





自Julia 1.0 推出以来获得很多机器学习爱好者的青睐。Julia 官方也是不断的迭代,目前版本已经进入了Julia 1.5+ 时代。很多人喜欢Julia语言,除了语法简洁、上手快、比Python更适合做科学计算之外,还因为Julia的性能强悍。

Julia数据分析
读取数据
数据分析最重要的就是高效的读取数据。本身对性能的要求就很高,这里以读取CSV文件来测试性能。众所周知,CSV文件目前运用广泛。除了多样的数据类型存储之外、共享表格数据都是我们常用的操作。
在数据分析中,尤其是数据量大的CSV,对性能、稳定的要求都非常高。不同的语言、库等对读取CSV的支持,可谓是八仙过海各显神通。这里以三门主流的数据分析语言为例,分别是:
- R语言 -> fread函数
- Python语言 -> Pandas库 -> read_csv 函数
- Julia语言 -> CSV.jl包

CSV数据表
这仨都是各自语言的最佳选择,都支持多种数据类型的数据导入,包括带有缺失值的数据类型导入。区别在于:
- 只有R 和 Julia 支持多线程。
- 而 Pandas 只支持单线程导入。
- Julia 单核执行速度比Pandas 高出1.5到5倍。
- Julia 多核执行速度比Pandas 高出20倍以上。
- Julia 比同样支持多线程的R 高出不止10倍,数据集越多,差异越明显。
用于基准测试的工具分别如下:
- Julia 的BenchmarkTools.jl性能测试框架
- R的microbenchmark包
- Python 的timeit模块。
同构数据集
同构数据集也就是在所有列中相同种类的数据集。这次选取的数据集,除了股价数据集以外,都选自于基准站点。 以导入数据的时间作为性能指标,线程数从1开始,递增至20。由于Pandas 不支持多线程,就以单线程为记录。每种数据集,性能测试表现分别如下:
(一)浮点型数据集
该数据集是浮点型数据,该表为100万行、20列。执行结果如下,可以看到有3个关键点:
- R 导入这个文件用时232毫秒,单线程比 Julia 快1.6倍。
