





背景
由于在多处理器环境中某些资源的有限性,有时需要互斥访问(mutual exclusion),这时候就需要引入锁的概念,只有获取了锁的任务才能够对资源进行访问,由于多线程的核心是CPU的时间分片,所以同一时刻只能有一个任务获取到锁。
内核当发生访问资源冲突的时候,通常有两种处理方式:
- 一个是原地等待
- 一个是挂起当前进程,调度其他进程执行(睡眠)
自旋锁
Spinlock 是内核中提供的一种比较常见的锁机制,自旋锁是“原地等待”的方式解决资源冲突的。即,一个线程获取了一个自旋锁后,另外一个线程期望获取该自旋锁,获取不到,只能够原地“打转”(忙等待)。
由于自旋锁的这个忙等待的特性,注定了它使用场景上的限制 —— 自旋锁不应该被长时间的持有(消耗 CPU 资源)。
自旋锁的优点
自旋锁不会使线程状态发生切换,一直处于用户态,即线程一直都是active的;不会使线程进入阻塞状态,减少了不必要的上下文切换,执行速度快。
非自旋锁在获取不到锁的时候会进入阻塞状态,从而进入内核态,当获取到锁的时候需要从内核态恢复,需要线程上下文切换。(线程被阻塞后便进入内核(Linux)调度状态,这个会导致系统在用户态与内核态之间来回切换,严重影响锁的性能)。
自旋锁的使用
在linux kernel的实现中,经常会遇到这样的场景:共享数据被中断上下文和进程上下文访问,该如何保护呢?
如果只有进程上下文的访问,那么可以考虑使用semaphore或者mutex的锁机制,但是现在中断上下文也掺和进来,那些可以导致睡眠的lock就不能使用了,这时候,可以考虑使用spin lock。
在中断上下文,是不允许睡眠的,所以,这里需要的是一个不会导致睡眠的锁——spinlock。
换言之,中段上下文要用锁,首选 spinlock。
使用自旋锁,有两种方式定义一个锁:
动态的:
spinlock_t lock;spin_lock_init (&lock);静态的:
DEFINE_SPINLOCK(lock);使用步骤
spinlock的使用很简单:
- 我们要访问临界资源需要首先申请自旋锁;
- 获取不到锁就自旋,如果能获得锁就进入临界区;
- 当自旋锁释放后,自旋在这个锁的任务即可获得锁并进入临界区,退出临界区的任务必须释放自旋锁。
使用实例
static spinlock_t lock;static int flage = 1;spin_lock_init(&lock);static int hello_open (struct inode *inode, struct file *filep){ spin_lock(&lock); if(flage !=1) { spin_unlock(&lock); return -EBUSY; } flage =0; spin_unlock(&lock); return 0;}static int hello_release (struct inode *inode, struct file *filep){ flage = 1; return 0;}补充
中断上下文不能睡眠的原因是:
- 中断处理的时候,不应该发生进程切换,因为在中断context中,唯一能打断当前中断handler的只有更高优先级的中断,它不会被进程打断,如果在 中断context中休眠,则没有办法唤醒它,因为所有的wake_up_xxx都是针对某个进程而言的,而在中断context中,没有进程的概念,没 有一个task_struct(这点对于softirq和tasklet一样),因此真的休眠了,比如调用了会导致block的例程,内核几乎肯定会死。
- schedule()在切换进程时,保存当前的进程上下文(CPU寄存器的值、进程的状态以及堆栈中的内容),以便以后恢复此进程运行。中断发生后,内核会先保存当前被中断的进程上下文(在调用中断处理程序后恢复);
但在中断处理程序里,CPU寄存器的值肯定已经变化了吧(最重要的程序计数器PC、堆栈SP等),如果此时因为睡眠或阻塞操作调用了schedule(),则保存的进程上下文就不是当前的进程context了.所以不可以在中断处理程序中调用schedule()。
- 内核中schedule()函数本身在进来的时候判断是否处于中断上下文:
if(unlikely(in_interrupt())) BUG();因此,强行调用schedule()的结果就是内核BUG。
- 中断handler会使用被中断的进程内核堆栈,但不会对它有任何影响,因为handler使用完后会完全清除它使用的那部分堆栈,恢复被中断前的原貌。
- 处于中断context时候,内核是不可抢占的。因此,如果休眠,则内核一定挂起。
自旋锁的死锁
自旋锁不可递归,自己等待自己已经获取的锁,会导致死锁。
自旋锁可以在中断上下文中使用,但是试想一个场景:一个线程获取了一个锁,但是被中断处理程序打断,中断处理程序也获取了这个锁(但是之前已经被锁住了,无法获取到,只能自旋),中断无法退出,导致线程中后面释放锁的代码无法被执行,导致死锁。(如果确认中断中不会访问和线程中同一个锁,其实无所谓)。
一、考虑下面的场景(内核抢占场景):
(1)进程A在某个系统调用过程中访问了共享资源 R
(2)进程B在某个系统调用过程中也访问了共享资源 R
会不会造成冲突呢?
