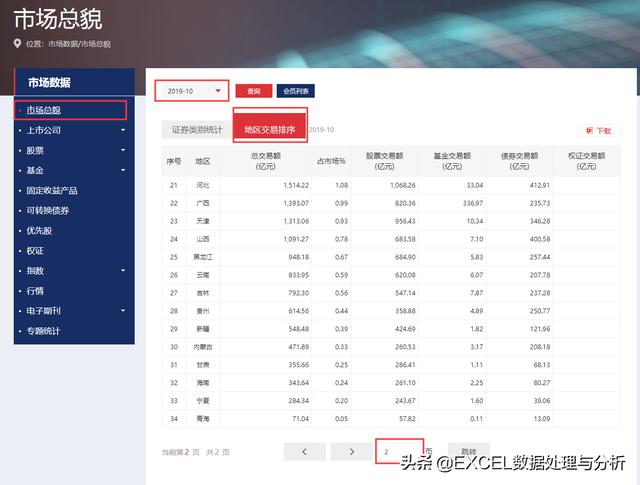
查询的基本信息都在这个字符串中了。
我们还要来看一下JSON数据预览,看看是不是我们需要的内容:
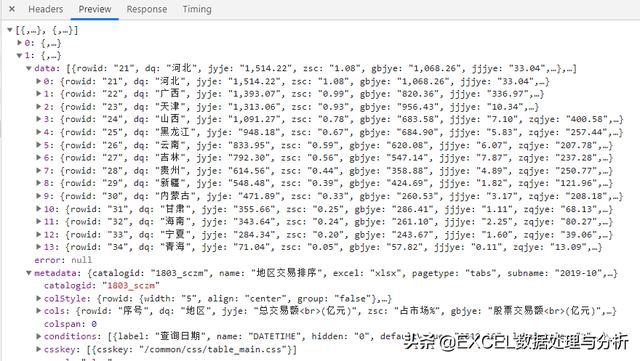
与页面上的主要数据基本一致,应该就是我们要抓取的内容。
通过上面的分析,我们知道,只要改变查询字符串中的页码与月份我们就可以抓取到不同月份不同页码的数据,是不是这样呢?我们要在第二步试抓中来验证。
第二步:试抓
试抓这一步说简单也不简单,在这一步我们要掌握一个度,数据可以适当处理,不能过度处理,尽量保证抓取过程的通用性,减少个性化的数据处理,简单来说就是要有容错能力,否则抓取的过程就会卡在个性化的处理步骤上。
我们复制真实URL,从WEB获取数据:
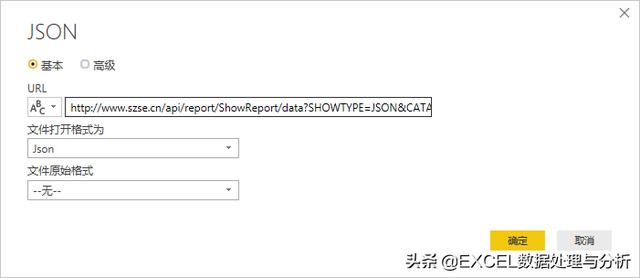
然后就得到一份解析的JSON数据:
这个数据结构,我们可以通过谷歌浏览器里的预览来了解,也可以直接在这个结果中探索一下,看看每个分支的内容都是什么,我们需要的内容在哪里?
