





本代码是讲述如果通过IP地址查出相应的 位置信息,在百度查询到https://www.ip.cn/是IP地址查询位置的网站,故对此网站的源代码进行爬取,示例代码如下:
#1、首先导入相应的库import requests #导入爬虫库requestsimport re #导入正则表达式的库#2、对网站进行get请求def gethtml(kw): #定义获取源代码函数gethtml,参数为kw url="https://www.ip.cn/?ip="+kw #设置url地址为地址栏前面部分+参数kw headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36"} # 设置网页请求头 response = requests.get(url, headers=headers) ##伪装浏览器对url进行get请求 response.encoding=response.apparent_encoding #根据网页内容进行解析编码并赋值给response.encoding html=response.text #将响应的内容赋值给html pattern1=re.compile(r".+") #设置正则表达式匹配规则为code标签所有的数据 result1=re.findall(pattern1,html) #在html源代码中查找所有符合匹配规则pattern1的源代码,并赋值给result1 print(result1) #打印查找到的结果,即IP和地理位置信息if __name__ == '__main__': gethtml("120.31.52.56") #调用gethtml函数,参数为IP地址120.31.52.56
运行结果如下:
['120.31.52.56
所在地理位置:广东省中山市 睿江科技
GeoIP: ']
图片示例如下:
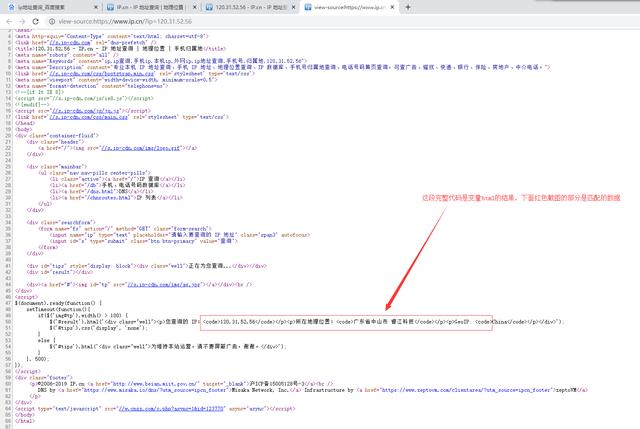
爬取的完整源代码图
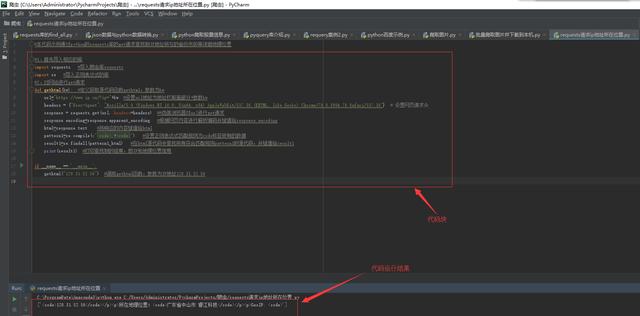
代码块和代码运行结果图














 199
199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









