





点击蓝字关注我们

有小朋友提出了这个需求,今天就来实践一下~
这里有视频教程:
https://www.bilibili.com/video/av94574531/
1.先明确目的——今天想实现这个功能
得到知网上所有和吸烟相关的文献信息,如下,包括文章标题,作者信息,被引频次,下载次数,关键词,摘要信息。
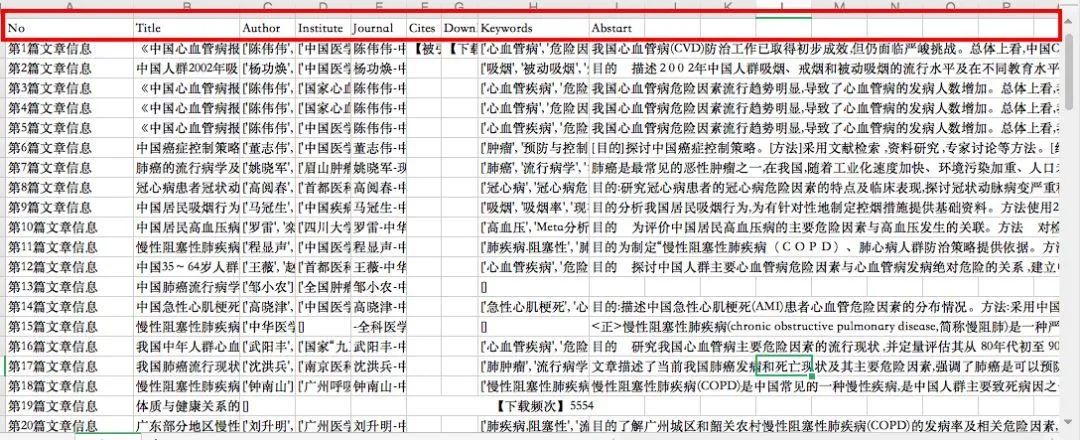
要是一个一个搜,那要查到天荒地老嘛?!
有python怕啥?!不要慌
2.动手之前先动脑(噗,思考)
step1: Google,或者搜索简书,用关键词,“Python 知网”,居然有现成的轮子,有python基础的,你可以直接领取代码哦
step2: 不必重复造轮子……那当下开始干吧,也不是啥大不了的活hhhh
在你的数据分析环境下要先安装用到的包包哦,一般pip3 install 就可以了
你需要修改这几个地方:
pagestart = 1 #起始页pageend = 6 #结束页keywords = '吸烟' ### 查询的主题wb.save('/Users/cici/Desktop/Smoking_CNKI.xlsx') # 最后保存搜为了节约您宝贵的时间,现将代码奉上:
#!/usr/bin/env python3# -*- coding:utf-8 -*-# Author:cici# -加载将会使用到的函数库import requests # 读取网页from lxml import etree # 用于解析网页from openpyxl import Workbook # 创建表格并用于数据写入from bs4 import BeautifulSoup # 解析网页import random # 随机选择代理Ip# --获得代理IP列表def get_ip_list(urlip, headers2): web_data = requests.get(urlip, headers=headers2) soup = BeautifulSoup(web_data.text, 'lxml') ips = soup.find_all('tr') ip_list = [] for k in range(1, len(ips)): ip_info = ips[k] tds = ip_info.find_all('td') ip_list.append(tds[1].text + ':' + tds[2].text) return ip_list# -从代理IP列表里面随机选择一个def get_random_ip(ip_list): proxy_list = [] for ip in ip_list: proxy_list.append('http://' + ip) proxy_ip = random.choice(proxy_list) proxies = {'http': proxy_ip} return proxies# -定义获取文章列表对应的链接的函数def get_data(urllist, headers, proxies): j = 0 # 初始化j的取值 for urli in urllist: try: j = j + 1 num = 15 * (i - pagestart) + j # 第多少篇 test = str(urli) # 是否使用代理去爬虫就在下面这一行代码中,是否添加:proxies=proxies f = requests.get(test, headers=headers) # 设置Headers项; 这里添加是否使用代理去访问: ftext = f.text.encode(f.encoding).decode('utf-8') # 对具体进行转码,获得可以正常读取的文档; ftext_r = etree.HTML(ftext) # 对具体页进行 xpath 解析; ws.cell(row=num + 1, column=1).value = '第' + str(num) + '篇文章信息' ws.cell(row=num + 1, column=2).value = str(ftext_r.xpath('//title/text()')[0]).replace(' - 中国学术期刊网络出版总库', '') # 获得文章标题 ws.cell(row=num + 1, column=3).value = str( ftext_r.xpath('//div[@]/p[1]/a/text()')) # 获得作者名字 # --------------------------- if len(ftext_r.xpath('//ul[@]/li/text()')) == 3: ws.cell(row=num + 1, column=6).value = ftext_r.xpath('//ul[@]/li[2]/text()')[0] ws.cell(row=num + 1, column=7).value = ftext_r.xpath('//ul[@]/li[3]/text()')[0] if len(ftext_r.xpath('//ul[@]/li/text()')) == 4: ws.cell(row=num + 1, column=6).value = ftext_r.xpath('//ul[@]/li[3]/text()')[0] ws.cell(row=num + 1, column=7).value = ftext_r.xpath('//ul[@]/li[4]/text()')[0] if len(str(ftext_r.xpath('//div[@]/p[2]/a/text()'))) == 2: ws.cell(row=num + 1, column=4).value = str( ftext_r.xpath('//div[@]/p[3]/a/text()')) # 获得作者单位 else: ws.cell(row=num + 1, column=4).value = str( ftext_r.xpath('//div[@]/p[2]/a/text()')) # str(ftext_r.xpath('//div[@]/p[2]/a/text()')) ws.cell(row=num + 1, column=5).value = ftext_r.xpath('//div[@id="weibo"]/input/@value')[0] # 第一作者及所属刊物及时间 ws.cell(row=num + 1, column=8).value = str(ftext_r.xpath('//span[@id="ChDivKeyWord"]/a/text()')) # 文章关键词 ws.cell(row=num + 1, column=9).value = ftext_r.xpath('//span[@id="ChDivSummary"]/text()')[0] # 获得文章摘要 print('爬虫' + str(15 * (pageend - pagestart + 1)) + '篇文章信息的第' + str(num) + '篇爬取成功!!') except: print('爬虫第' + str(i) + '页中的第' + str(j) + '篇爬虫失败') # ---创建表格,待接收数据信息---#wb = Workbook() # 在内存中创建一个workbook对象,而且会至少创建一个 worksheetws = wb.active # 获取当前活跃的worksheet,默认就是第一个worksheetws.cell(row=1, column=1).value = "No"ws.cell(row=1, column=2).value = "Title"ws.cell(row=1, column=3).value = "Author"ws.cell(row=1, column=4).value = "Institute"ws.cell(row=1, column=5).value = "Journal"ws.cell(row=1, column=6).value = "Cites"ws.cell(row=1, column=7).value = "Download"ws.cell(row=1, column=8).value = "Keywords"ws.cell(row=1, column=9).value = "Abstart"# ---------------参数设置if __name__ == '__main__': pagestart = 1 #起始页 pageend = 6 #结束页 keywords = '吸烟' ### 查询的主题 url = 'http://search.cnki.net/search.aspx?q=' + str(keywords) + '&rank=citeNumber&cluster=all&val=CJFDTOTAL&p=' urlip = 'http://www.xicidaili.com/nt/' # 提供代理IP的网站 headers = { 'Referer': 'http://search.cnki.net/search.aspx?q=qw:%e7%b2%be%e5%87%86%e6%89%b6%e8%b4%ab&cluster=all&val=&p=0', 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36', 'Cookie': 'cnkiUserKey=158f5312-0f9a-cc6a-80c1-30bc5346c174; Ecp_ClientId=4171108204203358441; UM_distinctid=15fa39ba58f5d2-0bbc0ba0169156-31637c01-13c680-15fa39ba5905f1; SID_search=201087; ASP.NET_SessionId=glrrdk550e5gw0fsyobrsr45; CNZZDATA2643871=cnzz_eid%3D610954823-1510276064-null%26ntime%3D1510290496; CNZZDATA3636877=cnzz_eid%3D353975078-1510275934-null%26ntime%3D1510290549; SID_sug=111055; LID=WEEvREcwSlJHSldRa1FhcTdWZDhML1NwVjBUZzZHeXREdU5mcG40MVM4WT0=$9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw!!', } headers2 = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36' } # ------------------------------------------ for i in range(pagestart, pageend + 1): try: ## 得到一个代理 IP ip_list = get_ip_list(urlip, headers2) # 获得代理IP列表 proxies = get_random_ip(ip_list) # 获得随机的一个代理IP # 获得每一页里面文章的 urllist url_all = url + str(15 * (i - 1)) # 获得每一页的文章具体文章信息页面的链接 response = requests.get(url_all, headers=headers) # 获得网页源码 ,proxies=proxies # print(utf16_response.decode('utf-16')) file = response.text.encode(response.encoding).decode('utf-8') # 对网页信息进行转化成为可以正常现实的 UTF-8格式 r = etree.HTML(file) # 获取网页信息,并且解析 使用xpath urllist = r.xpath('//div[@]/h3/a[1]/@href') # 获得当前页所有文章的进入链接 # 获得每页urllist的文章信息,并且存到构建的表格中 get_data(urllist, headers, proxies) except: print('第' + str(i) + '页在爬取时候发生错误') wb.save('/Users/cici/Desktop/Smoking_CNKI.xlsx') # 最后保存搜集到的数据代码来源:
https://www.jianshu.com/p/9d27d541b137
强调
这里有视频教程,B站直达:
https://www.bilibili.com/video/av94574531/
如果遇到什么问题,可以自己先Search一下~感谢体谅


文章来源公众号:天黑请闭眼预言家请睁眼 -Python批量获取知网文章信息
已授权
代码亲测好用!
可以点个在看嘛















 1176
1176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