假设在A访问共享资源R的过程中发生了中断,中断唤醒了沉睡中的,优先级更高的B,在中断返回现场的时候,发生进程切换,B启动执行,并通过系统调用访问了R,如果没有锁保护,则会出现两个thread进入临界区,导致程序执行不正确。OK,我们加上spin lock看看如何:A在进入临界区之前获取了spin lock,同样的,在A访问共享资源R的过程中发生了中断,中断唤醒了沉睡中的,优先级更高的B,B在访问临界区之前仍然会试图获取spin lock,这时候由于A进程持有spin lock而导致B进程进入了永久的spin……怎么破?linux的kernel很简单,在A进程获取spin lock的时候,禁止本CPU上的抢占(上面的永久spin的场合仅仅在本CPU的进程抢占本CPU的当前进程这样的场景中发生)。如果A和B运行在不同的CPU上,那么情况会简单一些:A进程虽然持有spin lock而导致B进程进入spin状态,不过由于运行在不同的CPU上,A进程会持续执行并会很快释放spin lock,解除B进程的spin状态。
二、再考虑下面的场景(中断上下文场景):
- 运行在CPU0上的进程A在某个系统调用过程中访问了共享资源 R
- 运行在CPU1上的进程B在某个系统调用过程中也访问了共享资源 R
- 外设P的中断handler中也会访问共享资源 R
在这样的场景下,使用spin lock可以保护访问共享资源R的临界区吗?
我们假设CPU0上的进程A持有spin lock进入临界区,这时候,外设P发生了中断事件,并且调度到了CPU1上执行,看起来没有什么问题,执行在CPU1上的handler会稍微等待一会CPU0上的进程A,等它立刻临界区就会释放spin lock的,但是,如果外设P的中断事件被调度到了CPU0上执行会怎么样?CPU0上的进程A在持有spin lock的状态下被中断上下文抢占,而抢占它的CPU0上的handler在进入临界区之前仍然会试图获取spin lock,悲剧发生了,CPU0上的P外设的中断handler永远的进入spin状态,这时候,CPU1上的进程B也不可避免在试图持有spin lock的时候失败而导致进入spin状态。为了解决这样的问题,linux kernel采用了这样的办法:如果涉及到中断上下文的访问,spin lock需要和禁止本 CPU 上的中断联合使用。
三、再考虑下面的场景(底半部场景)
linux kernel中提供了丰富的bottom half的机制,虽然同属中断上下文,不过还是稍有不同。我们可以把上面的场景简单修改一下:外设P不是中断handler中访问共享资源R,而是在的bottom half中访问。使用spin lock+禁止本地中断当然是可以达到保护共享资源的效果,但是使用牛刀来杀鸡似乎有点小题大做,这时候disable bottom half就可以了。
四、中断上下文之间的竞争
同一种中断handler之间在uni core和multi core上都不会并行执行,这是linux kernel的特性。如果不同中断handler需要使用spin lock保护共享资源,对于新的内核(不区分fast handler和slow handler),所有handler都是关闭中断的,因此使用spin lock不需要关闭中断的配合。bottom half又分成softirq和tasklet,同一种softirq会在不同的CPU上并发执行,因此如果某个驱动中的softirq的handler中会访问某个全局变量,对该全局变量是需要使用spin lock保护的,不用配合disable CPU中断或者bottom half。tasklet更简单,因为同一种tasklet不会多个CPU上并发。
自旋锁的实现原理
数据结构
首先定义一个 spinlock_t 的数据类型,其本质上是一个整数值(对该数值的操作需要保证原子性),该数值表示spin lock是否可用。初始化的时候被设定为1。当thread想要持有锁的时候调用spin_lock函数,该函数将spin lock那个整数值减去1,然后进行判断,如果等于0,表示可以获取spin lock,如果是负数,则说明其他thread的持有该锁,本thread需要spin。
内核中的spinlock_t的数据类型定义如下:
typedef struct spinlock { struct raw_spinlock rlock; } spinlock_t;typedef struct raw_spinlock { arch_spinlock_t raw_lock;} raw_spinlock_t;通用(适用于各种arch)的spin lock使用spinlock_t这样的type name,各种arch定义自己的struct raw_spinlock。听起来不错的主意和命名方式,直到linux realtime tree(PREEMPT_RT)提出对spinlock的挑战。
spin lock的命名规范定义如下:
- spinlock,在rt linux(配置了PREEMPT_RT)的时候可能会被抢占(实际底层可能是使用支持PI(优先级翻转)的mutext)。
- raw_spinlock,即便是配置了PREEMPT_RT也要顽强的spin
- arch_spinlock,spin lock是和architecture相关的,
ARM 结构体系 arch_spin_lock 接口实现
加锁
同样的,这里也只是选择一个典型的API来分析,其他的大家可以自行学习。我们选择的是 arch_spin_lock,其ARM32的代码如下:
static inline void arch_spin_lock(arch_spinlock_t *lock){ unsigned long tmp; u32 newval; arch_spinlock_t lockval; prefetchw(&lock->slock);---------(0) __asm__ __volatile__("1: ldrex %0, [%3]"---------(1)" add %1, %0, %4" ----------(2)" strex %2, %1,[%3]"---------(3)" teq %2, #0"-------------(4)" bne 1b" : "=&r" (lockval), "=&r" (newval), "=&r" (tmp) : "r" (&lock->slock), "I" (1 <tickets.owner);----(7) } smp_mb();-----------(8)}(0)和preloading cache相关的操作,主要是为了性能考虑(1)lockval = lock->slock (如果lock->slock没有被其他处理器独占,则标记当前执行处理器对lock->slock地址的独占访问;否则不影响)(2)newval = lockval + (1 <slock] (如果当前执行处理器没有独占lock->slock地址的访问,不进行存储,返回1给temp;如果当前处理器已经独占lock->slock内存访问,则对内存进行写,返回0给temp,清除独占标记) lock->tickets.next = lock->tickets.next + 1(4)检查是否写入成功 lockval.tickets.next(5)初始化时lock->tickets.owner、lock->tickets.next都为0,假设第一次执行arch_spin_lock,lockval = *lock,lock->tickets.next++,lockval.tickets.next 等于 lockval.tickets.owner,获取到自旋锁;自旋锁未释放,第二次执行的时候,lock->tickets.owner = 0, lock->tickets.next = 1,拷贝到lockval后,lockval.tickets.next != lockval.tickets.owner,会执行wfe等待被自旋锁释放被唤醒,自旋锁释放时会执行 lock->tickets.owner++,lockval.tickets.owner重新赋值(6)暂时中断挂起执行。如果当前spin lock的状态是locked,那么调用wfe进入等待状态。更具体的细节请参考ARM WFI和WFE指令中的描述。(7)其他的CPU唤醒了本cpu的执行,说明owner发生了变化,该新的own赋给lockval,然后继续判断spin lock的状态,也就是回到step 5。(8)memory barrier的操作,具体可以参考memory barrier中的描述。释放锁
static inline void arch_spin_unlock(arch_spinlock_t *lock){ smp_mb(); lock->tickets.owner++; ---------------------- (0) dsb_sev(); ---------------------------------- (1)}- (0)lock->tickets.owner增加1,下一个被唤醒的处理器会检查该值是否与自己的lockval.tickets.next相等,lock->tickets.owner代表可以获取的自旋锁的处理器,lock->tickets.next你一个可以获取的自旋锁的owner;处理器获取自旋锁时,会先读取lock->tickets.next用于与lock->tickets.owner比较并且对lock->tickets.next加1,下一个处理器获取到的lock->tickets.next就与当前处理器不一致了,两个处理器都与lock->tickets.owner比较,肯定只有一个处理器会相等,自旋锁释放时时对lock->tickets.owner加1计算,因此,先申请自旋锁多处理器lock->tickets.next值更新,自然先获取到自旋锁