- 随着线程数递增,Julia 反超R,超 R的2倍以上。
- 单线程状态下 Julia 超 Python 1.5倍,多线程状态下 Julia 比 Python 快11倍。
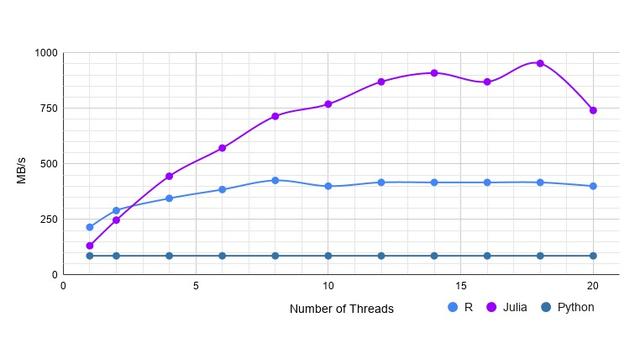
浮点数据集
(二)字符串数据集
该数据集为字符串类型,同样100万行、20列。直接看图说话:
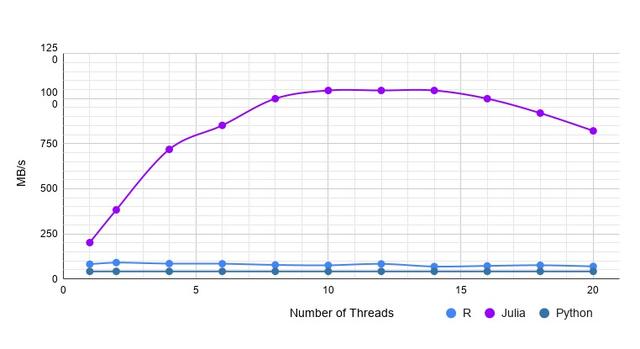
字符串数据集
(三)字符串数据集(带缺失值)
该数据集同上,也是字符串类型。不一样的是每一列都存在缺失值。执行结果如下图:
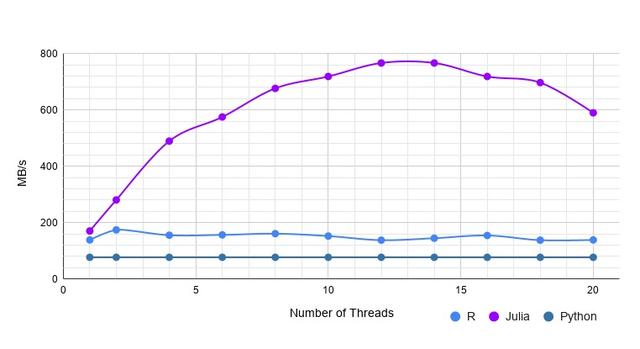
含缺失值字符串数据集
(四)苹果股价数据集
该数据集是苹果股票的数据,总共5列,包含开盘价、收盘价,最高价、最低价等四列浮点值数据,还有一列是日期。总共 5000万条数据,有2.5GB。这组数据的执行结果,Julia 一马当先,高性能的表现远超Python和R,如下图:
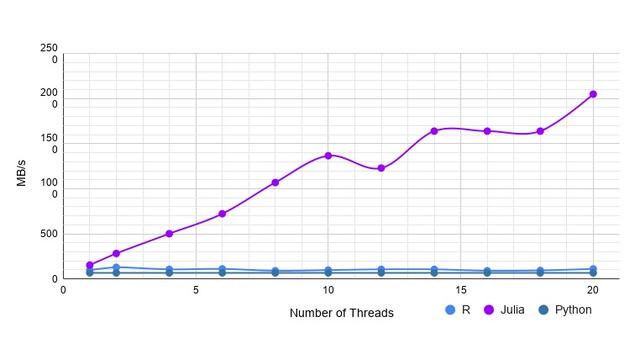
苹果股价数据集
玩儿量化交易的朋友对这个该不陌生了,单从性能上Julia非常值得玩儿量化,后面我也会基于Julia 出一套量化系列,有兴趣的朋友可以关注我哟~
(五)混合型数据集
该数据集包含 1W条数据,200列。数据类型包括字符串、浮点、日期、并且有缺失值。结果如下:
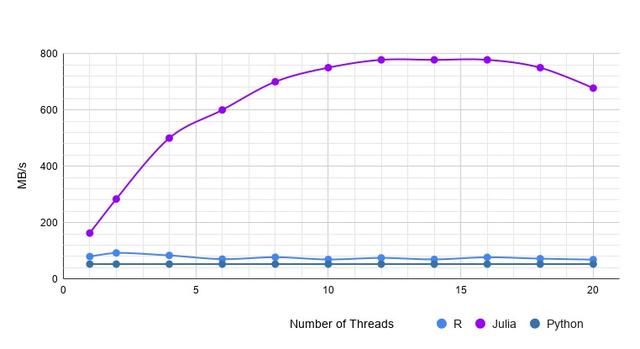
混合型数据集
(六)抵押风险数据集
该数据集来自Kaggle平台,是抵押风险数据集,共35.6W行,2190列。包含字符串、整型、浮点、缺失值等各种类型。Pandas读取这个数据集花了119秒之久。结果如下:
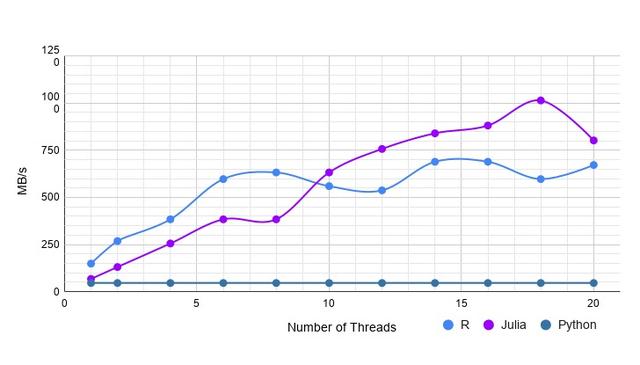
抵押风险数据集
(七)大数据集
该数据集 1000条数据,2W列,结果如下:
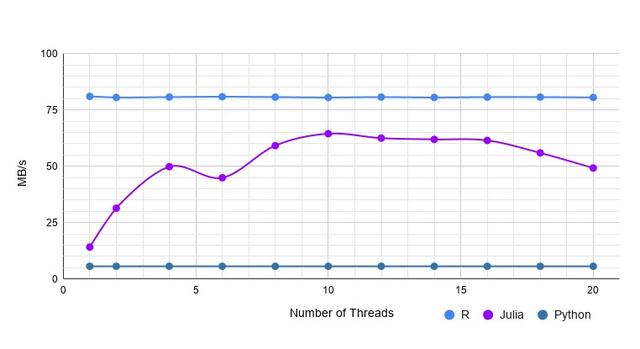
大数据集
(八)房利美收购数据集