把记录转成表格并不困难,稍有点难度的是把中文的表头添加好:
在展开表格的时候我们要把汉字的表头顺手处理好,JSON里有两个分支:
- data:就是我们要的数据
- metadata:中有我们要的汉字表头,具体的位置在cols里
表头完整的内容:

在我们的查询中前面的一大串,定义为源,那么表头就是:
源{1}[metadata][cols]
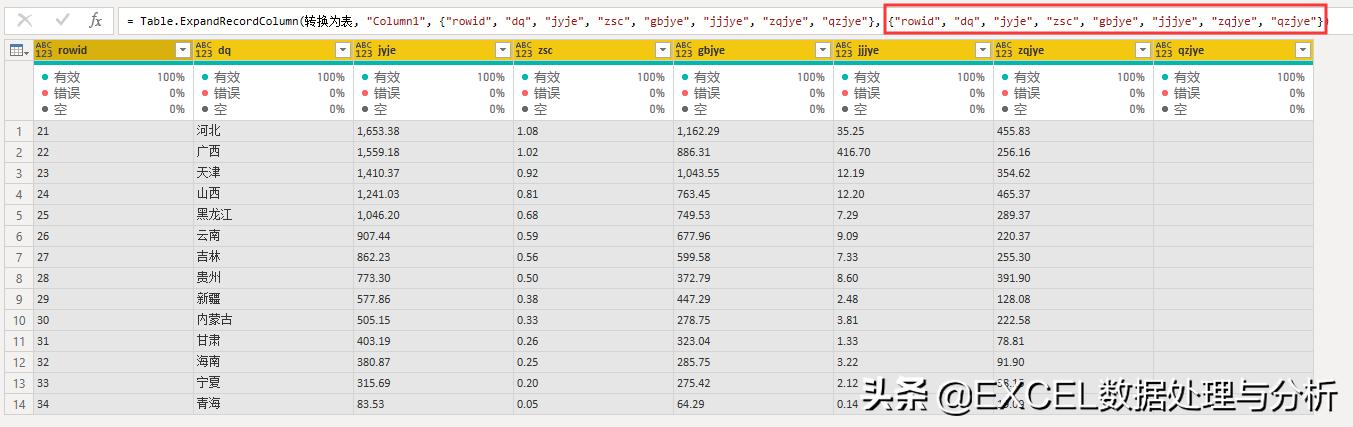
再来看数据表展开后的样子:
直接展开,我框起来的部分就是命名列名称的列表,我们要做的就是把中文的记录表头转化成一个文本列表,替换掉框起来的部分就可以了。
要用到两个函数
- List.ReplaceValue:替换列表中内容,表头中有
,需要替换掉 - Record.ToList:记录转列表
List.ReplaceValue(
Record.ToList(源{1}[metadata][cols]),
"
","",
Replacer.ReplaceText)
List.ReplaceValue稍微复杂一点,有4个参数:
- 第一个参数是源列表,我们用Record.ToList生成列表
- 第二个参数是源字符串
