






多元分析,又称多变量分析,是用于研究多个变量数据之间的关系,包括了多重回归分析、判别分析、聚类分析、主成分分析、对应分析、因子分析、典型相关分析等。本文主要介绍其中两种常见的分析方法:聚类分析和权重分析。
1 聚类分析
聚类分析,通俗地讲,就是通过计算相关指标,将样本分为几类,使得类与类之间的差异很大,同类样本之间的差异尽可能地小。
(1)聚类分析种类
聚类分析的分类方法有很多,按功能划分可以分为两类——样本聚类(Q型聚类)和变量聚类(R型聚类)。问卷研究中,样本聚类使用频率远高于变量聚类。
按照SPSS软件的功能进行划分,聚类分析分为三类,分别是两步聚类、K-均值聚类和系统聚类(分层聚类)。三种聚类方法各有特点,具体情况如下:

(2)操作步骤
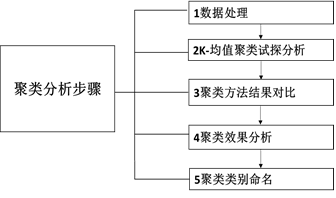
Step1:如果样本数据度量单位不统一,比如有的题项是以七级量表,而有的题项为五级题项。此时应该进行数据处理,即数据标准化处理。
Step2:由于K-均值聚类法的优点在于速度非常快,因此可以提前进行快速分析,计算不同类别样本数量进行简单判断聚类效果。
Step3:对比另外两种分析方法时的聚类类别数量情况,综合判断找出最优聚类结果。
Step4:分析聚类结果结合不同类别样本特征情况,对聚类类别进行有效命名。
Step5:聚类类别命名。
具体针对聚类分析,上述步骤可能并不完全适用,如果聚类变量中有分类数据,则不能使用K-均值聚类分析。
(3)指标解读
SPSSAU默认聚类分析使用K-均值聚类方法进行,以下说明均为K-means聚类分析方法
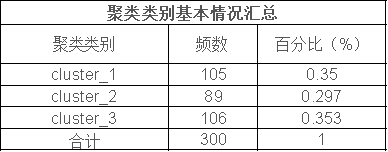
此表主要用于描述聚类分析的基本情况,描述聚类得出类别情况,每个类别人群数量和比例情况等。例如从上表可以看出:聚类得到3类群体,此3类群体的占比分别是35.0%, 29.7%, 35.3%。整体来看, 3类人群分布较为均匀,整体说明聚类效果较好。
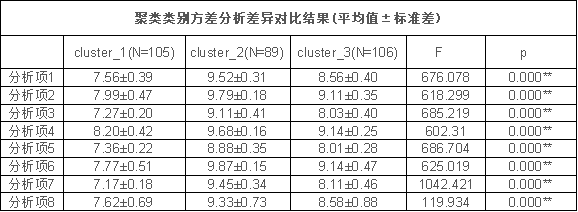
此表主要通过方差分析对比每个类别下各题项的特征,探索各个类别的差异,最终可结合各个类别特征进行类别命名。例如从上表可知:聚类类别群体对于所有研究项均呈现出显著性(P<0.05),意味着聚类分析得到的3类群体,在研究项上的特征具有明显的差异性。
2 权重
权重分析,通过计算各个指标或者题项的权重得分,研究各因素或指标相对与整个体系或某一指标的重要程度。
(1)分类
量表类问卷权重研究方法通常情况下可以分为三类:主观赋权法、客观赋权法、组合赋权法。
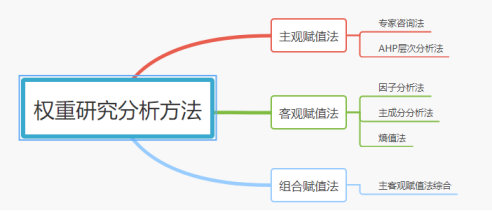
主观赋权法就是根据决策者(专家)主观上对各属性的重视程度来确定属性权重的方法。
客观赋权法是根据原始数据之间的关系通过一定的数学方法来确定权重,判断结果不依赖于人的主观判断,有较强的数学理论依据。
组合赋值法是在主观赋权法(通常是AHP层次分析法)和客观赋权法(通常是因子分析或者熵值法)的权重结果基础上,综合计算出最终权重体系的方法。
用于研究权重的分析方法有很多,这里着重说明几种较为常用的方法,分别为主成分分析、熵值法。
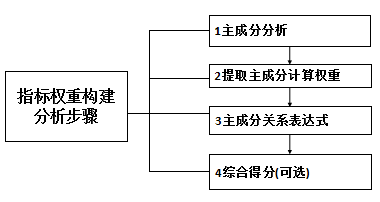
(2)主成分分析
分析步骤
指标解读


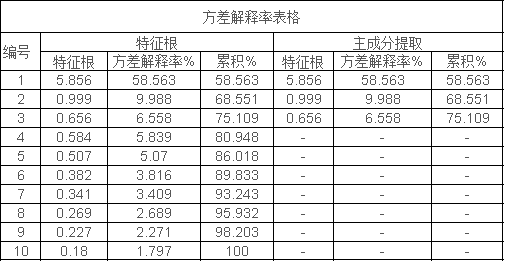
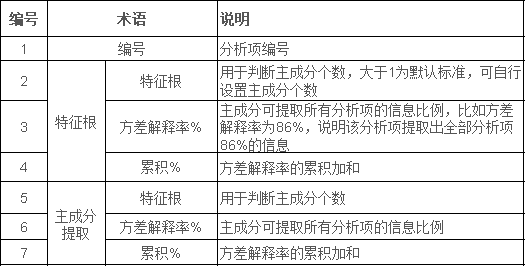
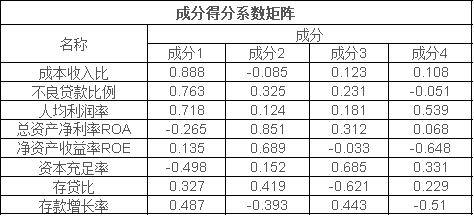
此表用于基三每个成分得分,计算得分后,结合方差解释率,最终即得到综合得分。
(3)熵值法
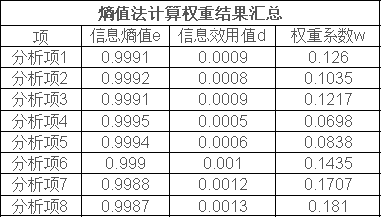
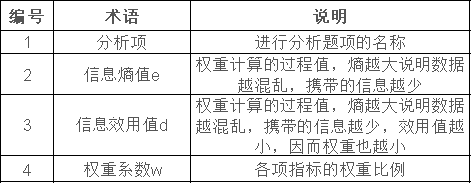
其他说明:在进行熵值法之前,如果数据方向不一致时,需要进行提前数据处理,通常为正向化或者逆向化两种处理(统称为数据归一化处理)。
以上提到分析方法都可在SPSSAU中进行分析,详细说明可查看SPSSAU官网,以及可使用SPSSAU上面的案例数据,进行实际的操作分析。
相关资料
在线SPSS-SPSSAU-主成分分析
在线SPSS-SPSSAU-聚类分析
在线SPSS-SPSSAU-AHP层次分析法














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