房利美 Fannie Mae (FNMA),是联邦国民抵押贷款协会。成立于1938年,是最大的“美国政府赞助企业”,从事金融业务,用以扩大资金在二级房屋消费市场上流动的资金的专门机构。该数据集来自房利美网站,包含:400W条数据,25列。数据类型包括:整型、字符串、浮点、缺失值。执行结果如下:
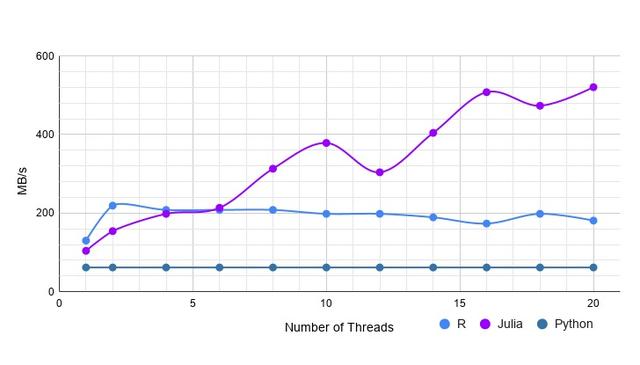
房利美收购数据集
总结
根据上面八组数据集性能比拼结果,可以很明显的看出Julia 在性能上一枝独秀,远超Python、R,如下图所示:
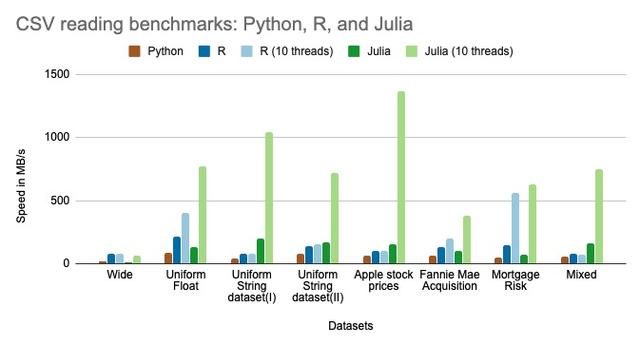
性能比拼结果
目前,已经发布了Julia 1.5 版,我们的AI团队在新项目中已经完全用Julia 将Python替代,性能的确很强悍。
彩蛋
结尾彩蛋给大家推荐两个Julia 的机器学习框架,也是我们目前在用的,后续会分享相关文章。如下:
- 机器学习库 Flux.jl,这是一个纯Julia栈开发的库,功能强大、十分灵活。且在Julia原生GPU和AD支持之上提供轻量级抽象。
- MLJ是一个用纯Julia编写的开源机器学习工具箱,来自于艾伦·图灵研究所。MLJ旨在成为一个灵活的框架,用于组合和调整机器学习模型。团队计划对框架增强,包括Flux.jl深度学习模型的集成,以及使用自动微分的连续超参数的梯度下降调整。
除了Julia,我会用终端来玩一些有趣的AI 案例,例如:
- Angular + TensorFlow
- Taro小程序 + 人脸识别
- Vue + TensorFlow
另外,再分享一篇Julia文章,基于Julia对伦敦天气进行数据分析
对AI感兴趣的小伙伴可以关注我哟~
参考:https://towardsdatascience.com/the-great-csv-showdown-julia-vs-python-vs-r-aa77376fb96
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