- 第三个参数是新字符串
- 第四个参数是指定替换类型
我们把这个公式放到展开表格的函数中就可以了:
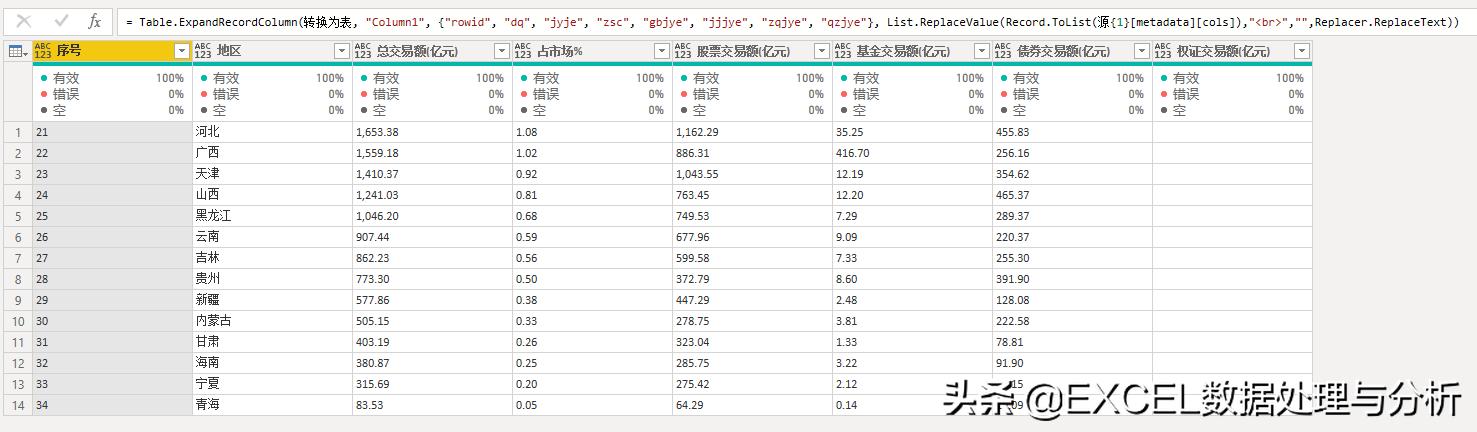
这样我们就完成了一次试抓,我们可以尝试修改其中的页码与月份,来看看试抓结果如何变化:
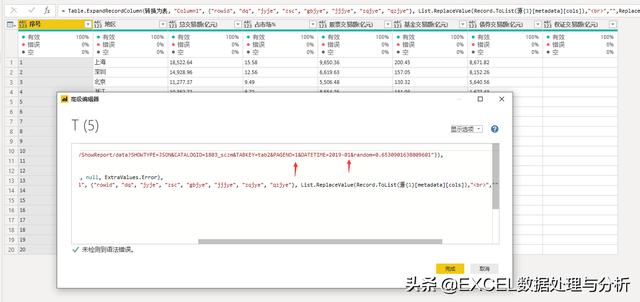
我们改成页码1月份2019-01也成功抓取到数据,这里要提醒大家,一定要注意的细节,是2019-01不是2019-1,我刚开始的时候就卡在这里,生成的月份不是2位的月,结果导致抓取出错。上面的过程基本能够确定我们的试抓成功,可以开始定义函数了。
第三步:定义抓取函数
在我们成功抓取的那份查询上右键,创建函数,然后修改参数,我们要用到两个参数:
- p:页码
- m:月份
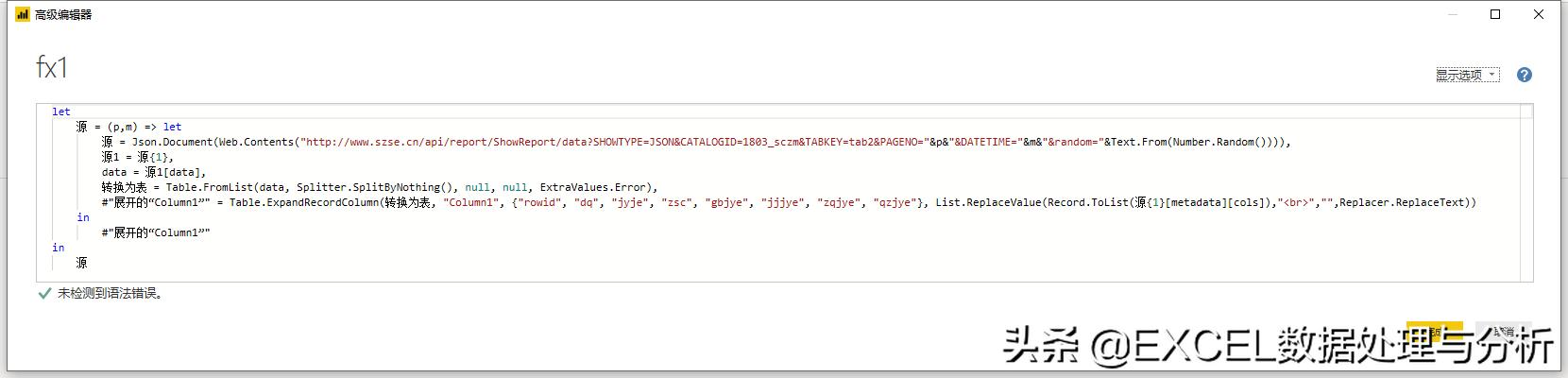
其他的步骤我们不用管,只在第一句中做修改,图片可能不清楚,我复制出来:
源 = Json.Document(Web.Contents("http://www.szse.cn/api/report/ShowReport/data?