- (1)执行sev指令,唤醒wfe等待的处理器
自旋锁导致死锁实例
死锁的2种情况
1)拥有自旋锁的进程A在内核态阻塞了,内核调度B进程,碰巧B进程也要获得自旋锁,此时B只能自旋转。而此时抢占已经关闭,不会调度A进程了,B永远自旋,产生死锁。
2)进程A拥有自旋锁,中断到来,CPU执行中断函数,中断处理函数,中断处理函数需要获得自旋锁,访问共享资源,此时无法获得锁,只能自旋,产生死锁。
如何避免死锁
- 如果中断处理函数中也要获得自旋锁,那么驱动程序需要在拥有自旋锁时禁止中断;
- 自旋锁必须在可能的最短时间内拥有;
- 避免某个获得锁的函数调用其他同样试图获取这个锁的函数,否则代码就会死锁;不论是信号量还是自旋锁,都不允许锁拥有者第二次获得这个锁,如果试图这么做,系统将挂起;
- 锁的顺序规则 按同样的顺序获得锁; 如果必须获得一个局部锁和一个属于内核更中心位置的锁,则应该首先获取自己的局部锁 ; 如果我们拥有信号量和自旋锁的组合,则必须首先获得信号量;在拥有自旋锁时调用down(可导致休眠)是个严重的错误的。
死锁举例
因为自旋锁持有时间非常短,没有直观的现象,下面举一个会导致死锁的实例。
运行条件
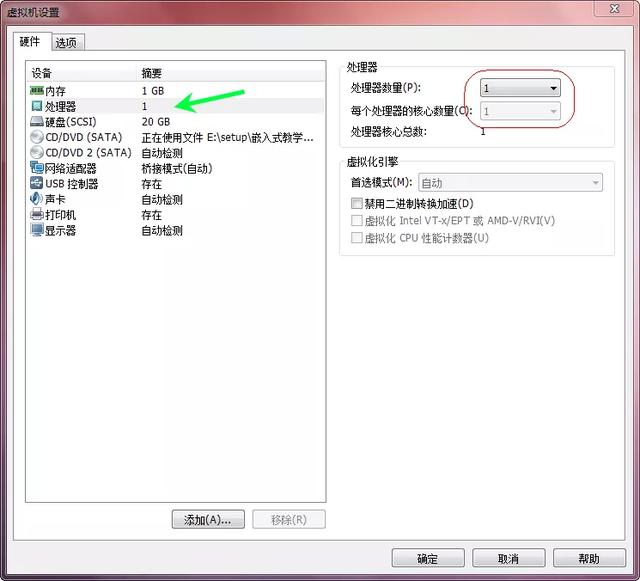
- 虚拟机:vmware
- OS :Ubuntu 14
- 配置 :将虚拟机的处理个数设置为1,否则不会死锁
原理
针对单CPU,拥有自旋锁的任务不应该调度会引起休眠的函数,否则会导致死锁。
步骤:
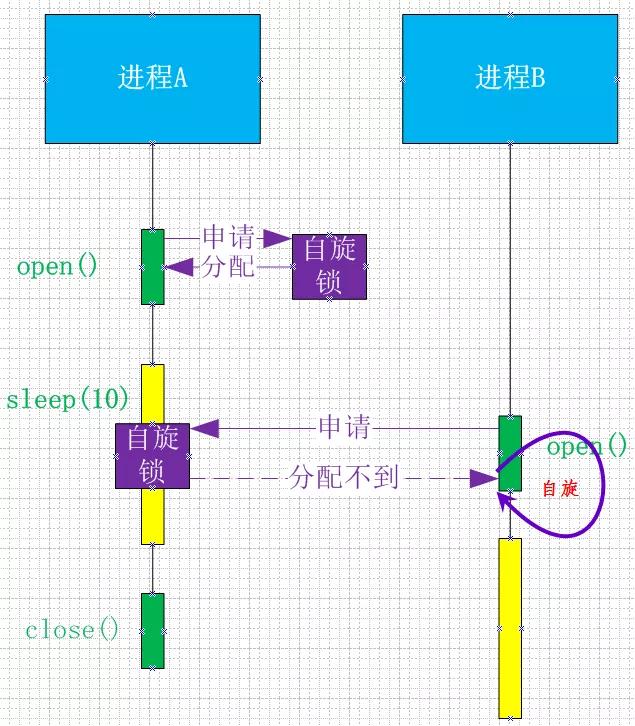
- 进程A在open()字符设备后,对应的内核函数会申请自旋锁,此时自旋锁空闲,申请到自旋锁,进程A随即进入执行sleep()函数进入休眠;
- 在进程A 处于sleep期间,自旋锁一直属于进程A所有;
- 运行进程B,进程B执行open函数,对应的内核函数也会申请自旋锁,此时自旋锁归进程A所有,所以进程B进入自旋状态;
- 因为此时抢占已经关闭,系统死锁。
驱动代码如下:
#include #include #include #include #include #include #include static int major = 250;static int minor = 0;static dev_t devno;static struct cdev cdev;static struct class *cls;static struct device *test_device;static spinlock_t lock;static int flage = 1;#define DEAD 1static int hello_open (struct inode *inode, struct file *filep){ spin_lock(&lock); if(flage !=1) { spin_unlock(&lock); return -EBUSY; } flage =0; #if DEAD #elif spin_unlock(&lock); #endif return 0;}static int hello_release (struct inode *inode, struct file *filep){ flage = 1; #if DEAD spin_unlock(&lock); #endif return 0;}static struct file_operations hello_ops ={ .open = hello_open, .release = hello_release,};static int hello_init(void){ int result; int error; printk("hello_init "); result = register_chrdev( major, "hello", &hello_ops); if(result 测试程序如下:
#include #include #include #include main(){ int fd; fd = open("/dev/test",O_RDWR); if(fd<0) { perror("open fail "); return; } sleep(20); close(fd); printf("open ok ");}测试步骤:
- 编译加载内核
makeinsmod hello.ko- 运行进程A
gcc test.c -o a./a - 打开一个新的终端,运行进程B
gcc test.c -o b./b注意,一定要在进程A没有退出的时候运行进程B。














 8037
8037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