SHOWTYPE=JSON&
CATALOGID=1803_sczm&
TABKEY=tab2&
PAGENO="&p&"&
DATETIME="&m&"&
random="&Text.From(Number.Random()))),
这样是不是就看的很清楚了,我们实际上修改了三处,
PAGENO="&p&"&
DATETIME="&m&"&
random="&Text.From(Number.Random()))),
最后一个是随机数,为了确保抓取顺利进行,我们用Number.Random()生成随机数,避免因为同一个随机数,被服务器踢出来。
函数写好以后,也可以输入两个参数,测试一下:
我没用Text.From函数,所以输入的时候费点劲,要用引号表示参数是文本:
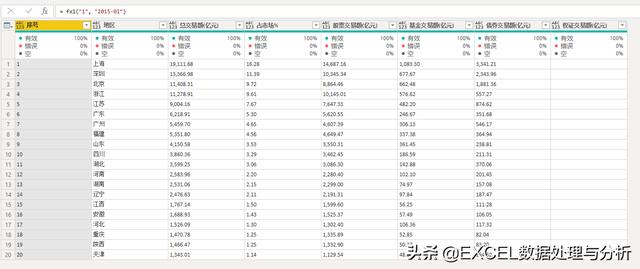
记住,我们的参数是文本,一会我们抓取的时候,构造序列时要记得转换成文本格式。
第四步:抓取
首先我们要构造一个表,有两列,
- 一列是p
- 一列是m
我们用最简单的办法,先做两个单列的表:

然后我们做一个年的列表:
添加自定义列:
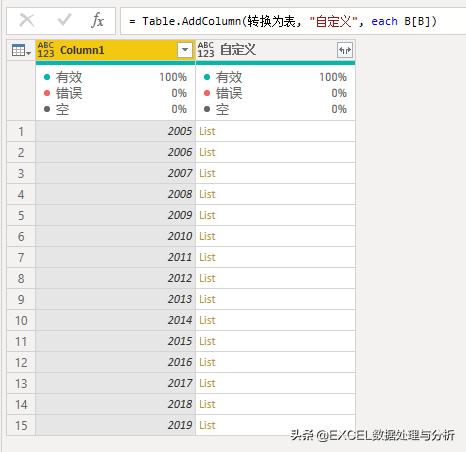
展开列表,就得到年和月份对应的表:
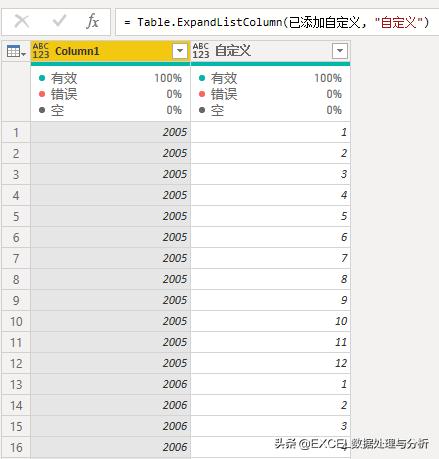
再添加自定义列:
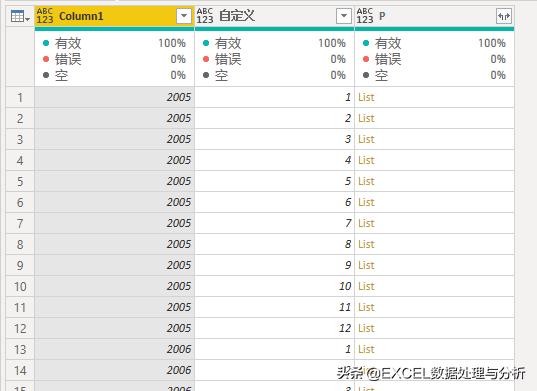
再展开列表,得到与页码对应的表:
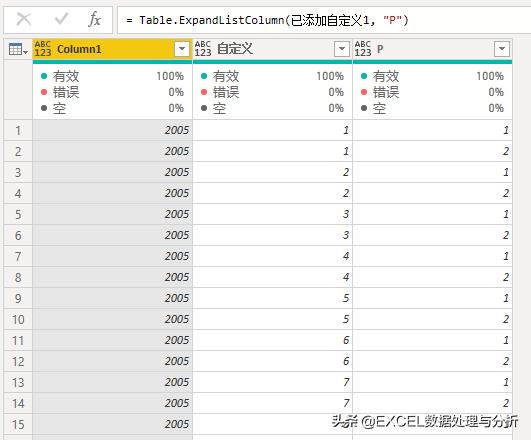
然后我们合并年月:
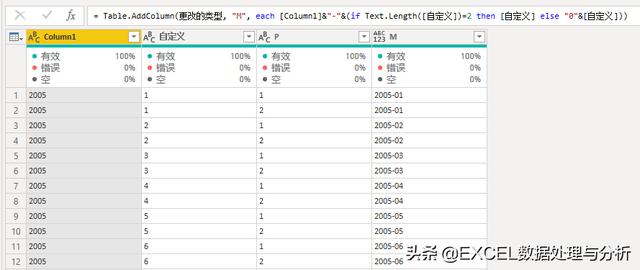
删除不要的列,改变类型为文本:
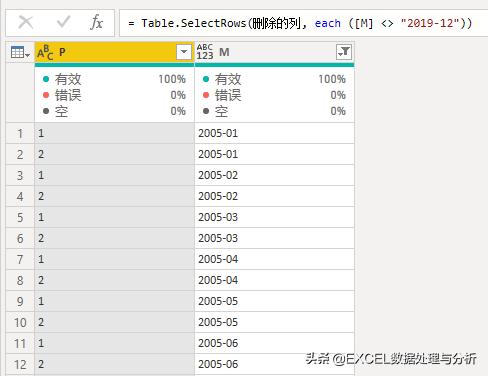
为了防止出错,要筛选掉2019-12,因为没有数据。
然后我们就可以开始用函数抓取了:
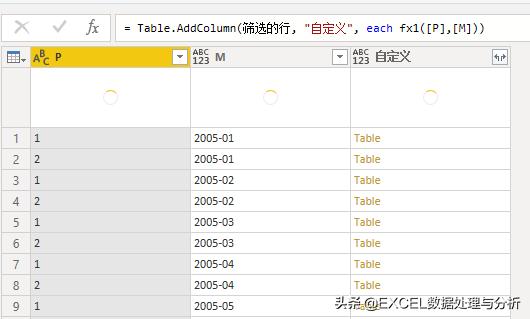
展开表,整理数据:
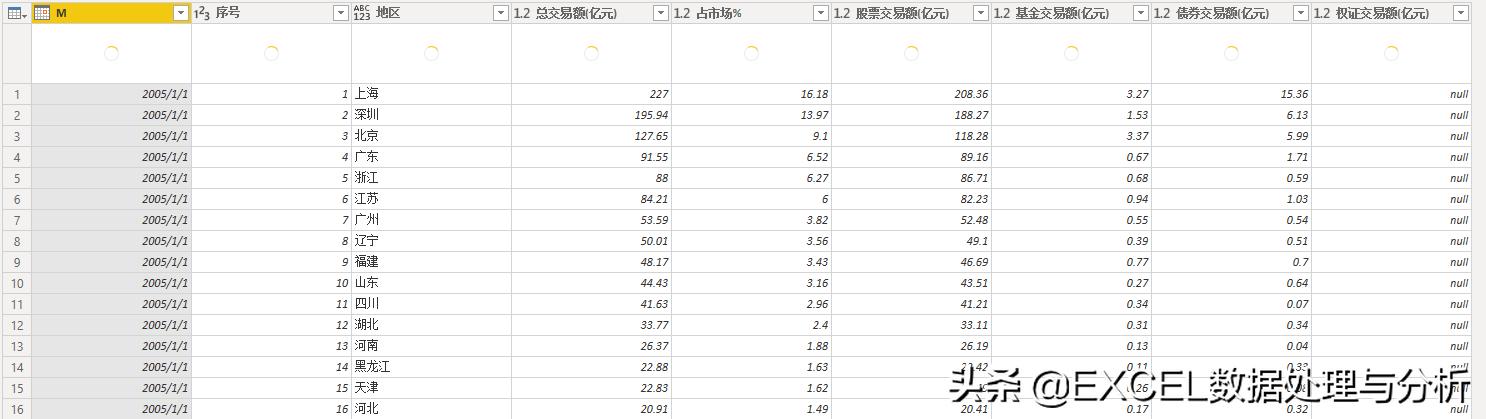
最后就是加载数据了。
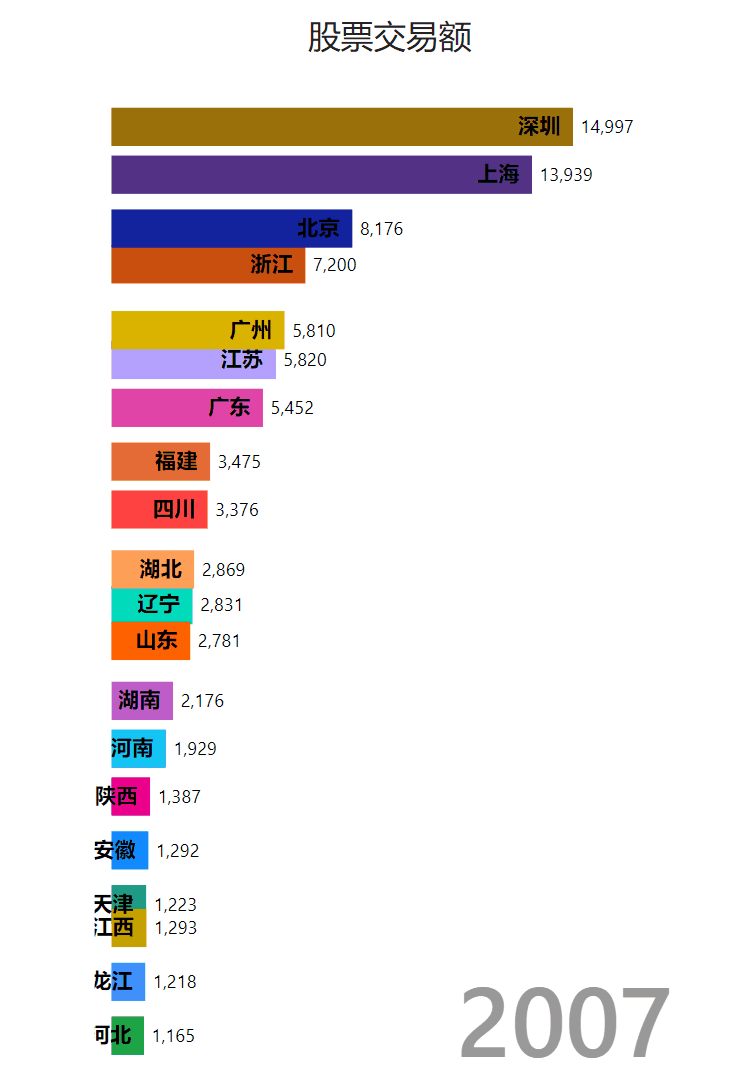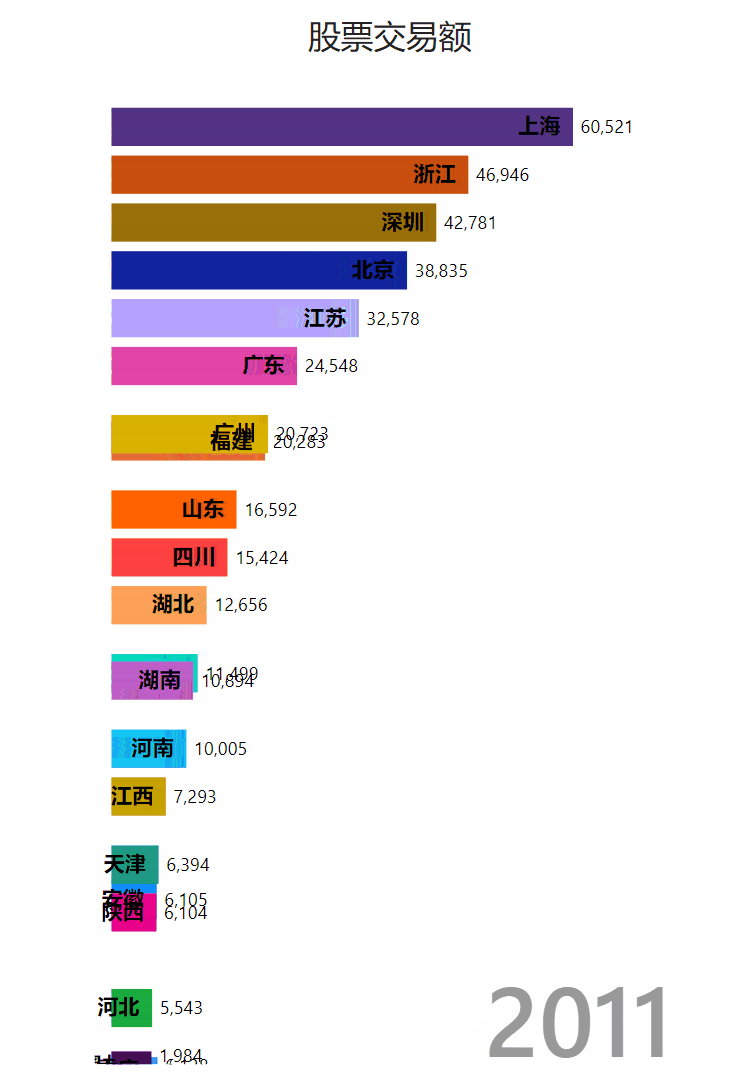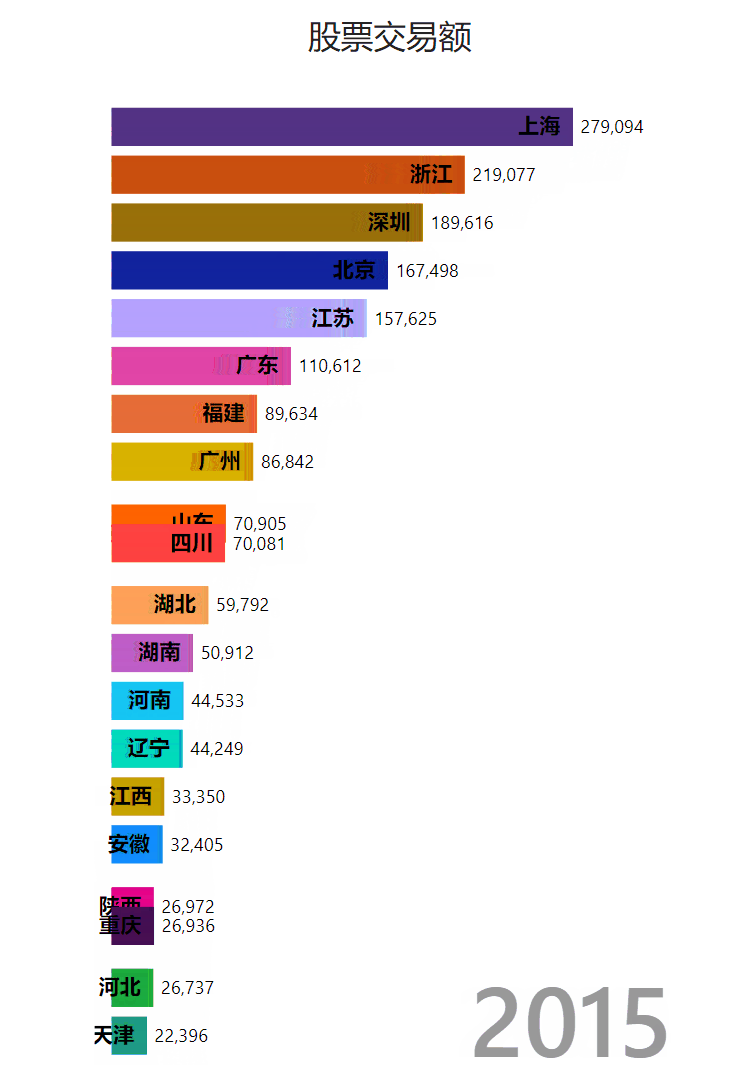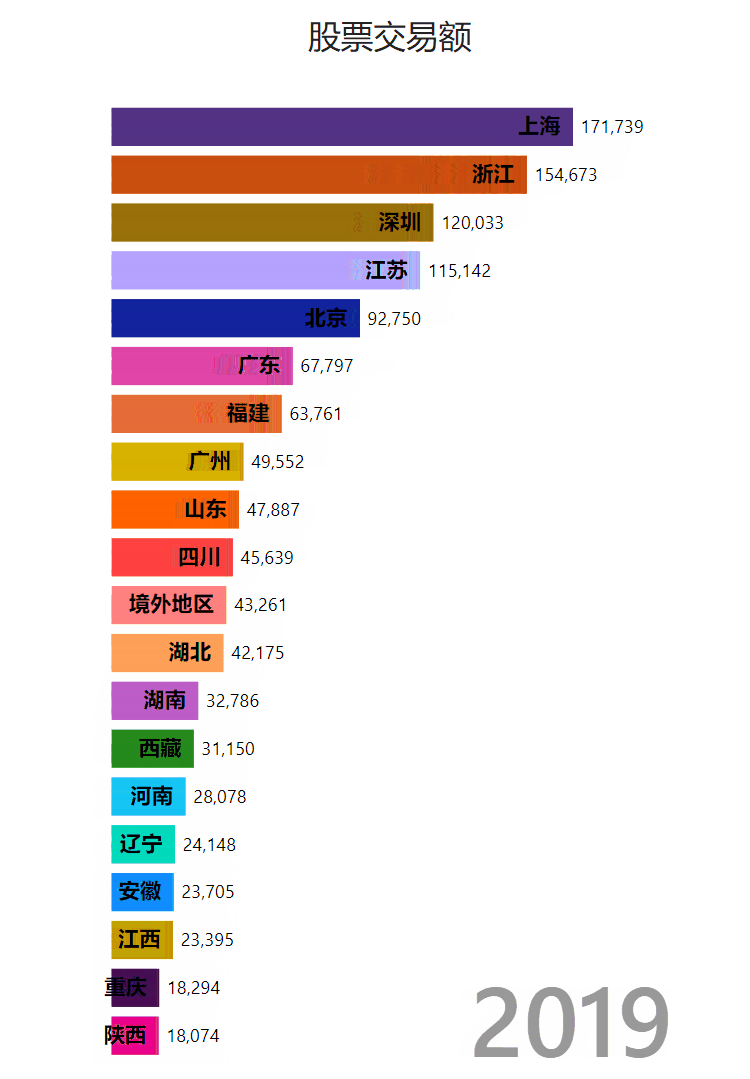
做了一个树图柱图:















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









